Best practices for orchestrating MLOps pipelines with Airflow
This page hasn’t yet been updated for Airflow 3. The concepts shown are relevant, but some code may need to be updated. If you run any examples, take care to update import statements and watch for any other breaking changes.
Machine Learning Operations (MLOps) is a broad term encompassing everything needed to run machine learning models in production. MLOps is a rapidly evolving field with many different best practices and behavioral patterns, with Apache Airflow providing tool agnostic orchestration capabilities for all steps.
In this guide you learn:
- How Airflow fits into the MLOps landscape.
- How Airflow can be used for large language model operations (LLMOps).
- How Airflow can help you implement best practices for different MLOps components.
- Which Airflow features and integrations are especially useful for MLOps.
- Where to find additional resources and reference implementations on using Airflow for MLOps.
Ready to get started? Check out the recommended resources that showcase ML and AI implementations with Airflow:
- Orchestrate LLMs and Agents with Apache Airflow® eBook.
- Context Graphs with Apache Airflow® quick notes.
- AI Context Engineering with Apache Airflow® webinar.
- Our GenAI and MLOps reference architectures.
Assumed knowledge
To get the most benefits from this guide, you need an understanding of:
- The basics of Machine Learning.
- Basic Airflow concepts. See Introduction to Apache Airflow.
Why use Airflow for MLOps?
Machine learning operations (MLOps) encompasses all patterns, tools, and best practices related to running machine learning models in production.
Apache Airflow sits at the heart of the modern MLOps stack. Because it is tool agnostic, Airflow can orchestrate all actions in any MLOps tool that has an API. Combined with already being the de-facto standard for orchestrating data pipelines, Airflow is the perfect tool for data engineers and machine learning engineers to standardize their workflows and collaborate on pipelines.
The benefits of using Airflow for MLOps are:
- Python native: You use Python code to define Airflow pipelines, which makes it easy to integrate the most popular machine learning tools and embed your ML operations in a best practice CI/CD workflow. By using the decorators of the TaskFlow API you can turn existing scripts into Airflow tasks.
- Extensible: Airflow itself is written in Python, which makes it extensible with custom modules and Airflow plugins.
- Monitoring and alerting: Airflow comes with production-ready monitoring and alerting modules like Airflow notifiers, extensive logging features, and Airflow listeners. They enable you to have fine-grained control over how you monitor your ML operations and how Airflow alerts you if something goes wrong.
- Pluggable compute: When using Airflow you can pick and choose the compute you want to use for each task. This allows you to use the perfect environment and resources for every single action in your ML pipeline. For example, you can run your data engineering tasks on a Spark cluster and your model training tasks on a GPU instance.
- Data agnostic: Airflow is data agnostic, which means it can be used to orchestrate any data pipeline, regardless of the data format or storage solution. You can plug in any new data storage, such as the latest vector database or your favorite RDBMS, with minimal effort.
- Incremental and idempotent pipelines: Airflow allows you to define pipelines that operate on data collected in a specified timeframe and to perform backfills and reruns of a set of idempotent tasks. This lends itself well to creating feature stores, especially for time-dimensioned features, which form the basis of advanced model training and selection.
- Ready for day 2 Ops: Airflow is a mature orchestrator, coming with built-in functionality such as automatic retries, complex dependencies and branching logic, as well as the option to make pipelines dynamic.
- Integrations: Airflow has a large ecosystem of integrations, including many popular MLOps tools.
- Shared platform: Both data engineers and ML engineers use Airflow, which allows teams to create direct dependencies between their pipelines, such as using Airflow Datasets.
- Use existing expertise: Many organizations are already using Apache Airflow for their data engineering workflows and have developed best practices and custom tooling around it. This means that data engineers and ML engineers alike can build upon existing processes and tools to orchestrate and monitor ML pipelines.
Why use Airflow for LLMOps?
Large Language Model Operations (LLMOps) is a subset of MLOps that describes interactions with large language models (LLMs). In contrast to traditional ML models, LLMs are often too large to be trained from scratch and LLMOps techniques instead revolve around adapting existing LLMs to new use cases.
The three main techniques for LLMOps are:
- Prompt engineering: This is the simplest technique to influence the output of an LLM. You can use Airflow to create a pipeline that ingests user prompts and modifies them according to your needs, before sending them to the LLM inference endpoint.
