Train a machine learning model with SageMaker and Airflow
This page hasn’t yet been updated for Airflow 3. The concepts shown are relevant, but some code may need to be updated. If you run any examples, take care to update import statements and watch for any other breaking changes.
Amazon SageMaker is a comprehensive AWS machine learning (ML) service that is frequently used by data scientists to develop and deploy ML models at scale. With Airflow, you can orchestrate every step of your SageMaker pipeline, integrate with services that clean your data, and store and publish your results using only Python code.
This tutorial demonstrates how to orchestrate a full ML pipeline including creating, training, and testing a new SageMaker model. This use case is relevant if you want to automate the model training, testing, and deployment components of your ML pipeline.
Other ways to learn
There are multiple resources for learning about this topic. See also:
Time to complete
This tutorial takes approximately 60 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of Amazon S3 and Amazon SageMaker.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
- Airflow operators. See Operators 101.
- Airflow connections. See Managing your Connections in Apache Airflow.
Prerequisites
To complete this tutorial, you need:
-
An AWS account with:
- Access to an S3 storage bucket. If you don’t already have an account, Amazon offers 5 GB of free storage in S3 for 12 months. This should be more than enough for this tutorial.
- Access to AWS SageMaker. If you don’t already use SageMaker, Amazon offers a free tier for the first month.
-
The Astro CLI.
Step 1: Create a role to access SageMaker
For this tutorial, you will need to access SageMaker from your Airflow environment. There are multiple ways to do this, but for this tutorial you will create an AWS role that can access SageMaker and create temporary credentials for that role.
If you are uncertain which method you use to connect to AWS, contact your AWS Administrator. These steps may not fit your desired authentication mechanism.
-
From the AWS web console, go to IAM service page and create a new execution role for SageMaker. See Create execution roles in the AWS documentation.
-
Add your AWS user and
sagemaker.amazonaws.comas a trusted entity to the role you just created. See Editing the trust relationship for an existing role. Note that this step might not be necessary depending on how IAM roles are managed for your organization’s AWS account. -
Using the ARN of the role you just created, generate temporary security credentials for your role. There are multiple methods for generating the credentials. For detailed instructions, see Using temporary credentials with AWS resources. You will need the access key ID, secret access key, and session token in Step 5.
Step 2: Create an S3 bucket
Create an S3 bucket in the us-east-2 region that will be used for storing data and model training results. Make sure that your bucket is accessible by the role you created in Step 1. See Creating a bucket.
Note that if you need to create a bucket in a different region than us-east-2, you will need to modify the region specified in the environment variables created in Step 3 and in the DAG code in Step 6.
Step 3: Configure your Astro project
Now that you have your AWS resources configured, you can move on to Airflow setup. Using the Astro CLI:
-
Create a new Astro project:
-
Add the following line to the
requirements.txtfile of your Astro project:This installs the AWS provider package which contains relevant S3 and SageMaker modules. It also installs the
astronomer-providerspackage, which contains deferrable versions of some SageMaker modules that can help you save costs for long-running jobs. If you use an older version of the AWS provider, some of the DAG configuration in later steps may need to be modified. Deferrable SageMaker operators aren’t available in older versions of theastronomer-providerspackage. -
Add the following environment variables to the
.envfile of your project:These variables ensure that all SageMaker operators will work in your Airflow environment. Some require XCom pickling to be turned on in order to work because they return objects that aren’t JSON serializable.
-
Run the following command to start your project in a local environment:
Step 4: Add Airflow Variables
Add two Airflow variables that will be used by your DAG. In the Airflow UI, go to Admin -> Variables.
-
Add a variable with the ARN of the role you created in Step 1.
- Key:
role - Val:
<your-role-arn>
- Key:
-
Add a variable with the name of the S3 bucket you created in Step 2.
- Key:
s3_bucket - Val:
<your-s3-bucket-name>
- Key:
Step 5: Add an Airflow connection to SageMaker
Add a connection that Airflow will use to connect to SageMaker and S3. In the Airflow UI, go to Admin -> Connections.
Create a new connection named aws-sagemaker and choose the Amazon Web Services connection type. Fill in the AWS Access Key ID and AWS Secret Access Key with the access key ID and secret access key you generated in Step 1.
In the Extra field, provide your AWS session token generated in Step 1 using the following format:
Your AWS credentials will only last one day using this authentication method. If you return to this step after your credentials have expired, you will need to edit the details in the connection with updated credentials.
