
Apache Airflow®: The De Facto Standard for Data Workflow Automation.
Apache Airflow® is the open-source standard used by data professionals to author, schedule, and manage workflows as code.
Apache Airflow has become the go-to tool for data engineers, data scientists, and MLOps teams looking to automate complex workflows. Whether you’re managing data pipelines, orchestrating machine learning tasks, or handling cloud-native operations, Airflow provides an intuitive, scalable, and extensible framework to handle it all. In this article, we’ll explore what Apache Airflow is, its key features, how it has evolved, and why it’s critical for modern data ecosystems. Additionally, we’ll show why Astronomer.io is your best resource for mastering Airflow.
What is Airflow? A Comprehensive Guide for 2025
Apache Airflow is a powerful, open-source workflow orchestration tool designed to help users programmatically author, schedule, and monitor workflows. It’s used for creating complex data pipelines that require task orchestration, dependency management, and efficient scheduling across many external tools. This makes it an indispensable asset for data teams seeking to automate and optimize their data pipelines while ensuring data integrity and operational efficiency.
At the heart of Airflow are Directed Acyclic Graphs (DAGs), which represent workflows in Python code. DAGs allow users to visualize tasks and their dependencies, ensuring that the tasks execute in a precise order, handling failures and retries automatically. Because DAGs are written in Python, they are both dynamic and scalable, making Airflow suitable for a wide range of applications, from simple automation tasks to massive data workflows.
History of Apache Airflow
Apache Airflow was initially developed by Maxime Beauchemin at Airbnb in 2014 to handle the company’s growing data pipeline complexity. It was open-sourced in 2015 and graduated to a top-level project in the Apache Software Foundation by 2019. Since then, Airflow has become a critical tool for enterprises across the globe.
Over the years, Airflow has seen significant updates, such as the introduction of dynamic task mapping and dataset-aware scheduling in versions 2.3 and 2.4 all while the Airflow community continues to expand, with thousands of contributors helping to shape its future.
What is Airflow used for?
Airflow has become the de-facto standard for expressing data flows as code with data professionals using it to author, schedule, and manage complex workflows and data pipelines, along with the underlying infrastructure that runs them—whether in the cloud or on-premise.
Airflow’s key features include:
- Pipeline scheduling: Automates workflow execution based on defined schedules.
- Dependency management: Ensures tasks run in the correct order.
- Real-time monitoring: Provides visibility into workflow health and performance.
- Scalability: Handles workflows at any scale, from small to enterprise-level.
These features make Airflow a go-to choice for orchestrating complex, large-scale workflows with the following key benefits:
- Versatility: Integrates with a wide range of tools and cloud services, and allows you to run custom scripts.
- Reliability: Built-in monitoring, alerting, and retry mechanisms ensure workflows run consistently.
- Extensibility: Supports custom operators and plugins for specific needs.
- Transparency: Provides full visibility into pipeline progress and timelines through real-time monitoring.
Learn more about popular Airflow use cases.
Built on a Strong and Growing Community
Key Features of Apache Airflow
1. Workflows as Code (DAGs)
Airflow uses Directed Acyclic Graphs (DAGs) to define tasks and their dependencies in Python. This makes workflows modular, dynamic, and easy to maintain. By coding workflows, users gain flexibility to define complex pipelines dynamically, while enabling software engineering best practices such as version control and CICD.
2. Extensibility
With Airflow’s Python-based architecture, users can extend functionality by writing custom operators, sensors, and hooks, integrating with external APIs, cloud services, or databases. This makes it easy to adapt Airflow to specific workflows and applications.
3. Scalability
Airflow scales effortlessly, from small deployments on a single on-premise server to massive workloads in cloud environments. It supports multiple executors, including Celery and Kubernetes, which allow task distribution across multiple nodes or containers, ensuring high availability.
4. Advanced Scheduling
Airflow supports advanced scheduling capabilities, such as complex timetables, or data-driven scheduling where pipelines run based on updates to user-defined datasets, or waiting for events in external tools with deferrable sensors .
