Airflow Best Practices
10 min read |
Streamline your data pipeline workflow and unleash your productivity, without the hassle of managing Airflow.
Start Free TrialWhether you’re just beginning your Apache Airflow® journey or you’re an experienced user looking to maximize data orchestration efficiency, we’ve got you covered. This article sets out ten best practices that will help all Apache Airflow® users ensure their data pipelines run smoothly and efficiently.
Why Airflow?
Data orchestration provides the answer to making your data more useful and available. But it goes beyond simple data management. In the end, orchestration is about using data to drive actions, to create real business value.
— Steven Hillion, VP of Data & Machine Learning at Astronomer
In today's digital economy, the ability to use data more efficiently can generate a significant competitive edge, which is why users turn to Apache Airflow® in the first place. Airflow is an infinitely scalable tool that helps data engineers, scientists, and analysts write and deploy expressive data pipelines.
10 Essential Airflow Best Practices
1. Upgrade to Airflow’s latest version
First and foremost: upgrade to the current version to fully benefit from Apache Airflow®. The Airflow community (including several top committers on our team at Astronomer) is constantly addressing issues and adding new features. Airflow 2.0, introduced in late 2020 and since updated with additional major features by a number of follow-on releases, has improved how enterprises handle orchestration in a material way.
One example: In Airflow 1.10.X, scheduling DAGs often involved struggling with counterintuitive start_date and execution_date attributes. Maybe you wanted to schedule a DAG at different times on different days, or daily except for holidays, or just daily at uneven intervals — all impossible with Airflow 1.10.X. But Airflow 2.0 offers a highly available Scheduler, and the community hasn’t stopped there: new features like custom timetables and richer scheduling intervals are constantly making their way into new releases. Now you can have all the scheduling freedom and flexibility your work requires.
Another big change: Organizations often spend time, money, and resources on operators taking up a full Airflow worker slot for the entire time they are running, which can be especially problematic for long-running tasks. A new feature called deferrable operators solves this problem, allowing operators and sensors to defer until a lightweight async check passes. At this point, they can resume executing. Deferrable operators allow data engineers to run long-running jobs in remote execution environments without hogging a worker slot with an idle worker.