Your connection should look like this:
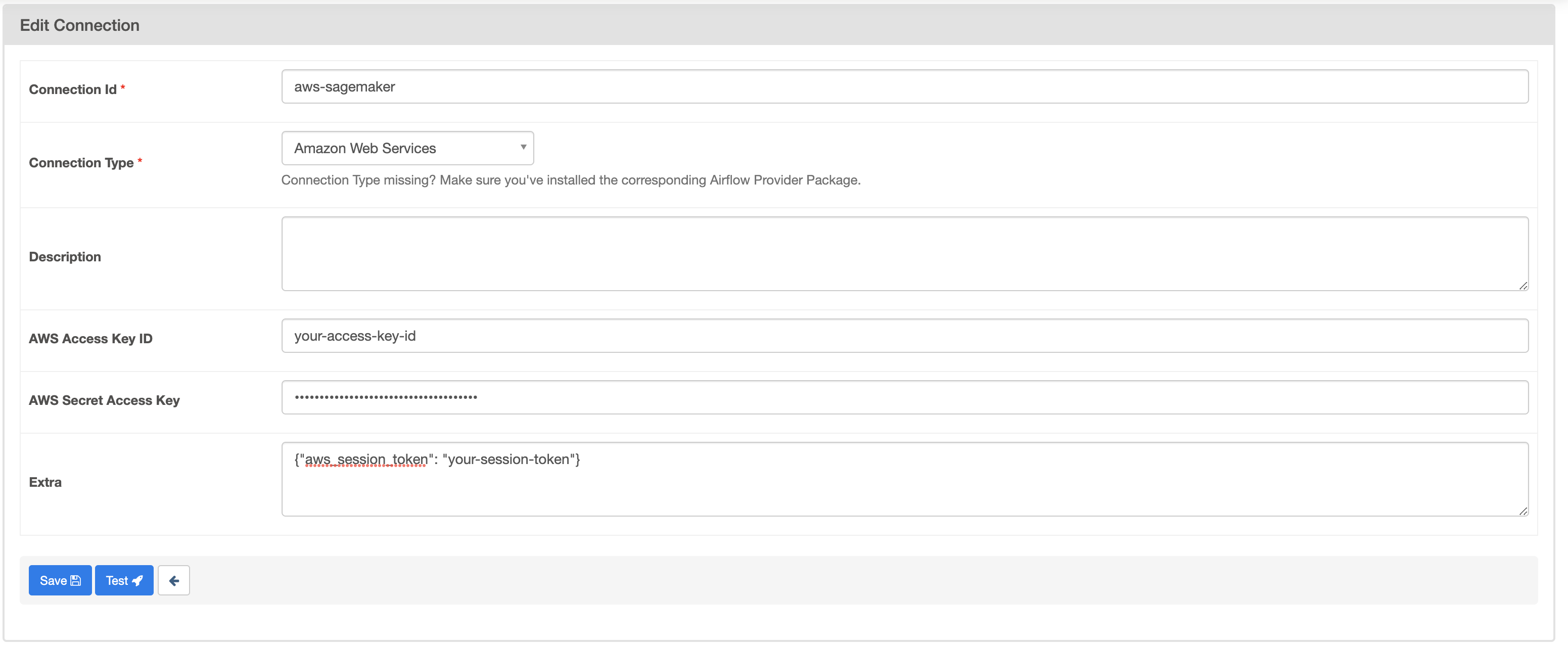
As mentioned in Step 1, there are multiple ways of connecting Airflow to AWS resources. If you are using a method other than the one described in this tutorial, such as having your Airflow environment assume an IAM role, you may need to update your connection accordingly.