5. User-Friendly Interface
The web-based UI is one of Airflow’s most appreciated features. It provides clear visualizations of DAGs, task statuses, and logs. It’s an essential tool for monitoring, troubleshooting, and managing workflows.
6. Cloud-Native Integration
Airflow integrates seamlessly with cloud platforms such as AWS, Google Cloud, and Azure. With over 1,500 pre-built modules such as operators, hooks and sensors, it simplifies workflow orchestration across diverse environments.
For more information on how Airflow can transform your workflows, check out Astronomer’s Introduction to Apache Airflow and our tutorial to help you get started with Apache Airflow.
Why Apache Airflow is the Future of Data Workflow Automation
Apache Airflow’s flexibility, scalability, and community support have made it the standard for modern data pipeline orchestration. Its growing ecosystem of provider packages, combined with managed platforms like Astronomer’s Astro, make it easier than ever to build, scale, and monitor workflows.
For businesses looking to optimize their data operations, Apache Airflow is the go-to solution. Learn more about how you can leverage Airflow by visiting Astronomer.io, the leading authority in Airflow management and development.
Astro: Your Enterprise Airflow Solution
Astronomer’s Astro is a fully managed platform built on Apache Airflow. Astro simplifies the management of Airflow at scale, offering enterprise-grade observability, governance, and security features. With dynamic scaling and integrated cloud services, Astro enables you to focus on building and running workflows, without worrying about infrastructure.
Whether you’re orchestrating ETL jobs, machine learning pipelines, or data streaming workflows, Astro offers unmatched ease of use and scalability.
Sign up for a free trial of Astro and accelerate your data workflow development.
Getting Started with Airflow
Astro is the fully managed modern data orchestration platform powered by Apache Airflow. Astro augments Airflow with enterprise-grade features to enhance developer productivity, optimize operational efficiency at scale, meet production environment requirements, and more.
Astro enables companies to place Airflow at the core of their data operations, ensuring the reliable delivery of mission-critical data pipelines and products across every use case and industry.
Check out our interactive demo to learn more about Astro.
Why Astro is Ideal for Data Orchestration
Astro builds on Apache Airflow, providing a managed platform that simplifies and scales data orchestration. Astro automates infrastructure management, offers advanced monitoring, and ensures seamless scaling, making it easier to handle large-scale workflows without the operational burden of configuring and maintaining Airflow components. Learn about Modern Data Orchestration with Astro and 10 Best practices for Modern Data Orchestration with Airflow. Our whitepaper on modern full-stack orchestration dives further into the required capabilities needed for any modern data orchestration platform and the transformational results for organizations that apply software engineering best practices to data engineering.
How Astronomer.io and Astro Simplify Data Orchestration
Astronomer.io provides the industry-leading managed service for Apache Airflow, making data orchestration easier and more accessible for teams of any size. With Astro, businesses can leverage the power of Airflow while avoiding the operational overhead of managing their infrastructure. Astro’s features include:
- Fully Managed Infrastructure: Astro automates infrastructure management, ensuring that teams can focus on building workflows rather than managing Kubernetes clusters and networking configurations.
- Dynamic Scaling: Astro automatically scales resources based on the complexity of your data pipelines, ensuring that businesses never have to worry about resource allocation.
- Seamless Cloud Integration: Astro supports multi-cloud and hybrid environments, allowing businesses to orchestrate workflows across different cloud platforms and on-premise systems.
- Advanced Monitoring and Observability: Astro offers comprehensive monitoring tools, providing insights into pipeline performance, task execution, and real-time alerts to ensure that workflows run smoothly and efficiently.
- Security and Governance: Astro includes built-in security features, such as RBAC and audit logging, ensuring that your data is always compliant with regulatory standards.
