Migrate Python Jobs to Airflow in 4 Simple Steps
11 min read |
Originally designed by Guido van Rossum for code readability, less-cluttered syntax, and simplicity, Python is omnipresent in today’s programming world. It has a variety of applications including, web development, big data, machine learning, and many more. Its growth in data analytics, data processing, data science and other related domains has been phenomenal. Any data-related course is incomplete without learning Python, because it is easy to learn and use, flexible, and has tremendous community support. With hundreds of Python libraries for data processing, it’s natural for startups and large organizations alike to adopt Python and use it to their advantage.
However, Python scripts need to be scheduled and monitored to be of value in a production-grade environment. This is where a data orchestrator like Apache Airflow® comes in to the picture. Similarly to Python, when you think of orchestrating your Python scripts or jobs, Airflow is the industry standard because it is easy to learn, flexible, and has tremendous community support.
In this blog, we will see how easy it is to migrate your Python jobs into Directed Acyclic Graphs (DAGs) with modular tasks and orchestrate them in Airflow, and how to use Airflow features to make your jobs better and efficient.
Scheduling Python scripts
Typically, when you are ready to deploy your new Python data pipeline to production and you do not have a data orchestrator, there are some common options to consider depending on your infrastructure setup:
- Crontab on a production server or an edge node (on-premises or in the cloud)
- Serverless compute service (AWS Lambda, Azure Functions, Google Cloud Functions)
- Run the script as a whole using an existing ETL tool
The problem with these methods is, they run your script (even if it is modular) as one block, making it hard to to restart your script from the point of failure. In a new setup with a few scripts acting as data pipelines, any one of the above option will work just fine. But as you scale and your data stack grows, the number of data pipelines will also increase, making it difficult to maintain on a daily basis. Many teams also try to implement a framework for different types scripts to add support for restartability from a given step. But this becomes difficult to maintain and makes the focus shift from data pipelines to data operations.
This is where you will need Airflow on Astro, which will reduce your technical debt, allow data engineers to focus on actual data processing, simplify enhancements and maintenance, and make the development of new pipelines seamless with its advanced features and supporting tools (Astro CLI and Astro API)!
Example Python ETL script
Consider the following standard pipeline written in Python with a typical flow:
import logging
import boto3
import botocore
import redshift_connector
def my_data_pipeline():
logging.basicConfig(level = logging.INFO)
def create_conn():
"""
Create and return a Redshift connection object.
"""
logging.info("Create Redshift connection")
conn = redshift_connector.connect(
host='mk-edu.cgelji8gkhy4.us-east-1.redshift.amazonaws.com',
database='dev',
port=5439,
user='redacted',
password='redacted'
)
return conn
def check_source():
"""
Check the S3 bucket for the file.
"""
logging.info("Checking source s3")
s3 = boto3.client('s3'
, aws_access_key_id='redacted'
, aws_secret_access_key='redacted'
, aws_session_token='redacted'
, region_name='us-east-1'
)
try:
s3.head_object(Bucket='mk-edu', Key='incoming/sample.csv')
except botocore.exceptions.ClientError as e:
if e.response['Error']['Code'] == "404":
logging.info("File not found")
else:
raise
def load_data():
"""
Load data from S3 to Redshift using COPY command.
"""
logging.info("Loading data from S3 to Redshift")
sql = """
copy public.sample(id, name, amount) from 's3://mk-edu/incoming/sample.csv'
credentials 'aws_iam_role=arn:aws:iam::532996336208:role/service-role/AmazonRedshift-CommandsAccessRole-20230921T133424'
DELIMITER ',' IGNOREHEADER 1;
"""
conn = create_conn()
with create_conn() as conn:
with conn.cursor() as cursor:
logging.info(f">> Executing {sql}")
cursor.execute(sql)
conn.commit()
def dq_target():
"""
Run DQ checks on the data loaded in Redshift.
"""
logging.info("Checking counts in Redshift")
sql = "select count(*) as total_count, sum(case when id is null then 1 else 0 end) as null_count from public.sample"
with create_conn() as conn:
with conn.cursor() as cursor:
logging.info(f">> Executing {sql}")
cursor.execute(sql)
logging.info(cursor.fetchall())
logging.info("Start of data pipeline")
check_source()
load_data()
dq_target()
logging.info("End of data pipeline")
my_data_pipeline()Convert Python script into an Airflow DAG
To convert this Python program into an Airflow DAG, we will follow these 4 steps:
- Add
importstatements for Airflow objectsdag,taskand Pythondatetimelibrary:
from datetime import datetime
from airflow.decorators import dag, task- Add
@dagdecorator to the main functionmy_data_pipeline
@dag(schedule="5 12 * * *", start_date=datetime(2021, 12, 1))Notice that the schedule and start_date parameters are mandatory for Airflow to recognize your Python script as an Airflow DAG.