- Retrieval augmented generation (RAG): RAG pipelines retrieve relevant context from domain-specific and often proprietary data to improve the output of an LLM.
- Fine-tuning: Fine-tuning LLMs typically involves retraining the final layers of an LLM on a specific dataset. This often requires more complex pipelines and a larger amount of compute that can be orchestrated with Airflow.
Components of MLOps
MLOps describes different patterns in how organizations can productionize machine learning models. MLOps consists of four main components:
- BusinessOps: the processes and activities in an organization that are needed to deliver any outcome, including successful MLOps workflows.
- DevOps: the software development (dev) and IT operations (ops) practices that are needed for the delivery of any high quality software, including machine learning based applications.
- DataOps: the practices and tools surrounding data engineering and data analytics to build the foundation for machine learning implementations.
- ModelOps: automated governance, management and monitoring of machine learning models in production.
Organizations are often at different stages of maturity for each of these components when starting their MLOps journey. Using Apache Airflow to orchestrate MLOps pipelines can help you progress in all of them.
BusinessOps
The first component of MLOps is to make sure there is strategic alignment with all stakeholders. This component varies widely depending on your organization and use case and can include:
- Business strategy: Defining what ML is used for in an organization and what trade-offs are acceptable. Often, models can be optimized for different metrics, for example high recall or high precision, and domain experts are needed to determine the right metrics and model strategy.
- Model governance: Creating and following regulations for how your organization uses machine learning. This often depends on relevant regulations, like GDPR or HIPAA. Airflow has a built-in integration option with Open Lineage, the open-source standard for tracking data lineage, which is a key component of model governance.
DevOps
Since you define Airflow pipelines in Python code, you can apply DevOps best practices when using Airflow. This includes:
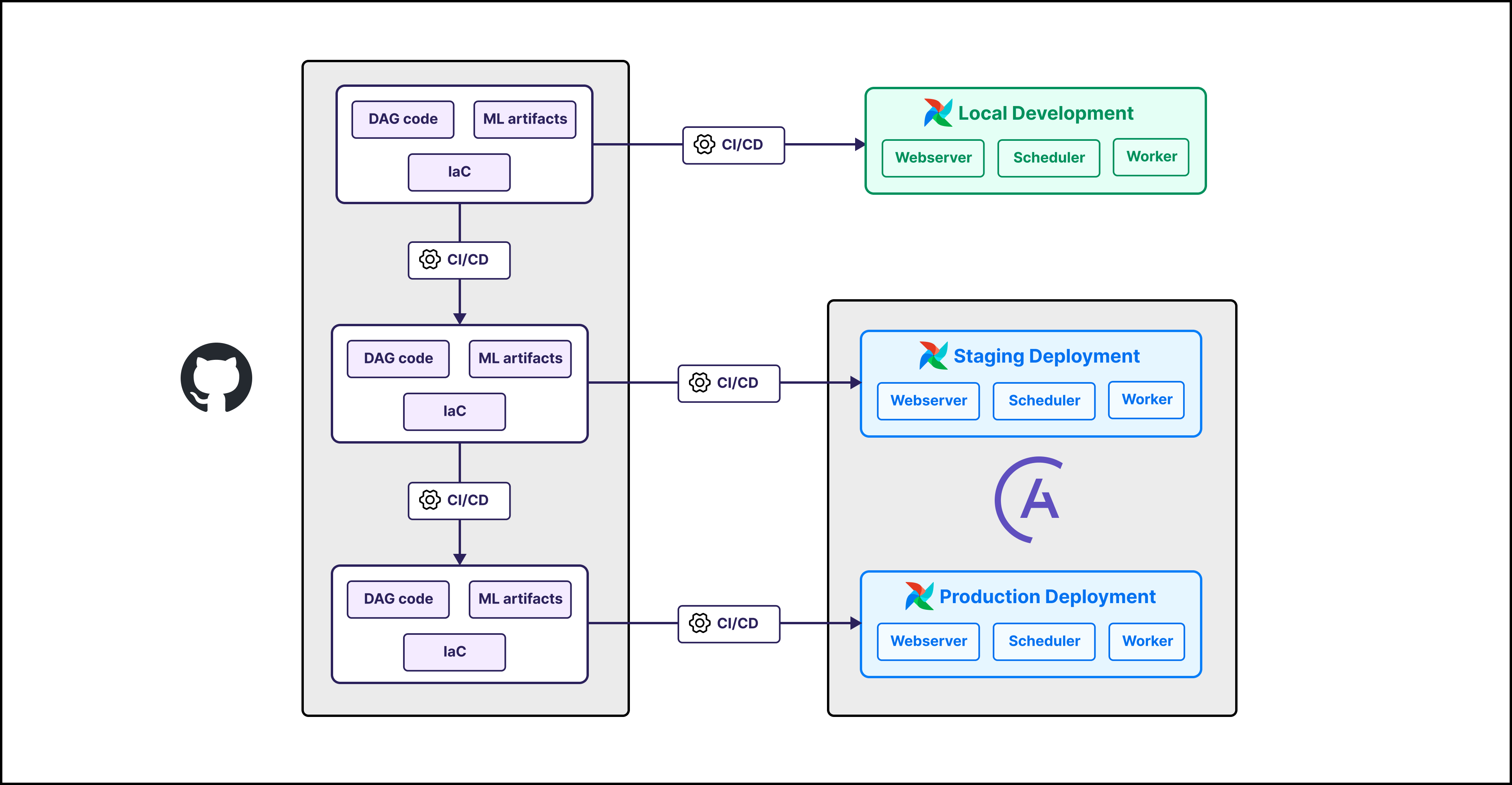
