Orchestrate OpenSearch operations with Apache Airflow
This page hasn’t yet been updated for Airflow 3. The concepts shown are relevant, but some code may need to be updated. If you run any examples, take care to update import statements and watch for any other breaking changes.
OpenSearch is an open source distributed search and analytics engine based on Apache Lucene. It offers advanced search capabilities on large bodies of text alongside powerful machine learning plugins. The OpenSearch Airflow provider offers modules to easily integrate OpenSearch with Airflow.
In this tutorial you’ll use Airflow to create an index in OpenSearch, ingest the lyrics of the musical Hamilton into the index, and run a search query on the index to see which character most often sings a specific word.
Why use Airflow with OpenSearch?
OpenSearch allows you to perform complex search queries on indexed text documents. Additionally, the tool comes with a variety of plugins for use cases such as security analytics, semantic search, and neural search.
Integrating OpenSearch with Airflow allows you to:
- Use Airflow’s data-driven scheduling to run operations involving documents stored in OpenSearch based on upstream events in your data ecosystem, such as when a new model is trained or a new dataset is available.
- Run dynamic queries based on upstream events in your data ecosystem or user input via Airflow params on documents and vectors stored in OpenSearch to retrieve relevant objects.
- Add Airflow features like retries and alerts to your OpenSearch operations.
Time to complete
This tutorial takes approximately 30 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of OpenSearch. See the OpenSearch documentation.
- Vector embeddings. See Using OpenSearch as a Vector Database.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- Airflow decorators. Introduction to the TaskFlow API and Airflow decorators.
- Airflow connections. See Managing your Connections in Apache Airflow.
Prerequisites
- The Astro CLI.
This tutorial uses a local OpenSearch instance created as a Docker container. You don’t need to install OpenSearch on your machine.
The example code from this tutorial is also available on GitHub.
Step 1: Configure your Astro project
-
Create a new Astro project:
-
Add the following two lines to your Astro project
requirements.txtfile to install the OpenSearch Airflow provider and the pandas package in your Astro project: -
This tutorial uses a local OpenSearch instance running in a Docker container. To run an OpenSearch container as part of your Airflow environment, create a new file in your Astro project root directory called
docker-compose.override.ymland copy and paste the following into it: -
Add the following configuration to your
.envfile to create an Airflow connection between Airflow and your OpenSearch instance. If you already have a cloud-based OpenSearch instance, you can connect to that instead of the local instance by adjusting the values in the connection.
Step 2: Add your data
The DAG in this tutorial uses a Kaggle dataset that contains the lyrics of the musical Hamilton.
-
Download the hamilton_lyrics.csv from Astronomer’s GitHub.
-
Save the file in your Astro project
includefolder.
Step 3: Create your DAG
-
In your
dagsfolder, create a file calledsearch_hamilton.py. -
Copy the following code into the file.
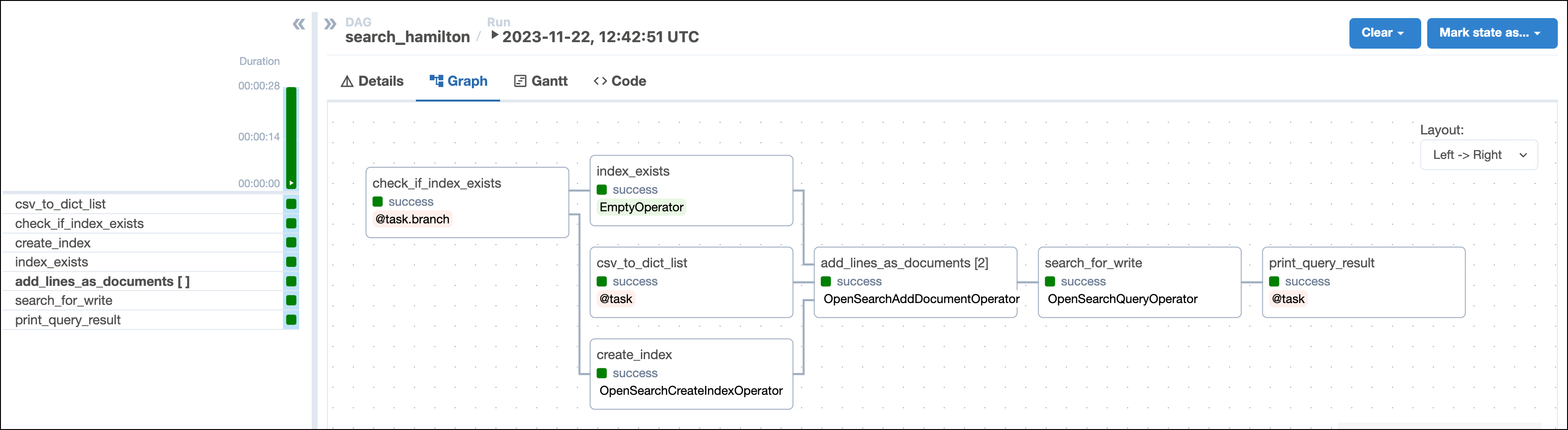
This DAG consists of seven tasks to make a simple ML orchestration pipeline.
- The
check_if_index_existstask uses a@task.branchdecorator to check if the indexOPENSEARCH_INDEX_NAMEexists in your OpenSearch instance. If it doesn’t exist, the task returns the stringcreate_indexcausing the downstreamcreate_indextask to run. If the index exists, the task causes the emptyindex_existstask to run instead. - The
create_indextask defined with the OpenSearchCreateIndexOperator creates the indexOPENSEARCH_INDEX_NAMEin your OpenSearch instance with the three propertiestitle,speakerandlines. - The
csv_to_dict_listtask uses the@taskdecorator to ingest the lyrics of the musical Hamilton from thehamilton_lyrics.csvfile into a list of Python dictionaries. Each dictionary represents a line of the musical and will be one document in the OpenSearch index. - The
add_lines_as_documentstask is a dynamically mapped task using the OpenSearchAddDocumentOperator to create one mapped task instance for each document to ingest. - The
search_for_keywordtask is defined with the OpenSearchQueryOperator and performs a fuzzy query on the OpenSearch index to find the character and song that mention theKEYWORD_TO_SEARCHthe most. - The
print_query_resultprints the query results to the task logs.
For information on more advanced search techniques in OpenSearch, see the OpenSearch documentation.
Step 4: Run your DAG
-
Run
astro dev startin your Astro project to start Airflow and open the Airflow UI atlocalhost:8080. -
In the Airflow UI, run the
search_hamiltonDAG by clicking the Play button. By default the DAG will search the lyrics for the wordwrite, but you can change the search term by updating theKEYWORD_TO_SEARCHvariable in your DAG file. -
View your song results in the task logs of the
print_query_resulttask: -
(Optional) Listen to the song that mentions your keyword the most.
Conclusion
Congratulations! You used Airflow and OpenSearch to analyze the lyrics of Hamilton! You can now use Airflow to orchestrate OpenSearch operations in your own machine learning pipelines. History has its eyes on you.