Other vital Airflow 2 features you may be missing out on include full REST API, smart sensors, a standalone CLI command, DAG calendar view, a simplified Kubernetes executor, and more. Moreover, the new 2.0 scheduler eliminated a single point of failure and made Airflow substantially faster. With accelerating numbers of committers — and of organizations implementing Apache Airflow® as part of their modern data stack — new features continue to appear rapidly. Keep track of the latest releases by following the Astronomer blog. You can upgrade Airflow swiftly by visiting the official Apache Airflow® website.
2. Get Familiar with The Core Concepts and Components
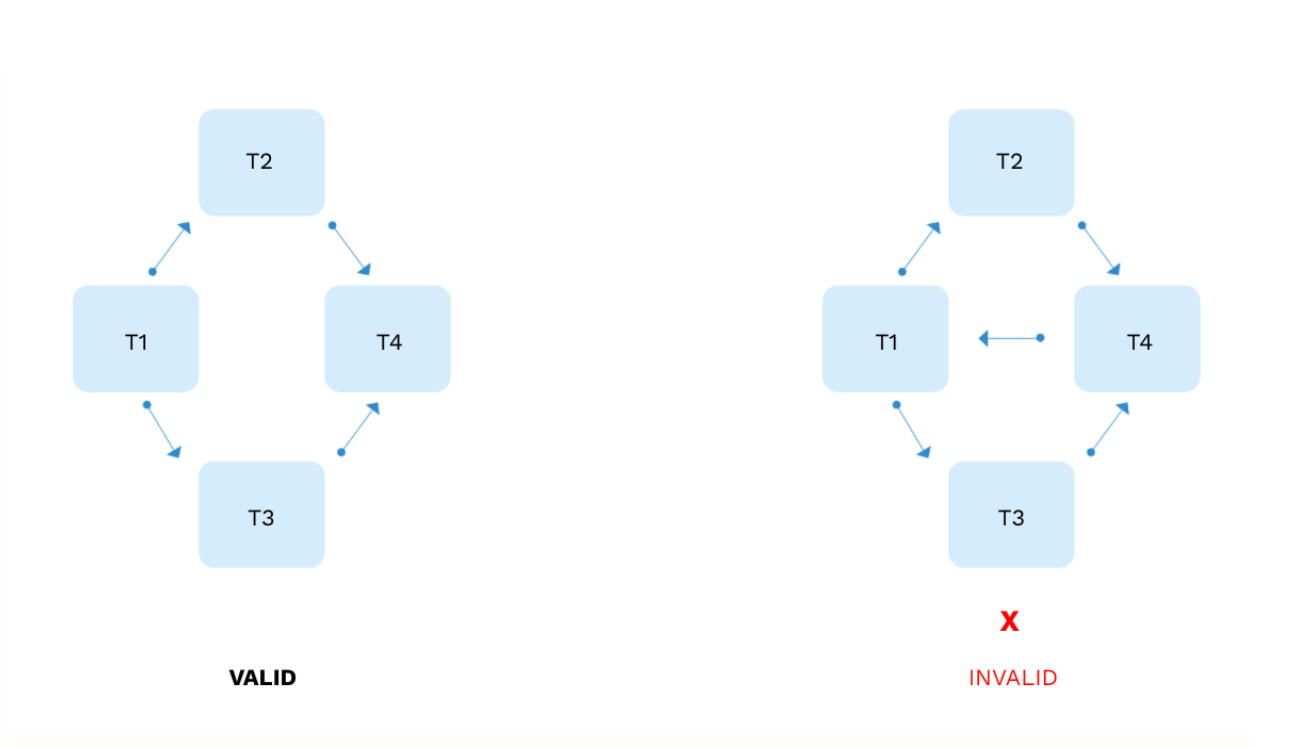
The essential concept Airflow relies on is the DAG (Directed Acyclic Graph), which is the fundamental unit of expression for data pipelines in Airflow. DAGs must flow in one direction, which means that you should always avoid having loops in the code.
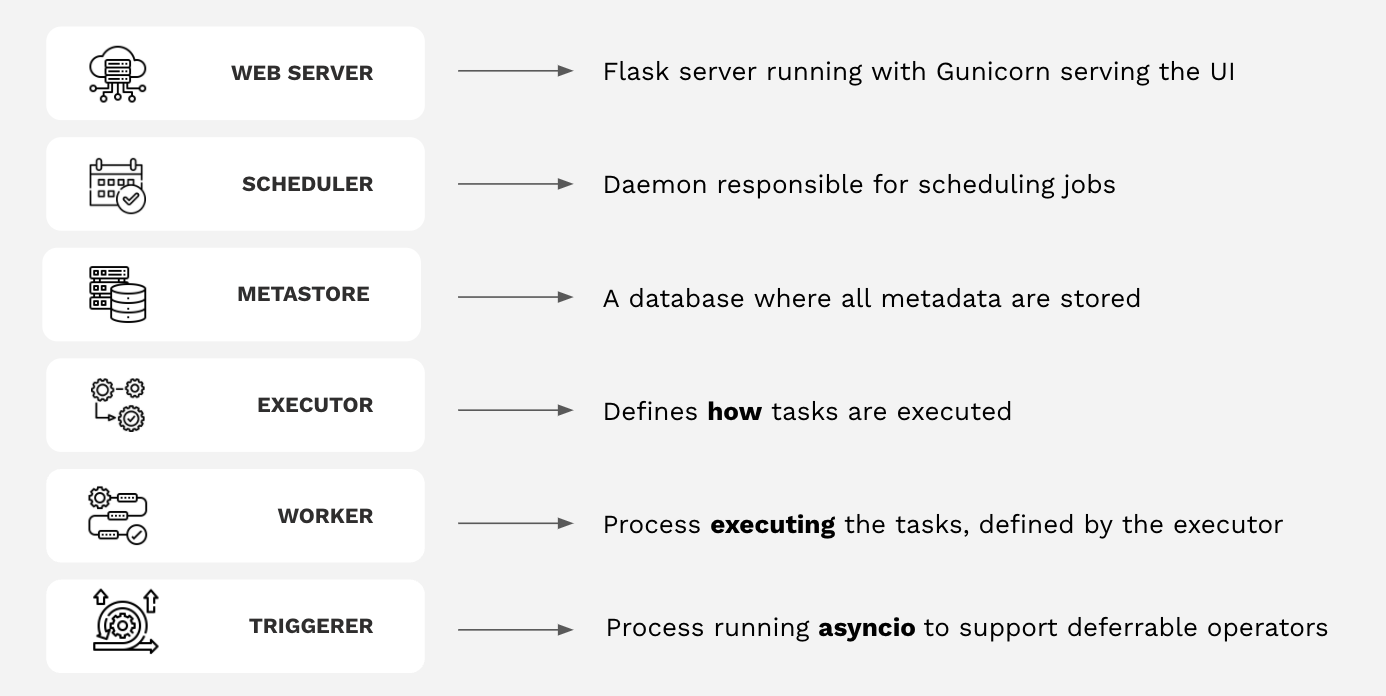
It’s also a good idea to avoid renaming DAGs unless absolutely necessary. Changing the DAG ID of an existing DAG is equivalent to creating a brand new DAG, and Airflow will add a new entry in the metadata database without deleting the old one. This can cause trouble because you will lose the DAG run history, and Airflow will attempt to backfill all the past DAG runs again if catchup is turned on. Learn everything there is to know about DAGs in our extensive guide. And be sure to familiarize yourself with all the core components of Airflow before you start using it. Here’s a cheat sheet:
3. Keep Your DAGs Light — Avoid Top-level Data Processing Inside a DAG
The Airflow scheduler parses DAG files to create DAGs and DAG runs, every 30 seconds by default (you can change this value by setting the scheduler_heartbeat_interval configuration). Given that, long-running code in DAG files can cause performance issues. Keep DAG files as light as possible (like a configuration file). If you are using 2.0 and have complex DAG files, consider running multiple schedulers.
What to avoid? Top-level API calls or database connections in DAG files heavily overburden the scheduler and webserver, so it is advisable to shift top-level calls down to a util/common operator. Always separate the non-configuration-related code blocks outside the DAG definition (you can use the template_searchpath attribute to add those if needed).
4. Process Small Amounts of Data Wisely
Out of the box, Airflow is probably best suited for directly processing only small amounts of data. If you find yourself needing to do more, we suggest the following:
