Use MLflow with Apache Airflow
The MLflow Airflow provider has been deprecated and is no longer maintained. This tutorial was kept for reference purposes only.
MLflow is a popular tool for tracking and managing machine learning models. It can be used together with Airflow for ML orchestration (MLOx), leveraging both tools for what they do best. In this tutorial, you’ll learn about three different ways you can use MLflow with Airflow.
Three ways to use MLflow with Airflow
The DAG in this tutorial shows three different ways Airflow can interact with MLflow:
- Use an MLflow operator from the MLflow Airflow provider. The MLflow provider contains several operators that abstract over common actions you might want to perform in MLflow, such as creating a deployment with the CreateDeploymentOperator or running predictions from an existing model with the ModelLoadAndPredictOperator.
- Use an MLflow hook from the MLflow Airflow provider. The MLflow provider contains several Airflow hooks that allow you to connect to MLflow using credentials stored in an Airflow connection. You can use these hooks if you need to perform actions in MLflow for which no dedicated operator exists. You can also use these hooks to create your own custom operators.
- Use the MLflow Python package directly in a @task decorated task. The MLflow Python package contains functionality like tracking metrics and artifacts with
mlflow.sklearn.autolog. You can use this package to write custom Airflow tasks for ML-related actions like feature engineering.
Time to complete
This tutorial takes approximately 30 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of MLflow. See MLflow Concepts.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- Airflow operators. See Operators 101.
- Airflow hooks. See Hooks 101.
- Airflow connections. See Managing your Connections in Apache Airflow.
Prerequisites
- The Astro CLI.
- An MLflow instance. This tutorial uses a local instance.
- An object storage connected to your MLflow instance. This tutorial uses MinIO.
Step 1: Configure your Astro project
-
Create a new Astro project:
-
Add the following packages to your
packages.txtfile: -
Add the following packages to your
requirements.txtfile:
Step 2: Configure your Airflow connection
To connect Airflow to your MLflow instance, you need to create a connection in Airflow.
-
Run
astro dev startin your Astro project to start up Airflow and open the Airflow UI atlocalhost:8080. -
In the Airflow UI, go to Admin -> Connections and click +.
-
Create a new connection named
mlflow_defaultand choose theHTTPconnection type. Enter the following values to create a connection to a local MLflow instance:- Connection ID:
mlflow_default - Connection Type:
HTTP - Host:
http://host.docker.internal - Port:
5000
- Connection ID:
If you are using a remote MLflow instance, enter your MLflow instance URL as the Host and your username and password as the Login and Password in the connection. If you are running your MLflow instance via Databricks, enter your Databricks URL as the Host, enter token as the Login and your Databricks personal access token as the Password.
When you test the connection from the Airflow UI, please note that the Test button might return a 405 error message even if your credentials are correct.
Step 3: Create your DAG
-
In your
dagsfolder, create a file calledmlflow_tutorial_dag.py. -
Copy the following code into the file. Make sure to provide the name of a bucket in your object storage that is connected to your MLflow instance to the
ARTIFACT_BUCKETvariable.This DAG consists of three tasks, each showing a different way to use MLflow with Airflow.
- The
create_experimenttask creates a new experiment in MLflow by using the MLflowClientHook in a TaskFlow API task. The MLflowClientHook is one of several hooks in the MLflow provider that contains abstractions over calls to the MLflow API. - The
scale_featurestask uses the mlflow package in a Python decorated task with scikit-learn to log information about the scaler to MLflow. This functionality is not included in any modules of the MLflow provider, so a custom Python function is the best way to implement this task. - The
create_registered_modeltask uses the CreateRegisteredModelOperator to register a new model in your MLflow instance.
