Change Data Capture (CDC) in Airflow: A Beginner's Guide
8 min read |
Change Data Capture (CDC) is a term popularized by Bill Inmon, the father of Data Warehousing, to refer to the process of identifying and tracking record-level changes to your operational data. CDC process is a critical component of your data pipelines that keep your data warehouse (DWH) in sync with your operational data store (ODS). This sync between ODS and DWH is crucial to ensure that your key strategic decisions are taken based on the latest data. The frequency of this sync - inter-day, intra-day, or real-time - is one of the primary factors that dictate the terms of your CDC process.
This blog is the first part of two-blog series where we discuss what is CDC, why we need CDC, and how to handle CDC in Airflow with ease.
An Overview: CDC in your Data Stack
Before beginning with what is CDC, let's first understand why do we need CDC and where does it fit in your data stack by looking at some use-cases:
- Consumers interact with a shopping app for groceries, and the marketing team aims to understand the shopping patterns by product and region on a weekly basis in order to effectively to cross-sell new products.
- New products are added to the inventory multiple times a day, and these additions need to be visible to app users in real-time from the UI.
- An access controller for an office space logs users in and out, and the goal is to generate an audit trail of all events for security review.
- A startup has setup a data lake in cloud and wants to bring in the operational data from its main database. They haven’t yet decided on the types of reports they want to generate, but they intend to perform analysis on the raw data, which should be updated in real-time.
As you can observe, a common pattern emerges: data is generated within a source system, and for various business use cases, it needs to be captured and propagated to other data stores downstream, either in batch-mode or streaming mode. The following diagram represents one such example in a classic data pipeline:
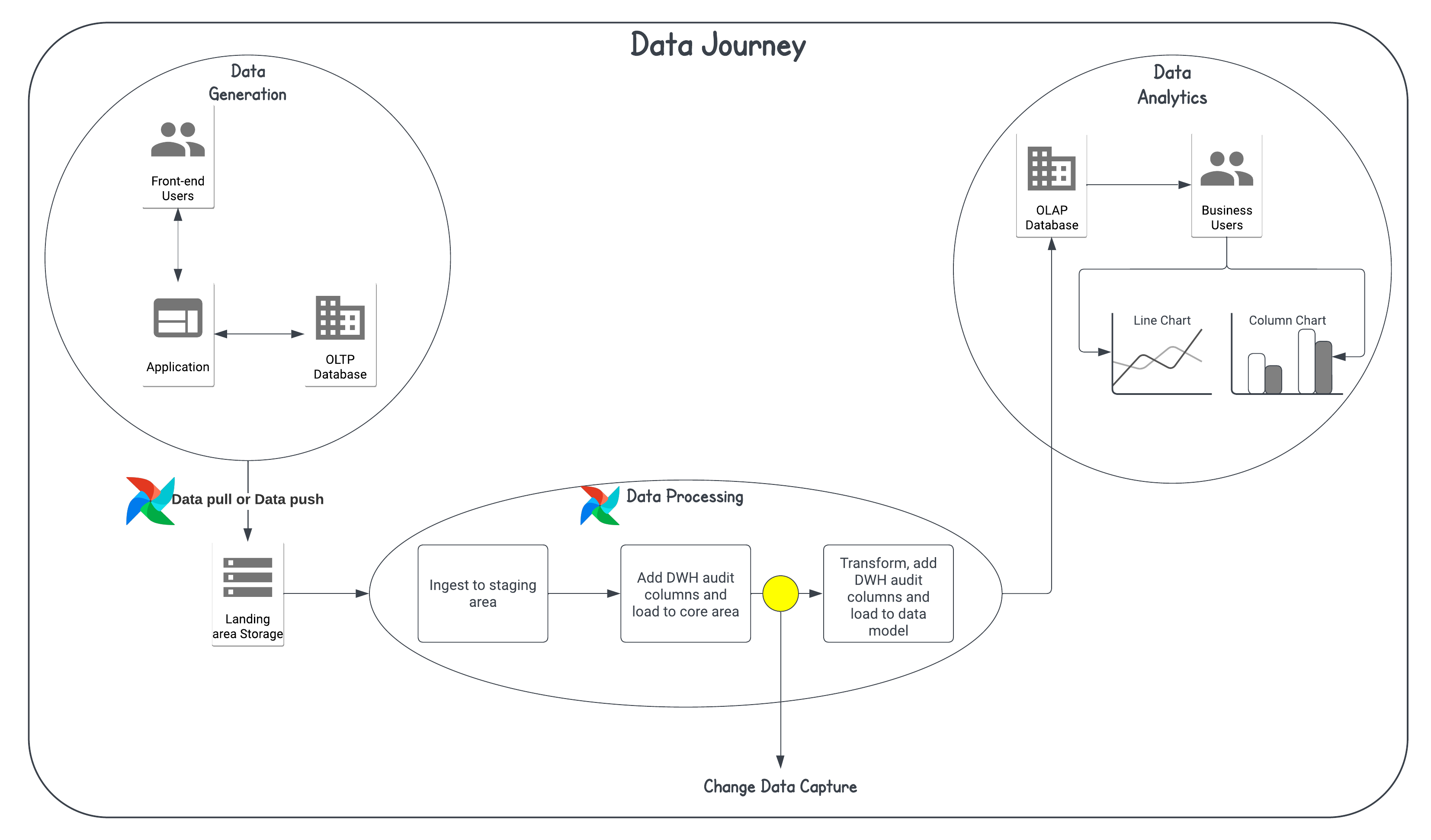
Even though the concept of CDC originated in the context of data warehousing and applying changes in batch mode, today its role has evolved in the data stack. It is widely used to sync changes in real-time or near-real-time from databases like PostgreSQL and MongoDB to non-DWH data stores such as ElasticSearch, data lakes, cloud storage, using a wide variety of tools like Kafka, FiveTran, etc. For the purpose of this blog, we will take a simple example of a data pipeline in Airflow that updates the data from an ODS to DWH using CDC.