- Use the Kubernetes Executor to isolate task processing and get additional control over resources at the task level.
- Use a custom XCom backend to avoid overloading your metadata database if you need to communicate data between jobs.
- Offload some of the heavier compute to tools like Apache Spark.
5. Keep Your DAG Work Clean and Consistent
This one is crucial: Make sure that when creating your DAGs, you focus on readability and performance. Here are several best practices for achieving that:
- Define one DAG per Python file (except for dynamic DAGs).
- Tag the DAG and make it consistent with your infrastructure’s current tagging system.
- Define one clear purpose for your DAG. Each DAG should have a specific function, such as exporting data to the data warehouse or upgrading your machine learning model in production.
- Keep your pipeline simple, and then see if you can make it even simpler.
6. Focus on Idempotency…
DAG idempotency means that the outcome of executing the same DAG run several times should be the same as the outcome of doing it once. In other words, a DAG run should output the same data no matter how many times it is run. Designing idempotent DAGs decreases recovery time from failures and prevents data loss. Because Airflow may backfill previous DAG runs when catchup is enabled, and each DAG run can be re-done manually at any time, it is critical to ensure that:
- All DAGs are idempotent.
- Each DAG run is independent of the others and the actual run date.
You can use variables and macros to verify that your DAGs are idempotent. Airflow features extensive built-in support for Jinja templating, allowing developers to use numerous valuable variables/macros during runtimes, such as execution timestamps and task information. See our guide on DAG Writing Best Practices to learn more.
7. …and Don’t Forget about Catchup
Catchup is an important element of Airflow's work scheduling. If catchup is enabled, the Airflow scheduler will backfill any previous DAG runs whose time dependency has been met after materializing DAG run entries. If catchup is disabled, DAG runs will be scheduled for all future schedule intervals, and preceding DAG runs will not be scheduled nor appear in the DAG history. The catchup setting can be configured in two ways:
- Airflow cluster level:
catchup_by_default = True(by default) orFalsein the Airflow configuration file, right under theschedulersection. This gets applied to all DAGs unless a different catchup setting is specified on the DAG level. - DAG level:
dag.catchup = TrueorFalsein the DAG file.
