Introducing Airflow 2.0
15 min read |
Note: With the release of Airflow 2.0 in late 2020, and with subsequent releases, the open-source project addressed a significant number of pain points commonly reported by users running previous versions. We strongly encourage your team to upgrade to Airflow 2.x. If your team is running Airflow 1 and would like help establishing a migration path, reach out to us. Note: This article focuses mainly on Airflow 2.0. If you’d like to learn more about the latest features, head over to the articles about Airflow 2.2 and Airflow 2.3.
Apache Airflow® was created by Airbnb’s Maxime Beauchemin as an open-source project in late 2014. It was brought into the Apache Software Foundation’s Incubator Program in March 2016, and saw growing success in the wake of Maxime’s well-known blog post on “The Rise of the Data Engineer.” By January of 2019, Airflow was announced as a Top-Level Apache Project by the Foundation, and it is now widely recognized as the industry’s leading workflow orchestration solution.
Airflow’s strength as a tool for dataflow automation has grown for a few reasons:
- Proven core functionality for data pipelining. Airflow competitively delivers in scheduling, scalable task execution, and UI-based task management and monitoring.
- An extensible framework. Airflow was designed to make data integration between systems easy. Today it supports more than 70 providers, including AWS, GCP, Microsoft Azure, Salesforce, Slack, and Snowflake. Its ability to meet the needs of simple and complex use cases alike make it both easy to adopt and scale.
- A large, vibrant community. Airflow boasts tens of thousands of users and more than 2,000 contributors who regularly submit features, plugins, content, and bug fixes to ensure continuous momentum and improvement. In 2022, Airflow reached 15K+ commits and 25K+ GitHub stars.
As Apache Airflow® grew in adoption, a major release to expand on the project’s core strengths came to be long overdue. As committed members of the community, we at Astronomer were delighted to announce the release of Airflow 2.0 by the end of 2020.
Throughout 2020, various organizations and leaders within the Airflow Community collaborated closely to refine the scope of Airflow 2.0, focusing on enhancing existing functionality and introducing changes to make Airflow faster, more reliable, and more performant at scale. In celebration of the highly anticipated release, we’ve put together an overview of major Airflow 2.0 features below.
Major Features in Airflow 2.0
Airflow 2.0 includes hundreds of features and bug fixes both large and small. Many of the significant improvements were influenced and inspired by feedback from Airflow’s 2019 Community Survey, which garnered over 300 responses.
A New Scheduler: Low-Latency + High-Availability
The Airflow Scheduler as a core component has been key to the growth and success of the project since its creation in 2014. As Airflow matured and the number of users running hundreds of thousands of tasks grew, however, we at Astronomer came to see great opportunity in driving a dedicated effort to improve on Scheduler functionality and push Airflow to a new level of scalability.
In fact, “Scheduler Performance” was the most asked for improvement in the Community Survey. Airflow users had found that while the Celery and Kubernetes Executors allowed for task execution at scale, the Scheduler often limited the speed at which tasks were scheduled and queued for execution. While effects varied across use cases, it was not unusual for users to grapple with induced downtime and a long recovery in the case of a failure and experience high latency between short-running tasks. It was for that reason we introduced a new, refactored Scheduler with the Airflow 2.0 release. The most impactful Airflow 2.0 change in this area is support for running multiple schedulers concurrently in an active/active model. Coupled with DAG Serialization, Airflow’s refactored Scheduler is now highly available, significantly faster and infinitely scalable. Here’s a quick overview of new functionality:
- Horizontal Scalability. If task load on one Scheduler increases, a user can now launch additional “replicas” of the Scheduler to increase the throughput of their Airflow Deployment.
- Lowered Task Latency. In Airflow 2.0, even a single scheduler has proven to schedule tasks at much faster speeds with the same level of CPU and Memory.
- Zero Recovery Time. Users running 2+ Schedulers will see zero downtime and no recovery time in the case of a failure.
- Easier Maintenance. The Airflow 2.0 model allows users to make changes to individual schedulers without impacting the rest and inducing downtime.
