Introduction to Apache Airflow®: A Technical Overview for Beginners
Introduction to Apache Airflow®: A Technical Overview for Beginners
Apache Airflow® is an open source tool for programmatically authoring, scheduling, and monitoring data pipelines. Every month, millions of new and returning users download Airflow and it has a large, active open source community. The core principle of Airflow is to define data pipelines as code, allowing for dynamic and scalable workflows.
This guide offers an introduction to Apache Airflow and its core concepts. You’ll learn about:
- Why you should use Airflow.
- Common use cases for Airflow.
- How to run Airflow.
- Important Airflow concepts.
- Where to find resources to learn more about Airflow.
Other ways to learn
There are multiple resources for learning about this topic. See also:
Hands-on tutorial: Get started with Apache Airflow.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Basic Python. See the Python Documentation.
Why use Airflow
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. It is especially useful for creating and orchestrating complex data pipelines.
Data orchestration sits at the heart of any modern data stack and provides elaborate automation of data pipelines. With orchestration, actions in your data pipeline become aware of each other and your data team has a central location to monitor, edit, and troubleshoot their workflows.
One of the core tenets of Airflow that sets it apart from other data orchestration tools is defining data pipelines as code. Modern data teams seek to define their workflows in code to:
- Manage workflows with their existing change-control and version-control tooling.
- Bulk-create/update workflows too numerous, large, or dynamic to manage from a GUI.
- Define re-usable, parameterizable workflow sections.
Airflow provides many additional benefits, including:
- Tool agnosticism: Airflow can connect to any application in your data ecosystem that allows connections through an API. Prebuilt operators exist to connect to many common data tools.
- High extensibility: Since Airflow pipelines are written in Python, you can build on top of the existing codebase and extend the functionality of Airflow to meet your needs. Anything you can do in Python, you can do in Airflow. Support to define tasks in languages other than Python is planned for 3.0+.
- Infinite scalability: Given enough computing power, you can orchestrate as many processes as you need, no matter the complexity of your pipelines.
- Dynamic data pipelines: Airflow offers the ability to create dynamic tasks to adjust your workflows based on the data you are processing at runtime.
- Vibrant OSS community: With millions of users and thousands of contributors, Airflow is here to stay and grow. Join the Airflow Slack to become part of the community.
- Observability: The Airflow UI provides an immediate overview of all your data pipelines and can provide the source of truth for workflows in your whole data ecosystem.
Airflow use cases
Many data professionals at companies of all sizes and types use Airflow. Data engineers, data scientists, ML engineers, and data analysts all need to perform actions on data in a complex web of dependencies. With Airflow, you can orchestrate these actions and dependencies in a single platform, no matter which tools you are using and how complex your pipelines are.

Some common use cases of Airflow include:
- ETL/ELT: 86% of Airflow users use it for Extract-Transform-Load (ETL) and Extract-Load-Transfrom (ELT) patterns. Often, these pipelines support critical operational processes. See Orchestrate dbt Core jobs with Airflow and Cosmos for an example use case.
- Business operations: 58% of Airflow users have used Airflow to orchestrate data supporting their business directly, creating data-powered applications and products, often in combination with MLOps pipelines. For an example use case, watch The Laurel Algorithm: MLOps, AI, and Airflow for Perfect Timekeeping webinar.
- MLOps and GenAI: 23% of Airflow users are already orchestrating Machine Learning Operations (MLOps) with Apache Airflow and 9% use Airflow specifically for GenAI use cases. An overview of best practices when using Airflow for MLOps can be found in Best practices for orchestrating MLOps pipelines with Airflow. See Use Cohere and OpenSearch to analyze customer feedback in an MLOps pipeline for a complex use case involving advanced ML tools.
- Managing infrastructure: Airflow can be used to spin up and tear down infrastructure. For example, to create and delete temporary tables in a database or spin up and down a Spark cluster. This type of use case has been implemented by 18% of Airflow users. The Airflow setup and teardown guide shows how to use the most relevant feature for this use case.