- Add
@taskdecorator to the functions you want to appear as tasks in the Airflow UI.
@task
def check_source():
logging.info("Checking source s3")
...- Use
>>operator to link tasks and create dependencies in the order you want to run them and save.
check_source() >> load_data() >> dq_target()You can checkout this code in the GitHub repo.
Setup local Airflow
Once you have made the changes to your Python script, you can run a local Airflow environment and render your script as an Airflow DAG in the Airflow UI by following these steps:
- Initialize a local Airflow project using
astro dev init. - Copy the Python script with the changes to the
dagsdirectory in your Airflow project. - Start local Airflow environment using
astro dev start. - Go to the Airflow UI
http://localhost:8080, click the DAGmy_data_pipeline, and un-pause it. Based on your timezone, it might automatically get triggered. If not, you can trigger it using the play button on the right side.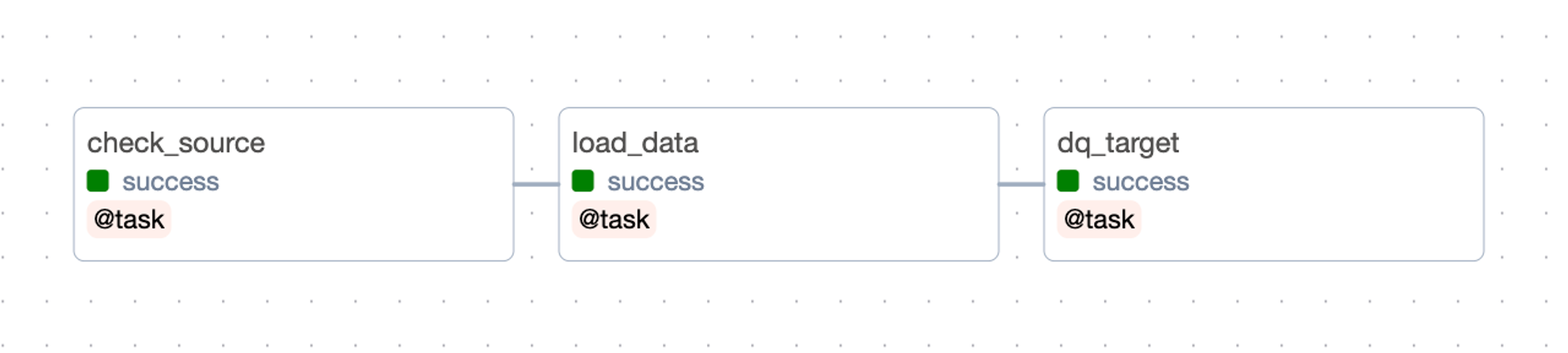
Benefits of Airflow DAGs over Python scripts
What we have just described is the easiest and simplest way to transform your Python scripts to Airfow DAGs, but this Python script for your data pipeline can be made even better using Airflow capabilities. A few immediate benefits include:
- Instead of hardcoding connection secrets in the code in
create_connmethod, you can define an Airflow connection for your database and use it using Airflow Hooks. Learn more about How to manage Airflow connections and variables. - The method
check_source()can be replaced with a S3KeySensorAsync which can look for the files in a specified window. You can also create an Airflow connection for AWS S3 and directly pass the connection name to the operator. - You can use SQL check operators to perform easily configurable data quality checks.
- The metadata from your DAG runs can be accessed using the Airflow API or using
airflow_client. See Expert tips for monitoring health and SLAs of Apache Airflow® DAGs.
You may notice that with these small changes, you will make your data pipeline lean, reduce your technical debt, and make your DAGs more maintainable leading to a mature data stack. Other major benefits include:
- Use Airflow callbacks and notifiers to alert in case of failures.
- Install your custom modules and use as custom operators in Airflow.
- Ability to use different Python Runtime Environment for different use-cases.
- Easily generate DAG documentation for support teams.
- Orchestrate
dbtjobs using Cosmos.
Branching and event-based triggers in Airflow
Adding some complexity to the current example per the following scenario:

- Assume there is an upstream DAG that pulls the data from an API and loads the data to S3 which our DAG reads. We need the main DAG to be auto-triggered as soon as the upstream DAG completes.
- We can use the concept of
Datasetin Airflow for event-based triggering. It is based on the files/tables processed by other DAGs in the same Airflow environment. For example, notice thescheduleparameter ofdagdeclaration:
@dag(schedule=[Dataset("s3://mk-edu/incoming/sample.csv")]
, start_date=datetime(2022, 12, 1)
)
def airflow_data_pipeline():
...Once the upstream DAG completes, our main DAG will be automatically triggered, eliminating the need to specify a fixed schedule. This setup will ensure data-based dependencies between your upstream and downstream tasks.