The Scheduler’s now-zero recovery time and readiness for scale eliminates it as a single point of failure within Apache Airflow®. Given the significance of this change, our team published “The Airflow 2.0 Scheduler”, a blog post that dives deeper into the story behind Scheduler improvements alongside an architecture overview and benchmark metrics.
For more information on how to run more than one Scheduler concurrently, refer to the official documentation on the Airflow Scheduler.
Full REST API
Before 2.0, data engineers had been using Airflow’s “Experimental API” for years, most often for triggering DAG runs programmatically. The API had historically remained narrow in scope and lacked critical elements of functionality, including a robust authorization and permissions framework.
Airflow 2.0 introduced a new, comprehensive REST API that set a strong foundation for a new Airflow UI and CLI in the future. Additionally, the new API:
- Makes for easy access by third-parties
- Is based on the Swagger/OpenAPI Spec
- Implements CRUD (Create, Update, Delete) operations on all Airflow resources
- Includes authorization capabilities (parallel to those of the Airflow UI)
These capabilities enable a variety of use cases and create new opportunities for automation. For example, users now have the ability to programmatically set Connections and Variables, show import errors, create Pools, and monitor the status of the Metadata Database and Scheduler.
For more information, refer to Airflow’s REST API documentation.
Smart Sensors
Note: Smart Sensors have been deprecated and replaced with Deferrable Operators in the latest Airflow 2 releases.
In the context of dependency management in Airflow, it’s been common for data engineers to design data pipelines that employ Sensors. Sensors are a special kind of Airflow Operator whose purpose is to wait on a particular trigger, such as a file landing at an expected location or an external task completing successfully. Although Sensors are idle for most of their execution time, they nonetheless hold a “worker slot” that can cost significant CPU and memory.
The “Smart Sensor” introduced in Airflow 2.0 is an “early access” (subject to change) foundational feature that:
- Executes as a single, “long running task”
- Checks the status of a batch of Sensor tasks
- Stores sensor status information in Airflow’s Metadata DB
This feature was proposed and contributed by Airbnb based on their experience running an impressively large Airflow Deployment with tens of thousands of DAGs. For them, Smart Sensors reduced the number of occupied worker slots by over 50% for concurrent loads in peak traffic.
TaskFlow API
While Airflow has historically shined in scheduling and running idempotent tasks, before 2.0 it lacked a simple way to pass information between tasks. Let’s say you are writing a DAG to train some set of Machine Learning models. A first set of tasks in that DAG generates an identifier for each model, and a second set of tasks outputs the results generated by each of those models. In this scenario, what’s the best way to pass output from that first set of tasks to the second? Historically, XComs have been the standard way to pass information between tasks, and would be the most appropriate way to handle the use case above. As most users know, however, XComs are often cumbersome to use and require redundant boilerplate code to set return variables at the end of a task, and retrieve them in downstream tasks.
With Airflow 2.0, we introduced the TaskFlow API and Task Decorator to address this challenge. The TaskFlow API implemented in 2.0 makes DAGs significantly easier to write by abstracting the task and dependency management layer from users. Here’s a breakdown of incoming functionality:
- A framework that automatically creates PythonOperator tasks from Python functions and handles variable passing. Now, variables such as Python Dictionaries can simply be passed between tasks as return and input variables for cleaner and more efficient code.
- Task dependencies are abstracted and inferred as a result of the Python function invocation. This again makes for much cleaner and simpler DAG writing for all users.
- Support for Custom XCom Backends. Airflow 2.0 includes support for a new xcom_backend parameter that allows users to pass even more objects between tasks.
It’s worth noting that the underlying mechanism here is still XCom and data is still stored in Airflow’s Metadata Database, but the XCom operation itself is hidden inside the PythonOperator and is completely abstracted from the DAG developer. Now, Airflow users can pass information and manage dependencies between tasks in a standardized Pythonic manner for cleaner and more efficient code.
To learn more, refer to Airflow documentation on the TaskFlow API and the accompanying tutorial.
Task Groups
Airflow SubDAGs were long limited in their ability to provide users with an easy way to manage a large number of tasks. The lack of parallelism coupled with confusion around the fact that SubDAG tasks can only be executed by the Sequential Executor, regardless of which Executor is employed for all other tasks, made for a challenging and unreliable user experience.