Of course, these are just a few examples, you can orchestrate almost any kind of batch workflows with Airflow.
Run Airflow
There are many ways to run Airflow, some of which are easier than others. Astronomer recommends:
- Using the open-source Astro CLI to run Airflow locally. The Astro CLI is the easiest way to create a local Airflow instance running in containers and is free to use for everyone.
- Using Astro to run Airflow in production. Astro is a fully-managed SaaS application for data orchestration that helps teams write and run data pipelines with Apache Airflow at any level of scale. A free trial is available.
All Airflow installations include the mandatory Airflow components as part of their infrastructure: the api-server, scheduler, dag-processor, and metadata database. See Airflow components for more information.
Airflow concepts
To navigate Airflow resources, it is helpful to have a general understanding of the following Airflow concepts.
Pipeline basics
- DAG: Directed Acyclic Graph. An Airflow DAG is a workflow defined as a graph, where all dependencies between nodes are directed and nodes don’t self-reference, meaning there are no circular dependencies. For more information on Airflow DAGs, see Introduction to Airflow DAGs.
- DAG run: The execution of a DAG at a specific point in time. A DAG run can be one of four different types:
scheduled,manual,dataset_triggeredorbackfill. - Task: A step in a DAG describing a single unit of work.
- Task instance: The execution of a task at a specific point in time.
- Dynamic task: An Airflow task that serves as a blueprint for a variable number of dynamically mapped tasks created at runtime. For more information, see Dynamic tasks.
- Asset: An asset is a representation inside of Airflow of a real or abstract object that is created by a task. Assets can be files, tables, or not tied to a data object at all. For more information, see Assets and data-aware scheduling in Airflow.
The following screenshot shows a side by side comparison of the grid and graph of a simple DAG, called example_astronauts, with two tasks, get_astronauts and print_astronaut_craft. The get_astronauts task is a regular task, while the print_astronaut_craft task is a dynamic task. The grid view of the Airflow UI shows individual DAG runs and task instances, while the graph displays the structure of the DAG. You can learn more about the Airflow UI in An introduction to the Airflow UI.
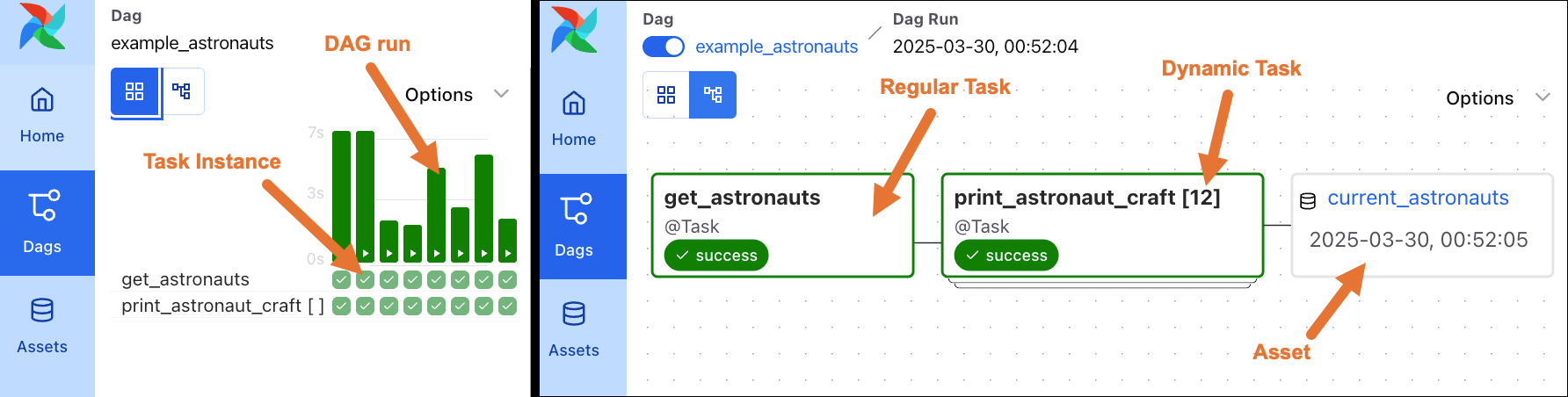
Click to view the full DAG code used for the screenshot
It is a core best practice to keep tasks as atomic as possible, meaning that each task performs a single action. Additionally, tasks are idempotent, which means they produce the same output every time they are run with the same input. See DAG writing best practices in Apache Airflow.