- The
Step 4: Run your DAG
-
In the Airflow UI run the
mlflow_tutorial_dagDAG by clicking the play button.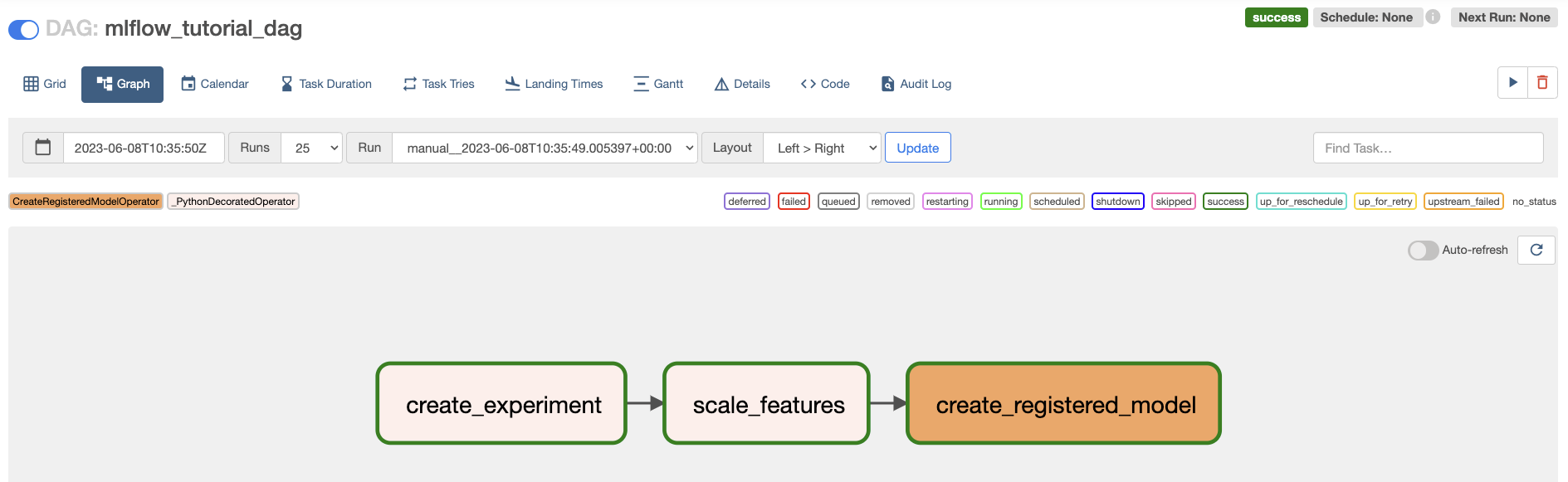
-
Open the MLflow UI (if you are running locally at
localhost:5000) to see the data recorded by each task in your DAG.The
create_experimenttask created theHousingexperiments, where yourScalerrun from thescale_featurestask was recorded.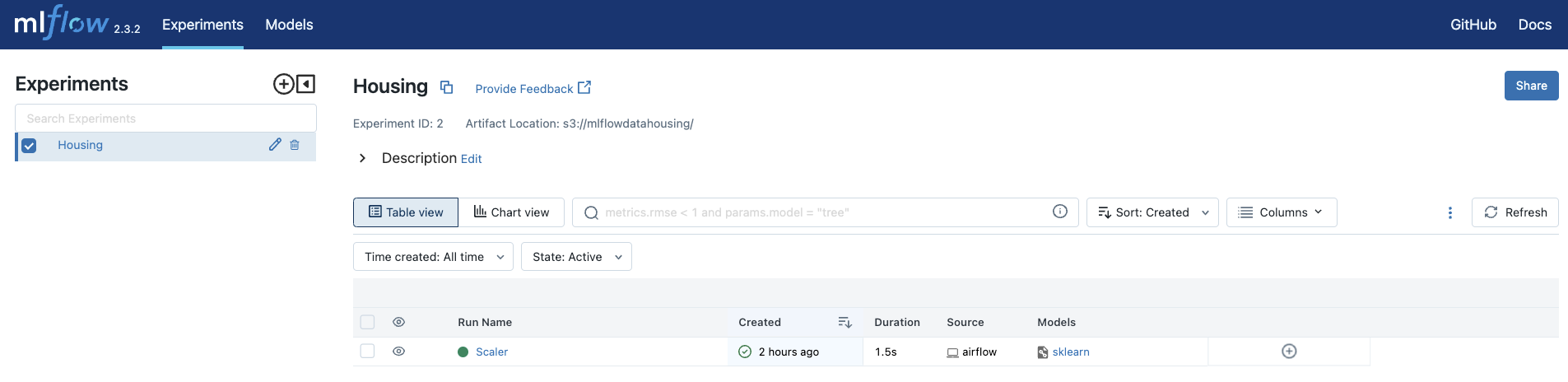
The