Best Practices for Airflow Beginners
If you’re just starting with Apache Airflow, follow these essential tips to get the most out of the platform:
- Start Simple: Begin with simple DAGs before progressing to more complex workflows.
- Leverage Pre-Built Operators: Make use of Airflow’s rich ecosystem of pre-built operators and sensors to interact with external tools. You can find pre-built modules in the Astronomer Registry.
- If no pre-built operator exists for your use case, you can easily turn any Python script into an Airflow task using the @task decorator.
- Optimize Scheduling: Use datasets to schedule DAGs based on updates to datasets, this makes sure DAGs run as soon as the necessary data is available.
- Consider using a custom XCom Backend: XComs allow for communication between tasks but only allow for small amounts of data by default. If you want to pass larger amounts of data between Airflow tasks, use a custom XCom Backend.
For more in-depth tips, check out Astronomer’s DAG Writing Best Practices Guide for Apache Airflow or any of the courses in Astronomer Academy. By following these best practices and leveraging managed services like Astro, you can ensure that your workflows are scalable, reliable, and future-proof.
Frequently Asked Questions about Airflow
Airflow basics
What is Airflow? What are its main features?
Apache Airflow is an open-source workflow orchestration tool that automates and schedules complex data pipelines.
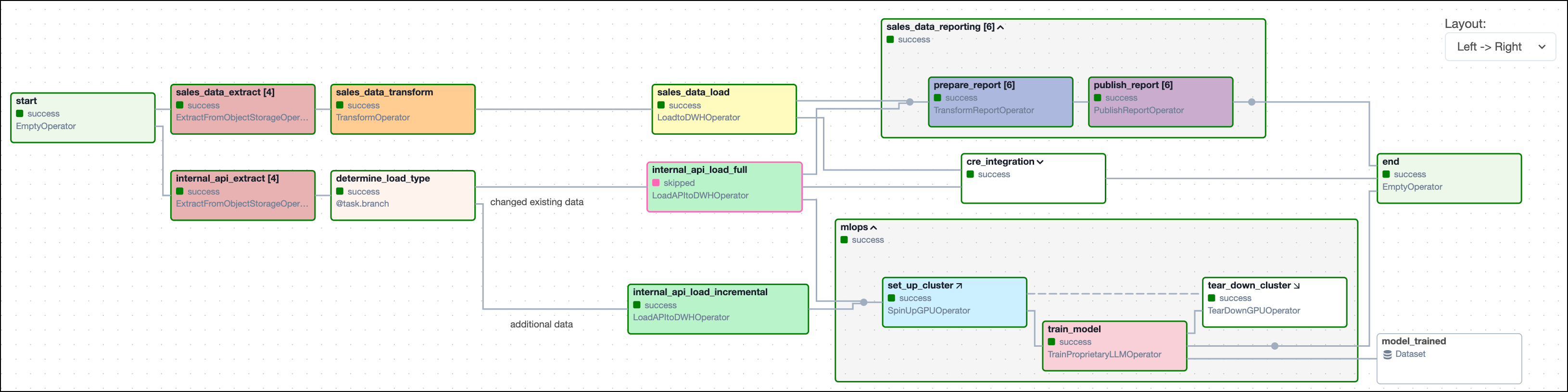
In Airflow, data pipelines and workflows are abstracted as directed acyclic graphs, or DAGs. Hundreds of Airflow operators are the building blocks of DAGs, giving you pre-built functionality you can use to simplify common tasks used to build data products, like running SQL queries or interacting with cloud storage and database services. Additionally, Airflow decorators allow you to effortlessly turn any Python script into an Airflow task, providing you with full flexibility to connect to any tool or service that has an API. You can combine operators and decorators to create DAGs that automate complex pipelines — like integrating newly ingested data from different sources for AI model training and fine-tuning, or pre-processing data from dozens of operational systems for building data driven apps or to provide regulatory reports.
Airflow’s built-in logic allows you to focus on making sure your data pipelines are reliable and performant — without worrying about writing custom code to manage complicated dependencies or recover from pipeline failures.