- Version control. All code and configuration should be stored in a version control system like Git. Version control allows you to track all changes of your pipeline, ML model, and environment over time and roll back to previous versions if needed. Astro customers can take advantage of Deployment rollbacks.
- Continuous integration/ continuous delivery (CI/CD). It is a standard software best practice for all code to undergo automatic testing, linting, and deployment. This ensures that your code is always in a working state and that any changes are automatically deployed to production. Airflow integrates with all major CI/CD tools, see CI/CD templates for popular templates.
Astronomer customers can use the Astro GitHub integration, which allows you to automatically deploy code from a GitHub repository to an Astro deployment, viewing Git metadata in the Astro UI. See Deploy code with the Astro GitHub integration.
- Infrastructure as code (IaC). Ideally, all infrastructure is defined as code and follows the same CI/CD process as your pipeline and model code. This allows you to control and, if necessary, roll back environment changes, or quickly deploy new instances of your model.
In practice, following modern DevOps patterns when using Airflow for MLOps means:
- Storing all Airflow code and configuration in a version control system like Git.
- Setting up development, staging, and production branches in your version control system and also connecting them to different Airflow environments. For Astro customers, see Manage Astro connections in branch-based deploy workflows.
- Use automatic testing and linting for all Airflow code before deployment.
- Define all infrastructure as code and use the same CI/CD process for infrastructure as for your Airflow code.
- Store model artifacts in a versioned system. This can be a dedicated tool like MLFlow or an object storage solution.
DataOps
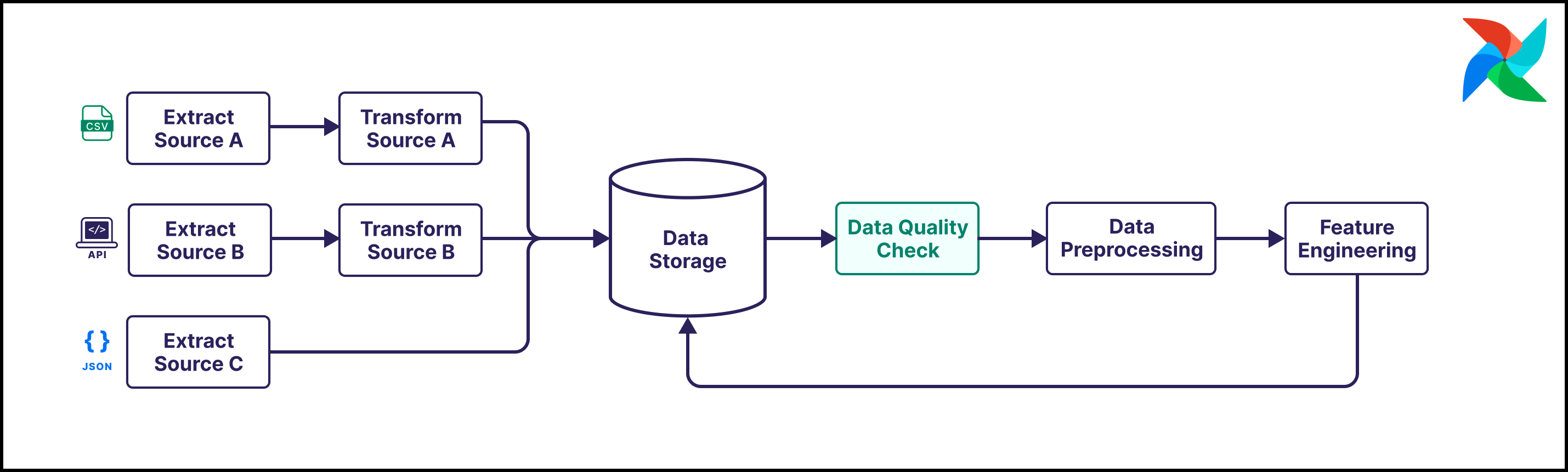
There is no MLOps without data. You need to have robust data engineering workflows in place in order to confidently train, test, and deploy ML models in production. Apache Airflow has been used by millions of data engineers to create reliable best practice data pipelines, providing a strong foundation for your MLOps workflows.