create_registered_modeltask created a registered model with two tags.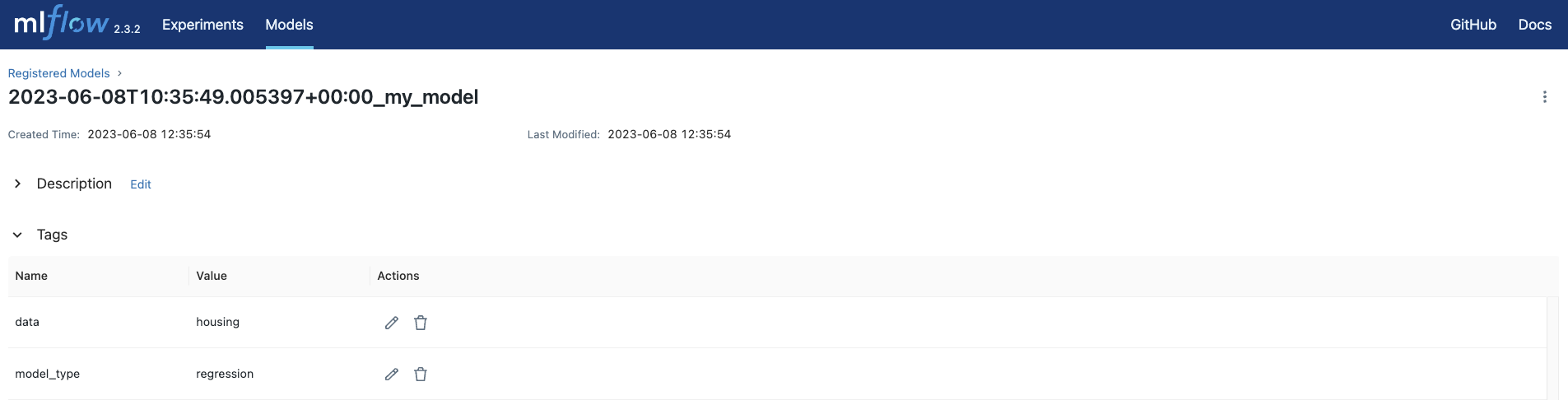
-
Open your object storage (if you are using a local MinIO instance at
localhost:9001) to see your MLflow artifacts.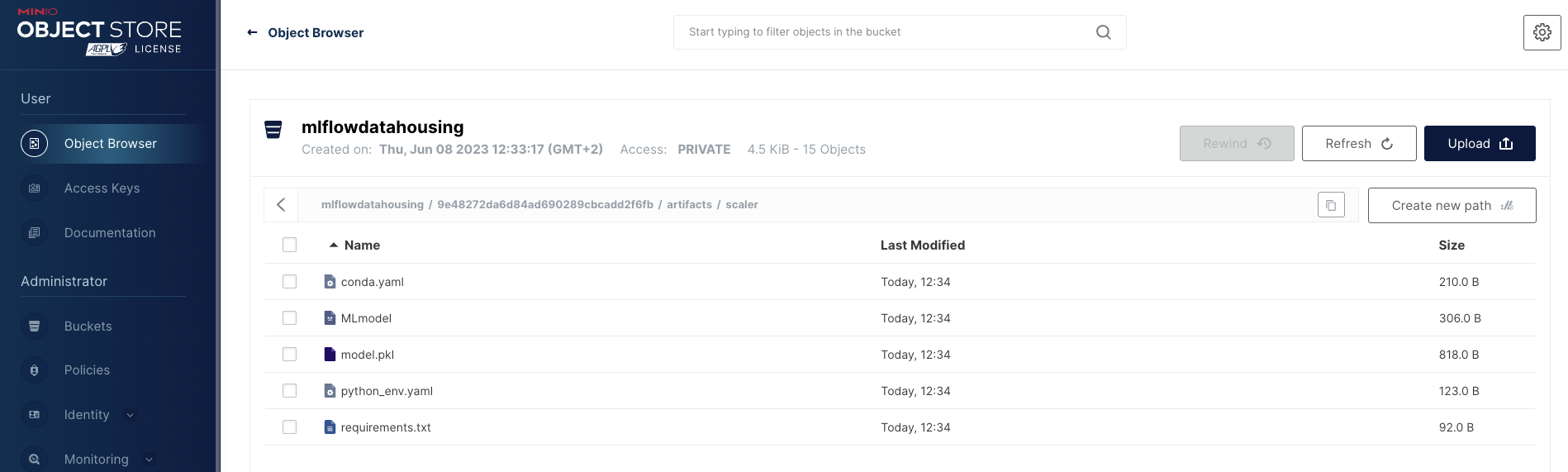
Conclusion
Congratulations! You used MLflow and Airflow together in three different ways. Learn more about other operators and hooks in the MLflow Airflow provider in the official GitHub repository.