Step 6: Create your DAG
In your Astro project dags/ folder, create a new file called sagemaker_pipeline.py. Paste the following code into the file:
The graph view of the DAG should look similar to this:
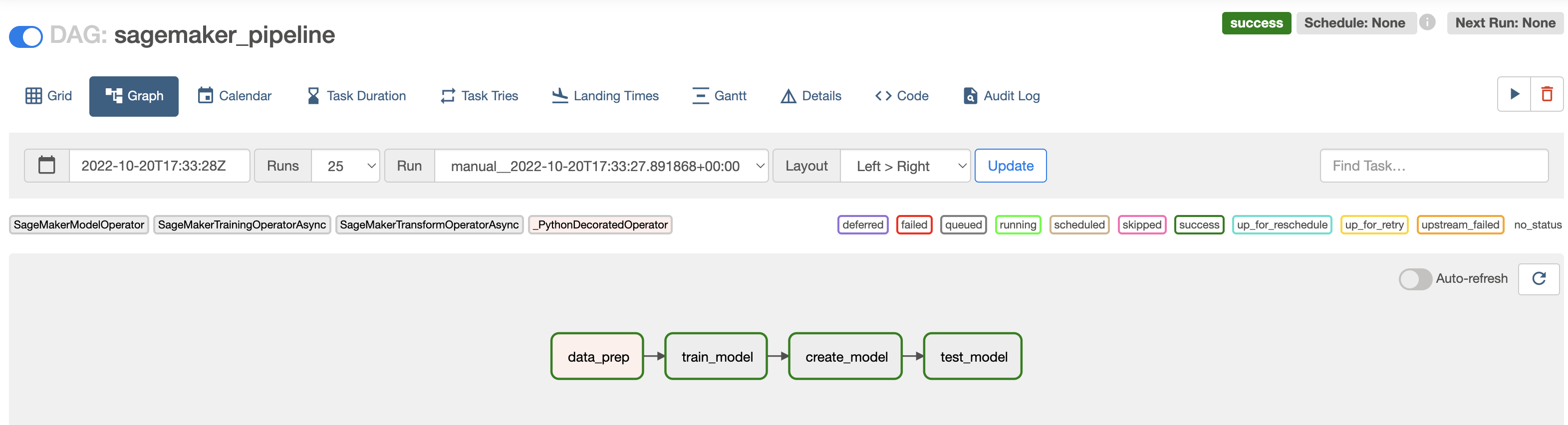
This DAG uses the @task decorator and several SageMaker operators to get data from an API endpoint, train a model, create a model in SageMaker, and test the model. See How it works for more information about each task in the DAG and how the different SageMaker operators work.
Step 7: Run your DAG to train the model
Go to the Airflow UI, unpause your sagemaker_pipeline DAG, and trigger it to train, create and test the model in SageMaker. Note that the train_model and test_model tasks may take up to 10 minutes each to complete.
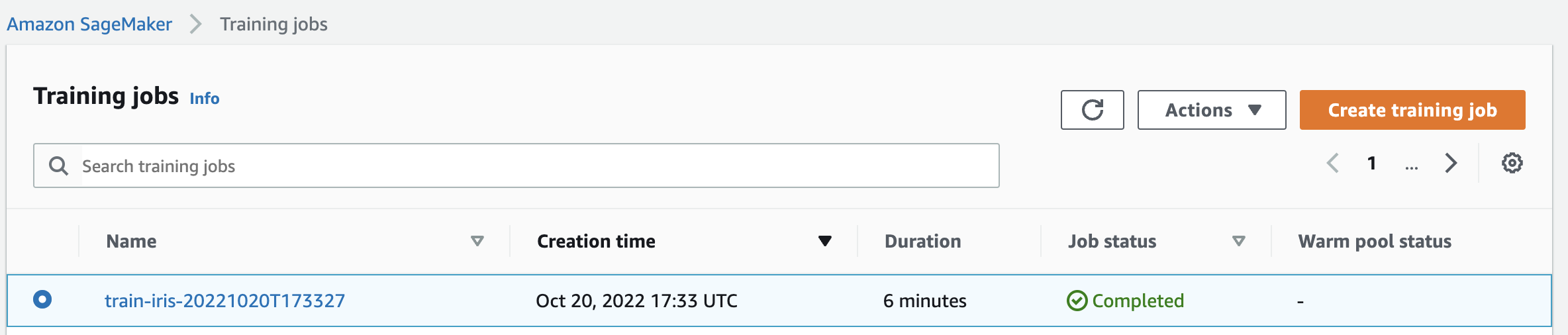
In the SageMaker console, you should see your completed training job.