Write pipelines
There are two different ways to define pipelines in Airflow:
- Task-oriented approach: In the task-oriented approach, you define a DAG, fill it with tasks and define their dependencies. The mindset behind this approach is to think about the actions that need to be performed.
- Asset-oriented approach: Airflow 3.0 added the possibility to define DAGs in a more data-centric way. In the asset-oriented approach you define the asset (real or abstract) that you want to create directly and define dependencies between the assets. The mindset behind this approach is to think about the assets that need to be created.
Task-oriented approach
Airflow tasks are most commonly defined in Python code. You can define tasks using:
- Decorators (
@task): The TaskFlow API allows you to define tasks by using a set of decorators that wrap Python functions. This is the easiest way to create tasks from existing Python scripts. Each call to a decorated function becomes one task in your DAG. - Operators (
XYZOperator): Operators are classes abstracting over Python code designed to perform a specific action. You can instantiate an operator by providing the necessary parameters to the class. Each instantiated operator becomes one task in your DAG.
There are a couple of special types of operators that are worth mentioning:
- Sensors: Sensors are Operators that keep running until a certain condition is fulfilled. For example, the HttpSensor waits for an HTTP request object to fulfill a user defined set of criteria.
- Deferrable Operators: Deferrable Operators use the Python asyncio library to run tasks asynchronously. For example, the DateTimeSensorAsync waits asynchronously for a specific date and time to occur. Note that your Airflow environment needs to run a triggerer component to use deferrable operators.
Some commonly used building blocks, like the BashOperator, the @task decorator, or the PythonOperator, are part of core Airflow and automatically installed in all Airflow instances. Additionally, many operators are maintained separately to Airflow in Airflow provider packages, which group modules interacting with a specific service into a package.
You can browse all available operators and find detailed information about their parameters in the Airflow Registry. For many common data tools, there are integration tutorials available, showing a simple implementation of the provider package.
Asset-oriented approach
To define pipelines with using the asset-oriented approach, you can use the @asset decorator. See Assets and data-aware scheduling in Airflow for more information.
Additional concepts
While there is much more to Airflow than just DAGs and tasks, here are a few additional concepts and features that you are likely to encounter:
- Airflow scheduling: Airflow offers a variety of ways to schedule your DAGs. For more information, see DAG scheduling and timetables in Airflow.
- Airflow connections: Airflow connections offer a way to store credentials and other connection information for external systems and reference them in your DAGs. For more information, see Manage connections in Apache Airflow.
- Airflow variables: Airflow variables are key-value pairs that can be used to store information in your Airflow environment. For more information, see Use Airflow variables.
- XComs: XCom is short for cross-communication, you can use XCom to pass information between your Airflow tasks. For more information, see Passing data between tasks.
- Airflow REST API: The Airflow REST API allows you to interact with Airflow programmatically.
Resources
- Astronomer Webinars: Live deep dives into Airflow and Astronomer topics, all previous webinars are available to watch on-demand.
- Astronomer Academy: In depth video courses on Airflow and Astronomer topics.
- Official Airflow Documentation: The official documentation for Apache Airflow.
- Airflow GitHub: The official GitHub repository for Apache Airflow.
- Airflow Slack: The official Airflow Slack workspace, the best place to ask your Airflow questions!
Next steps
Now that you have a basic understanding of Apache Airflow, you are ready to write your first DAG by following the Get started with Apache Airflow tutorial.