Airflow 2.0 introduced Task Groups as a UI construct that doesn’t affect task execution behavior but fulfills the primary purpose of SubDAGs. Task Groups give a DAG author the management benefits of “grouping” a logical set of tasks with one another without having to look at or process those tasks any differently.
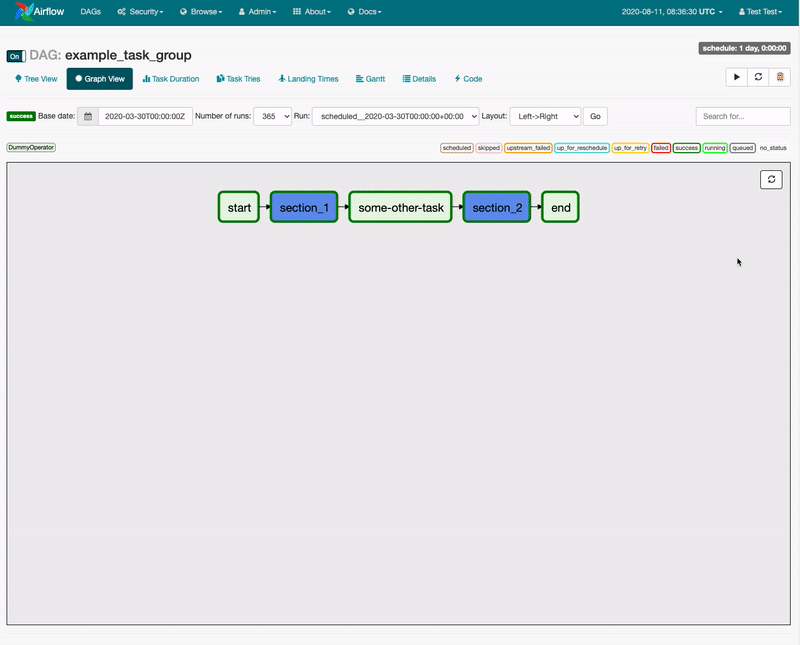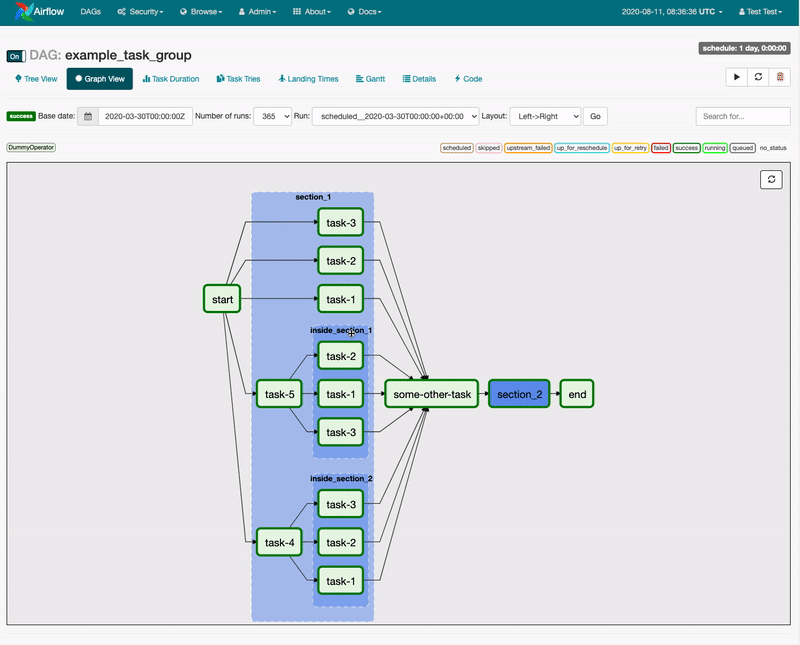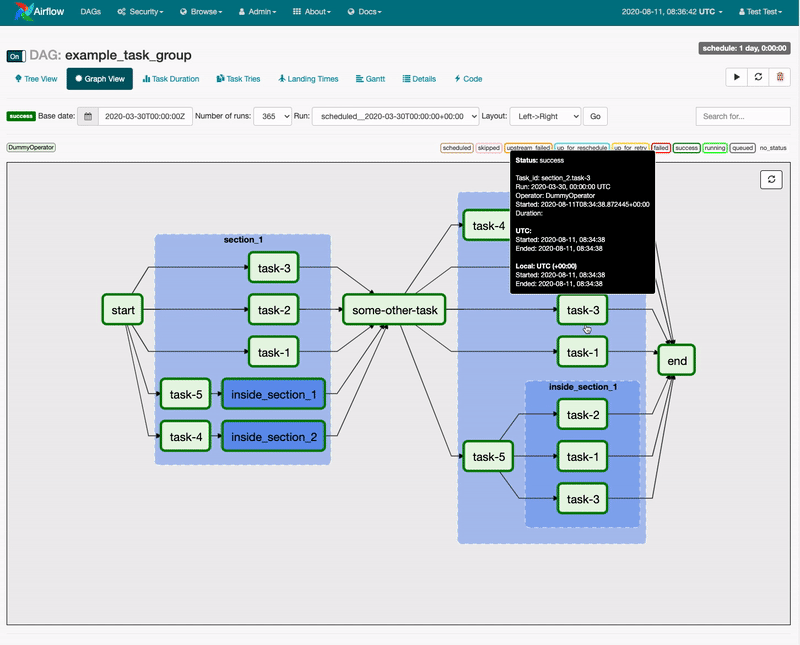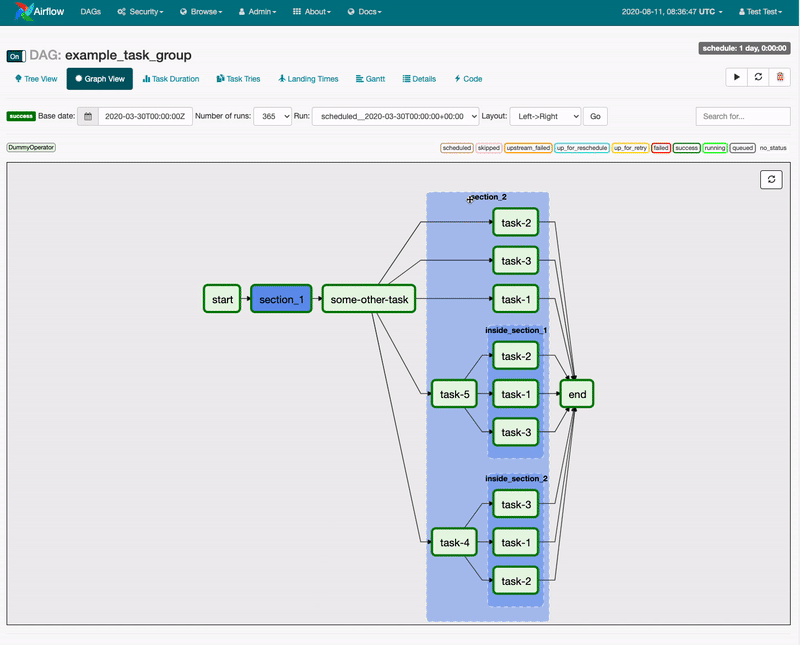
While Airflow 2.0 continues to support the SubDAG Operator, Task Groups are intended to replace it in the long-term.
Independent Providers
One of Airflow’s signature strengths is its sizable collection of community-built Operators, Hooks, and Sensors that enable users to integrate with external systems like AWS, GCP, Microsoft Azure, Snowflake, Slack, and many more.
Providers have historically been bundled into the core Airflow distribution and versioned alongside every Apache Airflow® release. As of Airflow 2.0, they are split into its own airflow/providers directory such that they can be released and versioned independently from the core Apache Airflow® distribution. Cloud service release schedules often don’t align with the Airflow release schedule, which either results in incompatibility errors or prohibits users from being able to run the latest versions of certain providers. The separation in Airflow 2.0 allows the most up-to-date versions of Provider packages to be made generally available and removes their dependency on core Airflow releases.
It’s worth noting that given their widespread usage, some operators, including the Bash and Python Operators, remain in the core distribution.
To learn more, refer to Airflow documentation on Provider Packages.