Why would I choose Airflow over other workflow orchestration tools?
You’d choose Apache Airflow for its flexibility, scalability, and extensive community support. It handles complex workflows with ease, provides pre-built operators to interact with the broadest range of tools (e.g., cloud services, AI frameworks, data processing tools, data warehouses), and enables you to monitor pipeline health and investigate errors in a user-friendly UI. By expressing data flows as intuitive Python code, Airflow can be used across multiple teams composed of data engineers, data analysts and scientists, app developers, and SREs.
Airflow’s open-source nature ensures continuous development and improvement, with the project quickly adapting to changes in the data ecosystem thanks to over 3000 individual contributors to date.
What types of tasks can Airflow automate?
Airflow is the open-source standard for automating repetitive, complex workflows across different environments. Airflow can automate a wide range of tasks, including:
Data pipelines (ETL/ELT): Extracting, transforming, and loading data.
Machine learning workflows: Automating training, evaluation, and deployment of models.
Cloud services: Provisioning and scaling infrastructure.
API calls: Scheduling interactions between systems.
Data processing: Running scripts processing data directly in the Airflow worker or on external distributed computing platforms.
Monitoring and alerting: Automating notifications for failed tasks or data quality issues.
How does Airflow fit into the modern data stack?
Apache Airflow is a key component in the modern data stack, serving as the orchestration layer that connects the tools data teams use to unlock data value. It automates workflows involving data ingestion, transformation, MLOps and analytics by scheduling tasks and managing dependencies.
Airflow integrates seamlessly with tools like dbt, Snowflake, Databricks, ML/AI frameworks, and cloud services, making it essential for building reliable, scalable data pipelines. Its flexibility and extensibility allow it to work with various data platforms and cloud providers, ensuring efficient end-to-end pipeline management.
Who Uses Airflow?
Airflow is popular with data professionals as a solution for automating the tedious work involved in creating, managing, and maintaining data pipelines, along with other complex workflows. Data platform architects depend on Airflow-powered workflow management to design modern, cloud-native data platforms, while data team leaders and other managers recognize that Airflow empowers their teams to work more productively and effectively.
Here’s a quick look at how a variety of data professionals use Airflow.
Airflow and Data Engineers: Data engineers can apply Airflow’s support for thousands of Python libraries and frameworks, as well as the hundreds of pre-built Airflow operators, to create the data pipelines they depend on to acquire, move, and transform data. Airflow’s ability to manage task dependencies and recover from failures allows data engineers to design rock-solid data pipelines.
Airflow and Data Analysts: Data analysts and analytic engineers depend on Airflow to acquire, move, and transform data for their analysis and modeling tasks, tapping into Airflow’s broad connectivity to data sources and cloud services. With optimized, pre-built operators for all popular cloud and on-premises relational databases, Airflow makes it easy to design complex SQL-based data pipelines. Data analysts and analytic engineers can also take advantage of popular open-source Airflow add-ons, like Astronomer Cosmos, which allows them to create Airflow DAGs based on dbt Core projects.
Airflow and Data Scientists: Python is the lingua franca of data science, and Airflow is a Python-based tool for writing, scheduling, and monitoring data pipelines and other workflows. Today, thousands of data scientists depend on Airflow to acquire, condition, and prepare the datasets they use to train their models, as well as to deploy these models to production.
Airflow and Data Team Leads: Data team leaders rely on Airflow to support the work of the data practitioners they manage, recognizing that Airflow’s ability to reliably and efficiently manage data workflows enables their teams to be productive and effective. Data team leads value Airflow’s Python-based foundation for writing, maintaining, and managing data pipelines as code.
Airflow and Data Platform Architects: Airflow-powered workflow management underpins the data layers that data platform architects design to knit together modern, cloud-native data platforms. Data platform architects trust in Airflow to automate the movement and processing of data through and across diverse systems, managing complex data flows and providing flexible scheduling, monitoring, and alerting.