Since Airflow may backfill previous DAG runs with enabled catchup, and each DAG run can be rerun manually at any time, it is critical to ensure that DAGs are idempotent and that each DAG run is independent of the others. Get a full grip on the details by reading this short guide on Rerunning DAGs.
8. Set up Retries and Custom Alerts
Even if your code is impeccable, failures will happen. The first answer to this problem is simple: task retries. A best practice is to set retries as a default_arg, so they are applied at the DAG level and get more granular for specific tasks only when necessary. An Astronomer-recommended range to try is ~3 retries.
Of course, constantly checking the UI for failures (and failed retries) isn't great for production, so Airflow allows you to set up real-time failure alerts and notifications.
You can set notifications:
- At the DAG level — they will be inherited by every task.
- At the task level — if you need more specific control.
Alerts can be sent to anything with an API, such as Slack or email. The easiest way to define custom notifications within Airflow is by using the following functions:
on_failure_callbackon_success_callback
Notifications can be based on any number of different events, can be sent via multiple methods and to any number of various systems. Check out our guide on Airflow notifications for more.
9. Take Advantage of Provider Packages
Airflow’s vibrant and dedicated community has created many integrations between Airflow and the wider data ecosystem. As a result, you can coordinate Airflow with third-party tools and services — from NiFi, Beam, and Snowflake to AWS, Google Cloud, and Azure — using provider packages while writing very little code. It’s a best practice to check if the functionality you’re after already exists in a provider package — and, if it does, to use that rather than writing your own Python Operators. Airflow contributors have already done a lot of the heavy lifting for you. Head to the Astronomer Registry to review the wide array of provider packages.
10. Stay Consistent to Democratize Your Data Stack
Always use a consistent project structure and standards for writing your DAGs. A consistent structure will make your project easier to organize and adapt (e.g., new users will know where to place things like SQL files, config files, and things like Python dependencies). At Astronomer, we use:
├── dags/ # Where your DAGs go
├── example-dag.py # An example dag that comes with the initialized project
├── Dockerfile # For Astronomer's Docker image and runtime overrides
├── include/ # For any other files you'd like to include
├── plugins/ # For any custom or community Airflow plugins
├── packages.txt # For OS-level packages
└── requirements.txt # For any Python packagesIt’s also important to be consistent in task dependencies. In Airflow, task dependencies can be set in a couple of ways. You can use set_upstream() and set_downstream() functions, or you can use << and >> operators. The approach you choose is up to you, but for readability, it's a best practice to pick one and stay with it. In the DAGs themselves, be sure to standardize syntax for setting dependencies, using the Taskflow API, and other patterns within the DAGs.
For example, instead of mixing methods like this:
task_1.set_downstream(task_2) task_3.set_upstream(task_2) task_3 >> task_4
Try to be consistent, like this:
task_1 >> task_2 >> [task_3, task_4]
Using the same approach will help everybody on your team and across your organization. It will make it easier for anyone, including non-engineers, to gather data and make data-driven decisions. Being consistent helps democratize your data stack.
Trust Astronomer with your data orchestration
The Astronomer framework takes Apache Airflow® to the next level. We allow you to instantly deploy the most up-to-date version of Airflow, with the latest features, so your team can focus on data pipelines. Our optimized infrastructure reacts to peaks and valleys in demand with instant auto-scaling. The Astronomer Registry — a library of reusable, productivity-boosting integrations, DAGs, and components — is valued by data engineers the world over. And the Astronomer team is ready to support you with any issues.
You can trust Astronomer to provide the Airflow expertise and resources you need to make things happen for your organization. Mark George, VP of Data & Analytics at our client Herman Miller, recently summed up the impact that working with us on Airflow can have for a business: "We are not focusing on the technology anymore", says Mark. "Airflow has allowed us to focus on using the data and making the most of it."
Get in touch with our experts to discuss further how Airflow and Astronomer can accelerate your data strategy in 2022.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.