Simplified Kubernetes Executor
Airflow 2.0 includes a re-architecture of the Kubernetes Executor and KubernetesPodOperator, both of which allow users to dynamically launch tasks as individual Kubernetes Pods to optimize overall resource consumption.
Given the known complexity users previously had to overcome to successfully leverage the Executor and Operator, we drove a concerted effort toward simplification that ultimately involved removing over 3,000 lines of code. The changes incorporated in Airflow 2.0 made the Executor and Operator easier to understand and faster to execute , and offered far more flexibility in configuration.
Data Engineers now have access to the full Kubernetes API to create a yaml ‘pod_template_file’ instead of being restricted to a partial set of configurations through parameters defined in the airflow.cfg file. We’ve also replaced the executor_config dictionary with the pod_override parameter, which takes a Kubernetes V1Pod object for a clear 1:1 override setting.
For more information, we encourage you to follow the documentation on the new pod_template file and pod_override functionality.
UI/UX Improvements
Perhaps one of the most welcomed sets of changes brought by Airflow 2.0 has been the visual refresh of the Airflow UI.
In an effort to give users a more sophisticated and intuitive front-end experience, we made more than 30 UX improvements, including a new “auto-refresh” toggle in the “Graph” view that enables users to follow task execution in real-time without having to manually refresh the page (commit). (Since Airflow 2.2 users don’t need to use a toggle anymore, as the page refreshes automatically when the task is running.)
Other highlights include:
- A refreshed set of icons, colors, typography, and top-level navigation (commit)
- Separation of actions + links in DAG navigation (commit)
- A button to reset the DAGs view (home) after performing a search (commit)
- Refactored loading of DAGs view (e.g. remove “spinning wheels) (commit)
- Many more Airflow UI changes are expected beyond Airflow 2.0, but we’re certainly excited to have gotten a head start. To learn more, refer to Airflow documentation on the Airflow UI.
Major Features in Airflow 2.2 and 2.3
Airflow 2.2
Airflow 2.3
- Dynamic task mapping lets Airflow trigger tasks based on unpredictable input conditions
- A new, improved grid view that replaces the tree view
- A new LocalKubenetesExecutor you can use to balance tradeoffs between the LocalExecutor and KubernetesExecutor
- A new REST API endpoint that lets you bulk-pause/resume DAGs
- A new listener plugin API that tracks TaskInstance state changes
- New ability to store Airflow connections in JSON instead of URI format
- A new command built into the Airflow CLI that you can invoke to reserialize DAGs
Learn more about the latest features in Airflow 2.3.
Apache Airflow® 1.10 vs. Apache Airflow® 2.0
Apache Airflow® 2.0 didn’t only bring some amazing new features — the data architecture layer changed too! Let’s have a look at how it compares with Airflow 1.10.
A common workflow for processing files is dropping them into an S3 bucket and performing a 3-step process for each file (before they’re inserted into a data warehouse and used by data analysts). Imagine such a case where the pipeline has to run every 30 minutes, and occasionally can be triggered on an ad-hoc basis (through an API).
Even though this workflow is very common, there are a lot of places it can go wrong on Airflow 1.10. Here’s why:
- With 1.10, you’d need to use a Subdag to make the UI clean when you’re showing the process. However, Subdags can be hard to manage.
- You might want to trigger it on an ad-hoc basis from the API, but the API isn’t officially supported in Airflow 1.10.
- If you used community-supported operators for your DAGs, you’d have to upgrade your entire Airflow environment, because they are tightly coupled on 1.10.
- Scheduling on Airflow 1.10 can cause SLA delays when you try to run on a massive scale.
- Airflow 1.10 has the web server parse DAGs, meaning it needs more resources as you add more workloads.
- Whatever bits of data you’d want to pass back and forth through an XCOM, the Airflow 1.10 XCOMs are pretty limited in their scope. They have to be stored within the Airflow database and can’t be externalized.