Give special considerations to the following:
- Data quality and data cleaning. If your data is of bad quality, your model predictions will be too. Astronomer recommends incorporating data quality checks and data cleaning steps into your data pipelines to define and monitor the requirements your data has to fulfill in order for downstream ML operations to be successful. Airflow supports integration with any data quality tool that has an API, and has pre-built integrations for tools such as Great Expectations and Soda Core.
- Data preprocessing and feature engineering. It is common for data to undergo several transformation steps before it is ready to be used as input for an ML model. These steps can include simple preprocessing steps like scaling, one-hot-encoding, or imputation of missing values. It can also include more complex steps like feature selection, dimensionality reduction, or feature extraction. Airflow allows you to run preprocessing and feature engineering steps in a pythonic way using Airflow decorators.
- Data storage.
- Training and testing data. The best way to store your data highly depends on your data and type of ML. Data engineering includes ingesting data and moving it to the ideal platform for your ML model to access. This can, for example, be an object storage solution, a relational database management system (RDBMS), or a vector database. Airflow integrates with all these options, with tools such as Airflow object storage simplifying common operations.
- Model artifacts. Model artifacts include model parameters, hyperparameters, and other metadata. Airflow integrates with specialized version control systems such as MLFlow or Weights & Biases.
Apart from the foundations described earlier, second day data quality operations in MLOps often include advanced topics like data governance, data lineage, and data cataloging as well as monitoring of data drift.
In practice, following modern data engineering patterns when using Airflow for MLOps means:
- Following general Airflow best practices for DAG writing, such as keeping tasks atomic and idempotent.
- Using Airflow to orchestrate data ingestion from sources such as APIs, source databases, and object storage into a working location for your ML model. This might be a vector database, a relational database, or an object storage solution depending on your use case.
- Incorporating data quality checks into your Airflow pipelines, with critical data quality checks halting the pipeline or alerting you if they fail.
- Using Airflow to orchestrate data preprocessing and feature engineering steps.