Airflow Technical Considerations
What is the architecture of Apache Airflow?
Apache Airflow’s architecture is modular and composed of several key components that work together to manage workflow orchestration. These components include:
Scheduler: The Scheduler is responsible for determining the execution order of tasks. It orchestrates task dependencies and ensures that tasks are run according to the defined schedule. The DAG Processor is part of the scheduler by default and it is responsible for parsing and processing the DAG files to update task information and schedules.
Workers: Workers execute the tasks defined in the DAGs. Airflow supports different executors to distribute tasks across workers, such as the CeleryExecutor for distributed environments or the KubernetesExecutor for containerized workflows.
Metadata Database: All DAGs, task statuses, and other workflow metadata are stored in a centralized database. The database serves as the source of truth for task states and schedules, and it's essential for tracking the progress of workflows over time.
Web Server (UI): Airflow's web server provides an intuitive, browser-based user interface that allows users to monitor and manage workflows visually. This includes seeing DAG runs, task statuses, logs, and more.
Executor: The executor is a property of the scheduler component that determines where tasks are run. Different executors (e.g., Local, Celery, Kubernetes) determine how tasks are distributed and managed across worker nodes.
What are the key benefits of Airflow’s architecture?
Reliability: High Availability (HA) schedulers in Airflow ensure that the system remains operational even in the event of a failure. By deploying multiple scheduler instances, organizations can achieve redundancy, minimizing downtime.
Modularity: The independent components of the Airflow architecture allow it to scale horizontally and efficiently handle massive workloads when running on Kubernetes.
Extensibility: Users can extend the core functionality with custom operators and plugins.
What are the challenges of Airflow’s architecture?
Complex Scaling: In large-scale environments, managing and scaling Airflow's components (particularly the Scheduler and Workers) can become complex.
High Maintenance: Configuring and maintaining Airflow’s containerized setup, especially in production, requires significant operational effort.
What is the learning curve for Airflow?
For beginners, Airflow requires familiarity with Python and basic concepts of workflow orchestration. For more advanced use cases, you’ll need knowledge about scaling Airflow, data-driven scheduling capabilities, as well as Airflow features allowing dynamically adapting pipelines.
However, with a strong community and extensive documentation, users can quickly gain proficiency and leverage Airflow's flexibility for various workflows. The Astronomer Academy, Astronomer webinars and the Astronomer documentation provide free Airflow courses, demos and guides taught by Astronomer’s Airflow experts.
How scalable is Airflow? Can it handle large volumes of data and tasks?
Apache Airflow is highly scalable and can handle large volumes of data and tasks. In a production setup such as Astro, Airflow can distribute tasks across multiple worker nodes, making it suitable for enterprise-level workflows.
Airflow runs on Kubernetes clusters on Astro, enabling dynamic scaling based on workload demands. Its ability to parallelize tasks and efficiently manage dependencies ensures that even complex, high-volume pipelines can be managed with ease, making it a robust solution for large-scale data engineering and machine learning workflows.
Review the documentation to learn about Airflow scaling best practices.
What are some best practices for designing and maintaining Airflow DAGs?
Best practices for designing and maintaining Airflow DAGs include:
Keep Tasks Atomic: Ideally each task accomplishes one specific action. DAGs designed with atomic tasks give you fine-grained observability into events in your data pipeline and the ability to rerun from the point of failure.
Design idempotent DAGs and Tasks: When backfilling DAGs for earlier dates it is crucial that the same input for individual tasks and DAGs produce the same output in order to benefit from reliable, reproducible orchestration
Modularize your code: Airflow is built on Python code and allows you to modularize commonly used actions in Python functions to be reused in several tasks across DAGs. As in all software engineering, it is a good practice to try not to repeat yourself, if you write the same code twice - consider turning it into a reusable module or even to create your own custom Airflow operator.