- We load data to a temporary table and check for data quality (DQ) before loading it into the final table. If DQ checks pass, we proceed with loading to the final table; otherwise, we notify the team about the failure.
- Now, the best part of moving your DAG to Airflow is that you can view and monitor each task separately, implement branching, or skip a path completely based on a condition. Consider the following Python code to handle this scenario in your Python script:
if dq_passed:
load_target()
else:
send_notification()In an Airflow DAG, you can use @task.branch or @task.short_circuit to decide which path to take based on an output or stop processing immediately. These decorators empower you to control how your data pipeline behaves in expected scenarios or even edge-cases. In our case, we just have to modify our dq_target task with the @task.branch decorator and add logic for the path to choose.
@task.branch
def dq_target():
logging.info("Checking counts in Redshift")
sql = "select count(*) as total_count, sum(case when id is null then 1 else 0 end) as null_count from public.sample"
with create_conn() as conn:
with conn.cursor() as cursor:
logging.info(f">> Executing {sql}")
cursor.execute(sql)
data = cursor.fetchall()
logging.info(data)
#return the name of the task that you need to run based on the condition
if data and data[0][0] > 0 and data[0][1] < 10:
return 'load_target'
else:
return 'notify'
See full example in the GitHub repo.
Test your DAGs with pytest using Astro CLI
Testing your DAGs locally or in lower environments before you deploy to higher environments is one of the important milestone of the data pipeline lifecycle. Using the Astro CLI, Astronomer’s open-source CLI for interacting with local Airflow and Airflow on Astro, you can easily achieve this milestone with the following commands:
astro dev parse: To parse your DAGs and check for any syntax or import errors so that they render successfully in the Airflow UI.astro dev pytest: You can addpytestfor your Airflow DAGs in thetestsdirectory of your Astro project.astro run <your-dag-id> -d dags/<your-dag-file-name>.py: This command will compile your DAG and run in a single Airflow worker container based on your Airflow project’s configuration.
You do not need to have a local Airflow instance running for this; only the Astro CLI is required. For more details on these super useful commands, see Test your DAGs. Keep an eye out for a testing-focused blog post!
Scaling Airflow for data pipelines
As an orchestrator, Airflow has limitless capabilities and flexibility to seamlessly integrate various systems in your data stack. When using a data orchestrator, it is generally recommended to offload storage and compute capabilities onto other tools in you data stack. For example, if you need to process large amount of data using pandas or Polars within your data pipeline or do in-memory computation, your data orchestrator might not handle it and you will have to rely on the compute power of external systems. However, Airflow on Astro doesn’t limit you to this paradigm!
On Astro, scaling Airflow is made easy: teams and organisations can choose a worker size based on their workload, segregate workloads across different types of workers using Worker queues, and auto-scale the number of workers as the number of tasks increases. Workers can also auto-scale to zero when there is no workload! Read how Airflow on Astro uses CeleryExecutor to auto-scale.
Even better, when combined with Kubernetes, Airflow reaches its full potential, providing a robust and scalable task execution framework for data processing. Astro gives you the capability to configure default Pod size from the Cloud UI without changing DAG code and the flexibility to customize individual Pods as well. For more insights, see Constance Martineau’s blog on Leveraging Apache Airflow® and Kubernetes for Data Processing and explore the benefits of Kubernetes Executor available on Airflow on Astro.
Why Airflow on Astro is the best data orchestrator
- Get a serverless Airflow environment up and running in less than 5 minutes!
- With Astro, you can set alerts for DAG or task failures directly from the Cloud UI, without changing your DAG code! See Astro alerts.
- Use Kubernetes Executor for cost and resource efficiency. Airflow on Astro supports both the Celery and Kubernetes Executors, allowing you to switch between them as needed. Read more about these in Astronomer docs.
- Manage your tasks based on resource consumption and fine-tune autoscaling using worker queues.
- Make the maintenance and support operations easier with Astro Observability
- Manage users and teams to assign appropriate roles and permissions using single sign-on (SSO).
You can sign up for a 14-day free trial of Astro and experience these benefits firsthand!
Conclusion
As you can see, migrating your existing Python scripts into Airflow is super simple. You can test these on your local machine within minutes using the Astro CLI. In addition to the benefits of an open-source orchestration tool that provides scheduling and monitoring capabilities, Apache Airflow® is flexible, extensible with plugins and custom operators, and offers world-class community support. Shifting your workloads to Airflow will allow you to manage all aspects of data orchestration from a single pane.
With Airflow on Astro, you can efficiently manage multiple Airflow environments for various teams from a single pane, complete with additional security and optimized auto-scaling. You also gain support from industry Airflow experts, access to Astronomer Academy resources, and benefit from all the modern data orchestration features that enhance the capabilities of your data stack.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.