- Moving data to permanent cold storage after it has been used for training and testing.
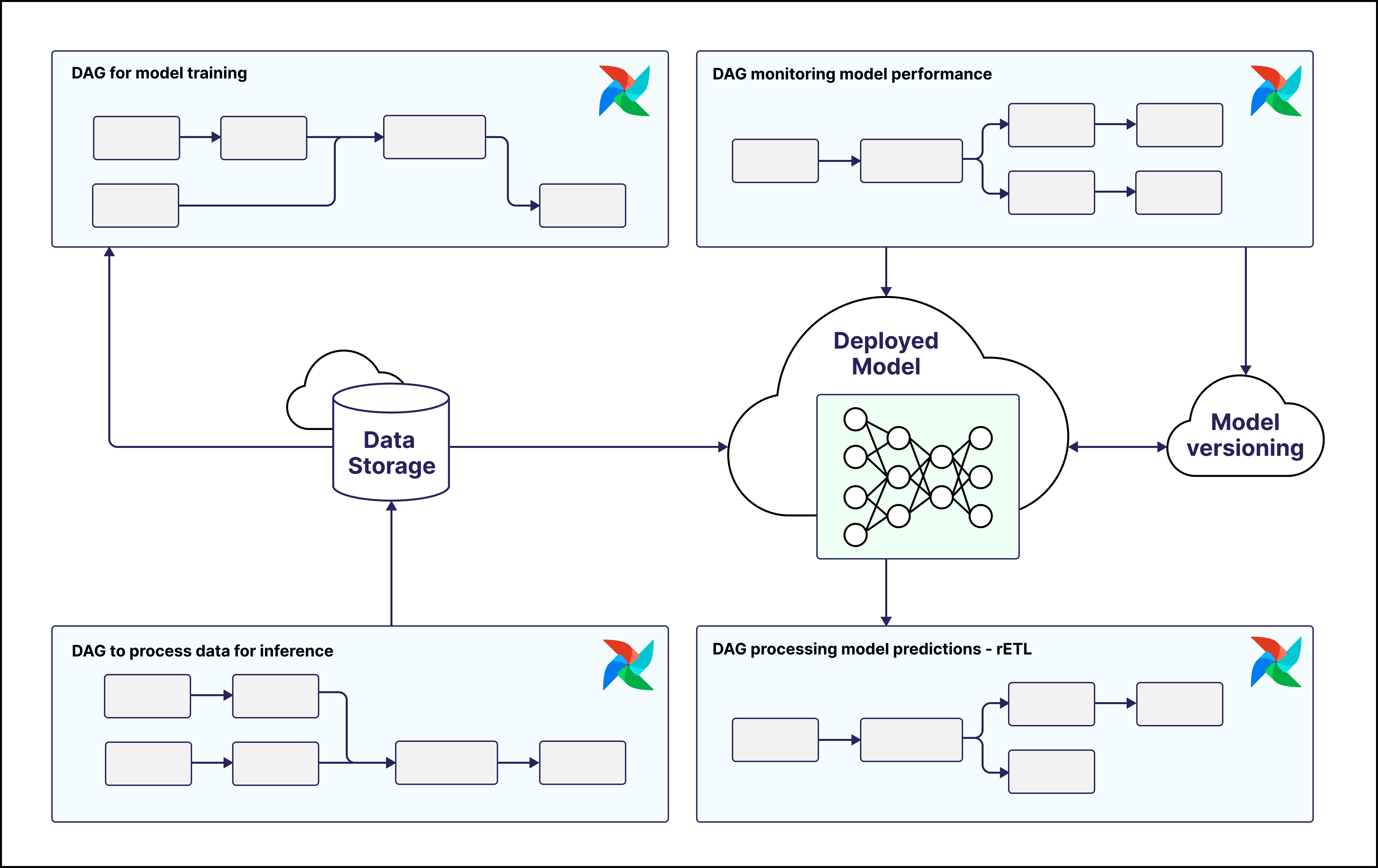
ModelOps
After you establish strong DevOps and data engineering foundations, you can start to implement model operations.
With Airflow you can use the ML tools and compute locations of your choice. Some organizations choose to use external compute for all of their heavy workloads, for example:
- External Kubernetes clusters: with the KubernetesPodOperator (and its decorator version
@task.kubernetes). - Databricks: with the Astro Databricks provider and Databricks Airflow provider.
- Spark: with modules from the Spark Airflow provider.
- External compute: in AWS, Azure and Google Cloud using the respective Airflow providers.
Other Airflow users decide to scale up their Airflow infrastructure with larger worker nodes for compute intensive tasks. Astro customers can use the worker queues feature, which lets them decide the exact specifications for the workers each task can run on. This means that Airflow only uses large workers for the biggest workloads, saving compute and cost.
In practice, following modern model operations patterns when using Airflow for MLOps means:
- Performing exploratory data analysis and test potential ML applications on small subsets of data in a notebook environment before moving to production. Tools like Jupyter notebooks are widely used and run Python code you can later convert to tasks in Airflow DAGs.
- Using Airflow to orchestrate model training, fine-tuning, testing, and deployment.
- Having Airflow tasks monitor the performance of your model and perform automated actions such as re-training, re-deploying, or alerting if the performance drops below a certain threshold.
How Airflow addresses MLOps challenges
When using Apache Airflow for MLOps, there are three main patterns you can follow:
- Using Apache Airflow to orchestrate actions in other MLOps tools. Airflow is a tool-agnostic orchestrator, which means it can also orchestrate all actions in ML specific tools like MLFlow or AWS SageMaker.
- Combine orchestration of actions in other tools with ML operations running within Airflow. For example, you can create vector embeddings in a Python function in Airflow and then use these embeddings to train a model in Google Datalab. Modules like the
@task.kubernetesor@task.external_python_operatormake it easy to run any Python code in isolation with optimized environments and resources. - Run all your MLOps using Python modules inside Airflow tasks. Since Airflow can run any Python code and scale indefinitely, you can use it as an all-purpose MLOps tool.