Implement Automated Testing: Write unit tests for custom functions and operators, as well as integration and validation tests for your DAGs. Leverage development environments for automatic testing before pushing your code to production.
Handle Failures: Implement automatic retries and alerts for task failures.
Use Version Control: Like all code, DAGs and supporting code like SQL scripts should be stored in version control and be governed by a CI/CD process.
Review the documentation to learn about Airflow DAG best practices.
How does Airflow handle errors and retries in workflows?
Airflow handles errors through built-in mechanisms like retries and alerts. For any failed task, Airflow can automatically retry based on the number of retries and delay between them, which are configurable. You can also set execution timeouts to prevent tasks from running indefinitely. If a task fails even after retries, Airflow can trigger a callback function, commonly sending email or Slack alerts to notify relevant teams. Additionally, the Airflow UI exposes task logs, making it easier to diagnose and fix issues. These features help maintain workflow stability and reliability.
Apache Airflow vs. Astro
How does the architecture of Astro differ from Apache Airflow?
Astro, powered by Astronomer.io, is a fully managed platform built on top of Apache Airflow, offering a more streamlined architecture for enterprises as depicted in the diagram below.
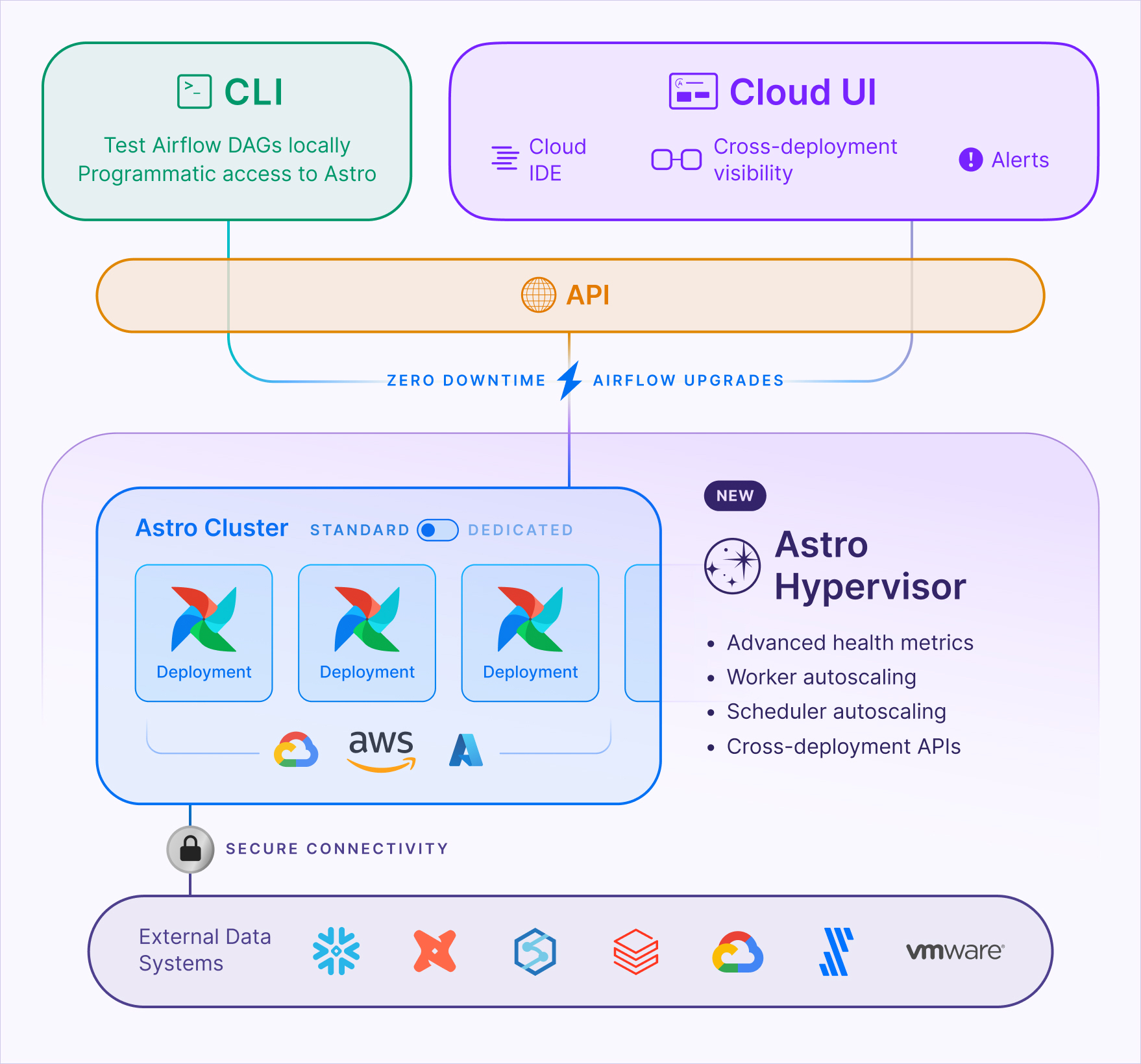
Key differences between the architecture of Astro over Apache Airflow include:
Astro Runtime: Handles all infrastructure management automatically, including scaling, so users don’t have to manually configure the Scheduler, Workers, or Executors.
Dynamic Scaling: Astro adjusts resource allocation dynamically based on workload needs, ensuring tasks run efficiently without over-provisioning resources.
Multi-Environment Support: Astro supports multiple isolated environments (e.g., dev, staging, production) within a single platform with cross-environment observability, unlike self-hosted Airflow, which typically operates in siloed environments.
Enhanced Observability: Provides advanced monitoring, real-time alerts, and dashboards to give better insights into DAG performance.
These enhancements make Astro easier to manage, highly scalable, and ideal for enterprise-level workflows. Learn more about Astro’s architecture and how it helps you manage Airflow on Astro.
What are the benefits of using Astro over standard Apache Airflow?