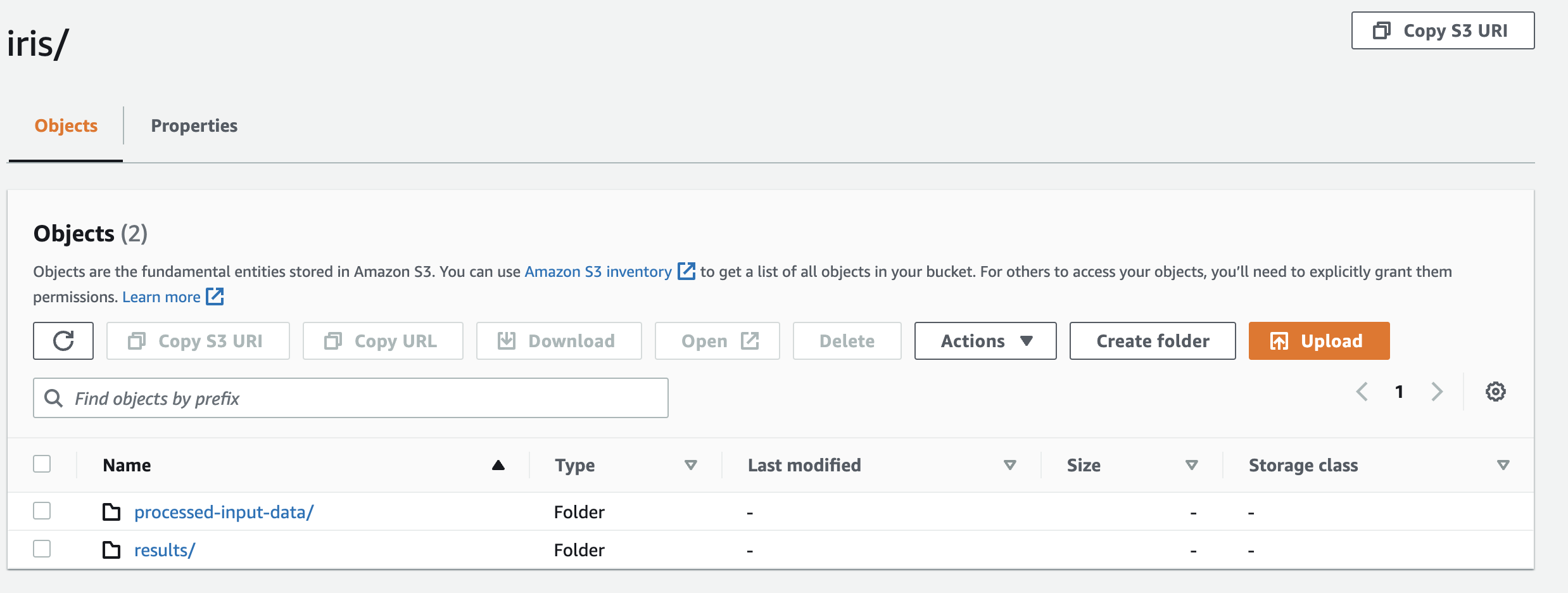
In your S3 bucket, you will have a folder called processed-input-data/ containing the processed data from the data_prep task, and a folder called results/ that contains a model.tar.gz file with the trained model and a CSV file with the output of the model testing.
How it works
This example DAG acquires and pre-processes data, trains a model, creates a model from the training results, and evaluates the model on test data using a batch transform job. This example uses the Iris dataset, and trains a built-in SageMaker K-Nearest Neighbors (KNN) model. The general steps in the DAG are:
-
Using a
PythonOperator, grab the data from the API, complete some pre-processing so the data is compliant with KNN requirements, split into train and test sets, and save them to S3 using theS3Hook. -
Train the KNN algorithm on the data using the
SageMakerTrainingOperatorAsync. We use a deferrable version of this operator to save resources on potentially long-running training jobs. The configuration for this operator requires:- Information about the algorithm being used.
- Any required hyper parameters.
- The input data configuration.
- The output data configuration.
- Resource specifications for the machine running the training job.
- The Role ARN for execution.
For more information about submitting a training job, check out the API documentation.
-
Create a SageMaker model based on the training results using the
SageMakerModelOperator. This step creates a model artifact in SageMaker that can be called on demand to provide inferences. The configuration for this operator requires:- A name for the model.
- The Role ARN for execution.
- The image containing the algorithm (in this case the pre-built SageMaker image for KNN).
- The S3 path to the model training artifact.
For more information on creating a model, check out the API documentation here.
-
Evaluate the model on the test data created in task 1 using the
SageMakerTransformOperatorAsync. This step runs a batch transform to get inferences on the test data from the model created in task 3. The DAG uses a deferrable version ofSageMakerTransformOperatorto save resources on potentially long-running transform jobs. The configuration for this operator requires:- Information about the input data source.
- The output results path.
- Resource specifications for the machine running the training job.
- The name of the model.
For more information on submitting a batch transform job, check out the API documentation.
To clone the entire repository used to create this tutorial as well as an additional DAG that performs batch inference using an existing SageMaker model, check out the Airflow Registry.
In addition to the modules shown in this tutorial, the AWS provider contains multiple other SageMaker operators and sensors that are built on the SageMaker API and cover a wide range of SageMaker features. In general, documentation on what should be included in the configuration of each operator can be found in the corresponding Actions section of the API documentation.
Conclusion
In this tutorial, you learned how to use Airflow with SageMaker to automate an end-to-end ML pipeline. A natural next step would be to deploy this model to a SageMaker endpoint using the SageMakerEndpointConfigOperator and SageMakerEndpointOperator, which provisions resources to host the model. In general, the SageMaker modules in the AWS provider allow for many possibilities when using Airflow to orchestrate ML pipelines.