Apache Airflow® plays a significant role in this data journey by enabling you to author, schedule, and monitor your data pipelines at scale. Starting with only a basic knowledge of Python and the core components of Airflow, you can achieve a well-balanced combination of a flexible, scalable, extensible, and stable environment that supports a wide range of use-cases. For further insights into the fundamental concepts of Airflow and the reasons for its adoption, refer to the Astronomer documentation.
Data Pipelines and CDC
Let’s consider an example of a shopping app, where basic user actions within the app trigger SQL operations. These SQL operations either generate or update the data in your application’s backend database, which is also referred to as an operational data store (ODS):
- Register a User (
CREATE user ...) - Search for the items (
SELECT \* FROM items ...) - Add an item to cart (
INSERT INTO cart ...) - Remove an item from cart (
DELETE FROM cart ...) - Increase the quantity of an item (
UPDATE cart SET ...) - Place an Order (
INSERT INTO orders ...) - View my Orders (
SELECT FROM orders ...)
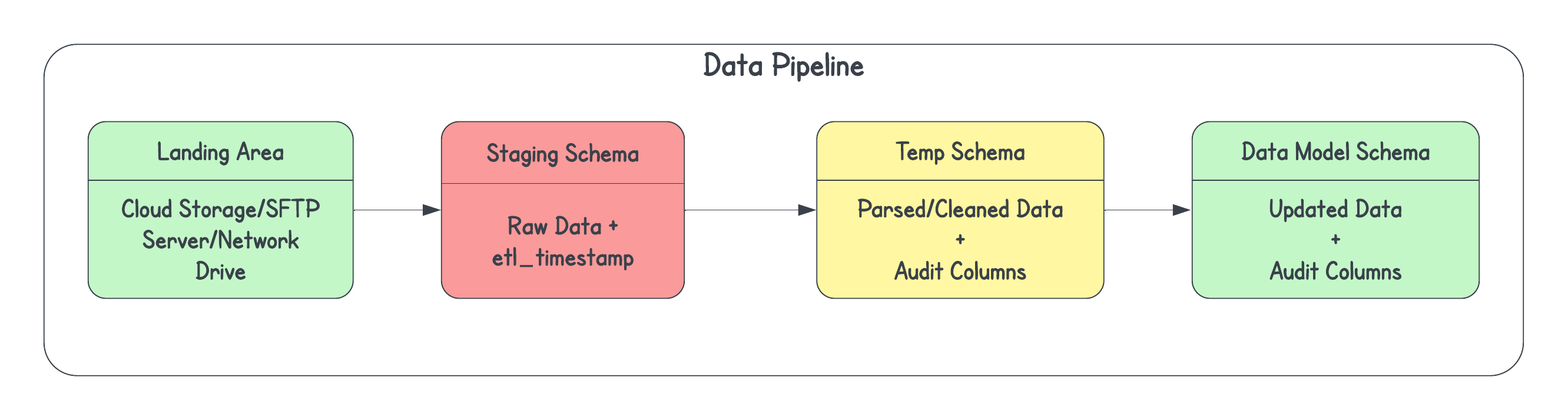
These records from the ODS can be propagated to your DWH to keep them in sync using a data pipeline or a DAG in Airflow’s terminology. Irrespective of the data-processing approach, ETL or ELT, data in a data pipeline goes through distinct stages for processing, each adding value at every step. These stages include cleaning, parsing, transforming, and applying changes to your data, all while incorporating audit columns to track the modifications. These audit columns hold the metadata for each record moving from one stage to another. These audit columns, which contain metadata related to the data movement, play a crucial role in CDC and may vary from one stage to another. Examples of these columns include etl_start_timestamp, etl_end_timestamp, etl_current_ind, etl_key, and more.