While Apache Airflow is powerful and flexible, it requires significant operational overhead to manage and scale. Astro offers several advantages:
Simplified Management: Astro automates the configuration, scaling, and maintenance of Airflow components.
Enterprise-Ready: Astro includes advanced security features like role-based access control (RBAC) and audit logging.
Dynamic Scaling: Astro automatically scales resources based on workload demand, optimizing costs and performance.
Multi-Environment Support: Astro allows businesses to easily manage separate environments for development, staging, and production within the same platform.
How does Astro improve scalability compared to Apache Airflow?
Astro's architecture provides dynamic scaling, where the platform automatically allocates resources based on the needs of each DAG. This ensures that workflows run smoothly, even as their complexity grows, without the need for manual configuration or over-provisioning. In contrast, managing scalability in standard Airflow requires careful configuration of executors, workers, and schedulers, which can become operationally complex as workloads increase.
Which businesses should use Astro instead of Apache Airflow?
Businesses that operate at scale, manage multi-cloud environments, or require enhanced security and observability should consider using Astro. With its fully managed infrastructure, automated scaling, and advanced monitoring, Astro is particularly suitable for enterprises running mission-critical workflows that need high availability, compliance, and seamless integrations with cloud services.
For more details on how Astro simplifies Airflow, visit Astronomer.io.
What challenges does Astro solve for Airflow users?
Astro addresses many challenges that come with managing Airflow in production environments:
Operational Complexity: By automating infrastructure management, Astro eliminates the need for manual configuration and scaling of Airflow components.
Scaling Issues: Astro's dynamic scaling ensures that resources are allocated efficiently, even as workflows grow in complexity, preventing bottlenecks and improving performance.
Maintenance Overhead: Astro automates software upgrades and system maintenance, reducing the burden on internal teams and ensuring that users always have access to the latest features and improvements in Airflow.
For more in-depth information on how to leverage Astro for your data orchestration needs, check out the Astro platform.