Airflow features for MLOps
A specific set of Airflow features can help you implement MLOps best practices:
-
Data driven scheduling: With Airflow datasets, you can schedule DAGs to run after a specific dataset is updated by any task in the DAG. For example, you can schedule your model training DAG to run after the training dataset is updated by the data engineering DAG. See Orchestrate machine learning pipelines with Airflow datasets.

-
Dynamic task mapping: In Airflow, you can map tasks and task groups dynamically at runtime. This allows you to run similar operations in parallel without knowing in advance how many operations run in any given DAGrun. For example, you can dynamically run a set of model training tasks in parallel, each with different hyperparameters.

-
Setup and teardown: Airflow allows you to define setup and teardown tasks which create and remove resources used for machine learning. This extends the concept of infrastructure as code to your ML environment, by making the exact state of your environment for a specific ML operation reproducible.

-
Branching: Airflow allows you to branch your DAG based on the outcome of a task. You can use this to create different paths in your DAG based on the outcome of a task. For example, you can branch your DAG based on the performance of a model on a test set and only deploy the model if it performs above a certain threshold.

-
Alerts and Notifications: Airflow has a wide variety of options to alert you of events in your pipelines, such as DAG or task failures. It is a best practice to set up alerts for critical events in your ML pipelines, such as a drop in model performance or a data quality check failure. Astronomer customers can use Astro Alerts.
-
Automatic retries: Airflow allows you to configure tasks to automatically retry if they fail according to custom set delays. This feature is critical to protect your pipeline against outages of external tools or rate limits and can be configured at the global, DAG, or the individual task level.
-
Backfills and Reruns: In Airflow, you can rerun previous DAG runs and create backfill DAG runs for any historical period. If your DAGs run on increments of time-dimensioned data and are idempotent, you can retroactively change features and create new ones based on historical data. This is a key pattern for creating feature stores containing time-dimensioned features to train and test your models.
Airflow integrations for MLOps
With Airflow, you can orchestrate actions in any MLOps tool that has an API. Many MLOps tools have integrations available with pre-defined modules like operators, decorators, and hooks to interact with the tool. For example, there are integrations for:
- AWS SageMaker. A tool to train and deploy machine learning models on AWS.
- Databricks. A tool to run Apache Spark workloads.
- Cohere. A tool to train and deploy LLMs.
- OpenAI. A tool to train and deploy large models, including
GPT-4andDALL·E 3. - Weights & Biases. A tool to track and visualize machine learning experiments.
- Weaviate. An open source vector database.
- OpenSearch. An open source search engine with advanced ML features.
- Pgvector. An extension enabling vector operations in PostgreSQL.
- Pinecone. A proprietary vector database.
- (Beta) Snowpark. An interface to run non-SQL code in Snowflake, includes the machine learning library Snowpark ML.
- Azure ML. A tool to train and deploy machine learning models on Azure.
Additionally, the provider packages for the main cloud providers include modules to interact with their ML tools and compute options:
Resources
To learn more about using Airflow for MLOps, check out the following resources:
- Reference architectures:
- Webinars:
- Modern Infrastructure for World Class AI Applications - a joint webinar with Astronomer and Weaviate.
- Driving Next-Gen AI Applications with AWS and Astronomer
- Optimizing ML/AI Workflows with Essential Airflow Features
- Airflow at Faire: Democratizing Machine Learning at Scale
- How to Orchestrate Machine Learning Workflows with Airflow
- Batch Inference with Airflow and SageMaker
- Using Airflow with Tensorflow and MLFlow
- eBooks and white papers:
- Podcast episodes:
- Using Airflow To Power Machine Learning Pipelines at Optimove with Vasyl Vasyuta
- The Intersection of AI and Data Management at Dosu with Devin Stein
- How Laurel Uses Airflow To Enhance Machine Learning Pipelines with Vincent La and Jim Howard
- AI-Powered Vehicle Automation at Ford Motor Company with Serjesh Sharma
Astronomer wants to help you succeed with Airflow by continuously creating resources on how to use Airflow for MLOps. If you have any questions or suggestions for additional topics to cover, contact us in the #airflow-astronomer channel in the Apache Airflow Slack.