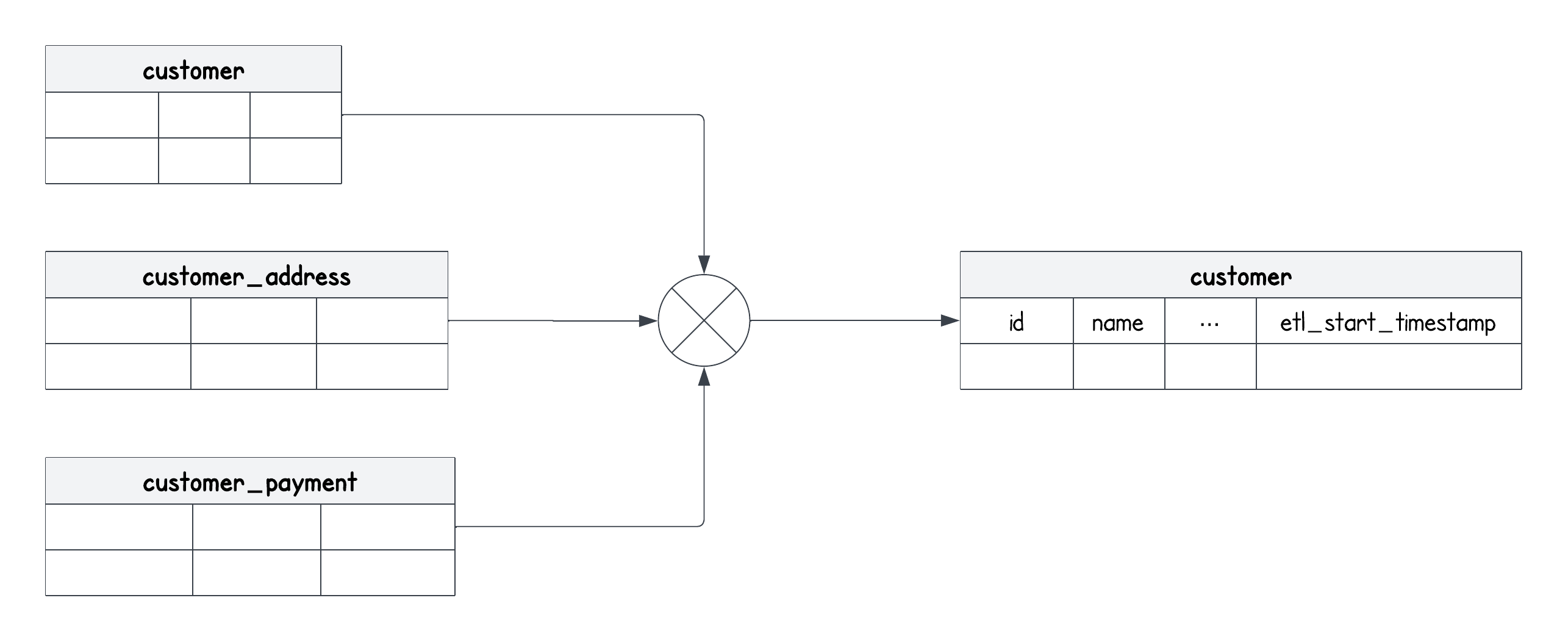
customer, customer_address, customer_payment all contain different data points related to a customer. However, in DWH, we consolidate these into one table called customer, representing a single business entity - commonly referred to as a dimension in a Star Schema.
The data in a data pipeline flows from a source system → target system in the form of records.
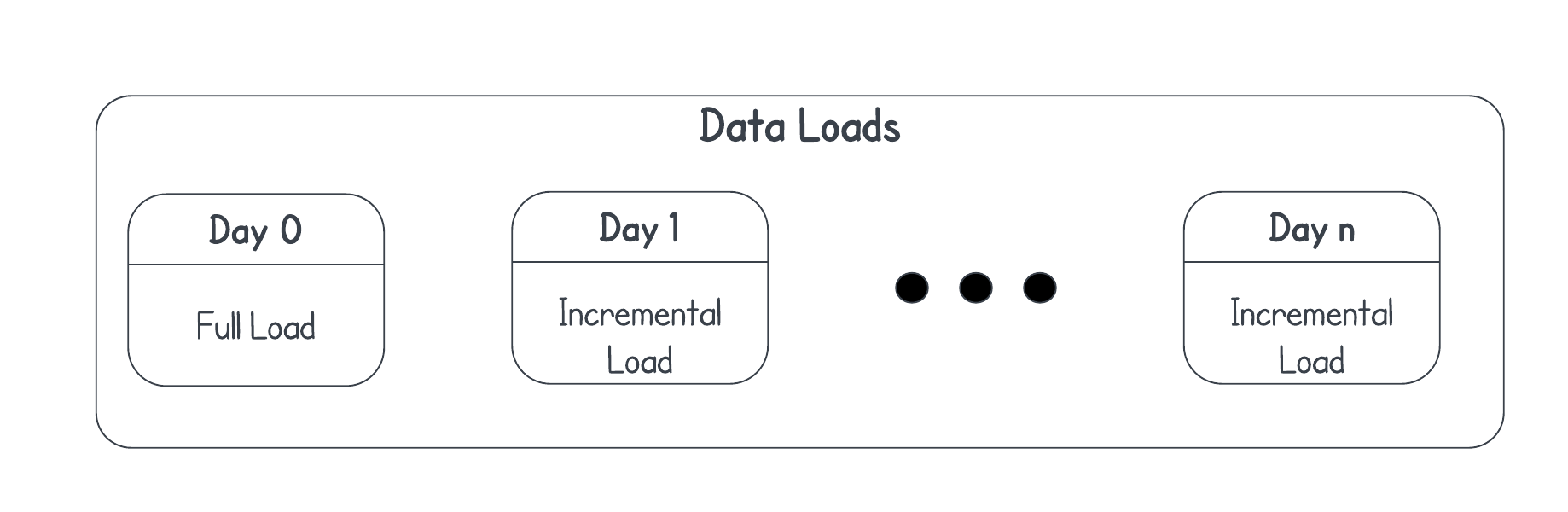
- Source system: The source data can be pulled (or pushed to us by the source system) in two ways:
- Full sync: replicate the dataset in full from source and overwrite the target
- For the first or day 0 run of your data pipeline
- Or in case of discrepancies, when you need to start again
- Incremental sync: identify the changes in the source data based on
created_atorupdated_atand update the target- Using batch processing either at the end-of-business or intra-day
- Using log-based replication (logical replication using WAL logs, Oracle GoldenGate), event-triggers(database triggers or app triggers), data streams (Kafka, Spark Streaming) or message streams (SQS, Rabbit MQ) in real-time or near-real-time
- Target system: The target data can be updated in different ways by the CDC process. Three most common are:
- Overwrite the data in the target table. This typically happens in case of a full sync.
- Append the new records to the target table. For example, appending incremental sync data to a fact table or an audit trail table.
- Upsert (Update and Insert) in the target table. For example, updating/inserting existing records in a Slowly Changing Dimension (SCD) table.
- Update existing records in-place with the new version of the records and insert new records based on a key. (SCD Type 1)
- Insert all records from an incremental sync and mark existing records as inactive based on a key. (SCD Type 2)
Build a CDC Process
Consider the following problem statement: A customer report as of the previous business day should be accessible by 7 AM EDT. This means ensuring the data from the source is processed and made available to the business, reflecting the most recent changes up until yesterday, by 7 AM EDT.
Assuming the following details about our data stack:
- Source database: PostgreSQL
- Target database: Snowflake
- Sync Frequency: Inter-day (Batch)
- Source tables:
customer,customer_address,customer_payment - Target table:
customer - Sync type: Full sync followed by daily incremental syncs based on a
timestampcolumn in source,updated_at - SCD Type: Target table is a SCD Type 2
For example, if a new customer Manmeet registered with an address of my_address_1 and a payment_method of visa, and then updated the values later on, the source tables would look like this:
Source: customer

Source: customer_address

Source: customer_payment

Target: customerType 2 SCD

We will build a simple and reusable Airflow DAG, to take the source tables, each having the ability to run SQL to perform various actions like pull the data from the source database, join and transform the data, and then using the CDC technique to update the target.

With this, we have understood the “what”, “where” and “why” of CDC. In the next and concluding part, we will focus on:
- The implementation details of the CDC process within an Airflow project using Airflow’s custom operators. These custom operators can be packaged, and then re-used like any other Python library to be used across your organization. Learn more about what is an operator and why do we need custom operators.
- Expand our use-case to add a task to ingest the full files or incremental files from a cloud storage and the ability to do backfills.
- CDC implementation based on logical replication in a data lake with no ACID support and also discuss about Lambda architecture.
- Handle schema evolution for the raw tables in a data lake for early analysis.
The Airflow project will be structured as explained in the Astronomer docs.
Before reading the next blog, setup Airflow on your local machine in three steps using Astro CLI and don’t forget to try Airflow on Astro for free!
Click here to read part two.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.