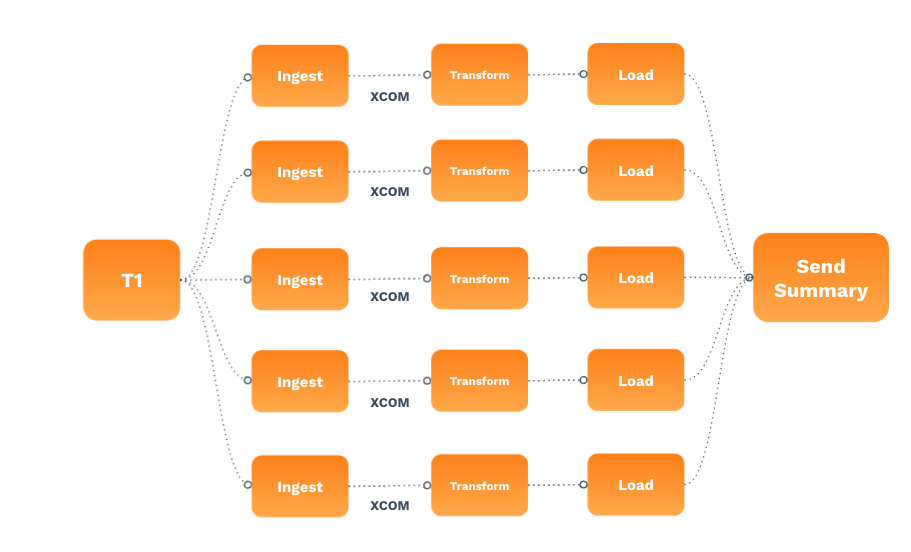
As you can see, as great as Airflow 1.10 is, it has some limitations.
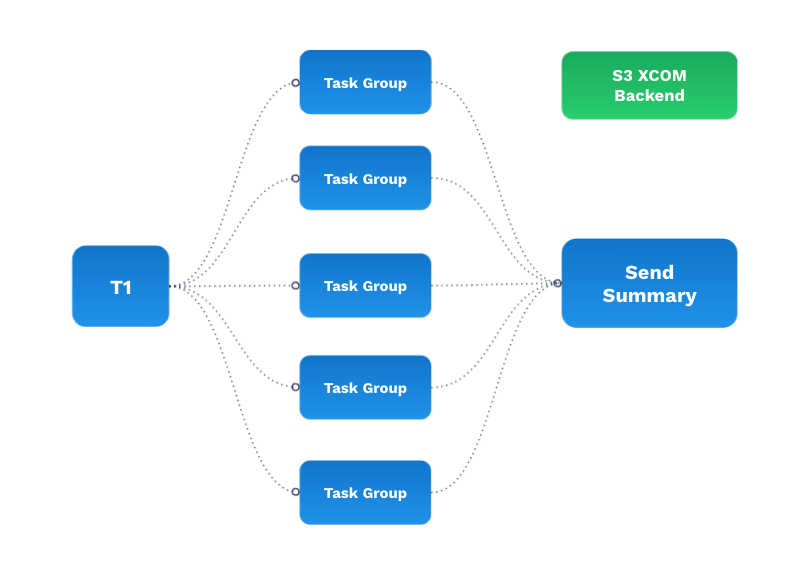
Luckily, all that’s different in Airflow 2.0:
- The API is fully supported with more endpoints than ever, so you can trigger it on an ad-hoc basis.
- The community operators that you’re using can be versioned independently of Airflow (if you just want to make a slight change to your community operator you can upgrade it without upgrading all of Airflow).
- As a data infrastructure engineer or a DevOps engineer, you don’t have to upgrade Airflow frequently, because your data engineers can upgrade the providers, the hooks, and operators on their own.
- The scheduler is 20 times better on Airflow 2.0 and you can add more than one. As your number of files or the frequency with which you want to run your DAG increases, the scheduler can keep up.
- The UI is stateless because all your DAGs in Airflow 2.0 are serialized in the database, so that you don’t have to spend resources cracking up your web server.
- Lastly, you can use external storage like S3 for your XCOMs so that if you want to pass large amounts of data back and forth you can do that with a clean developer experience, without maintaining extra overhead. Plus, the data is backed up in S3, which is infinitely scalable.

Get Started With Airflow 2.x
Astronomer’s open-source CLI is the best way to test Airflow 2.x on your local machine as you prepare to migrate. For guidelines, refer to Get Started with Airflow 2.0.
For detailed instructions on the upgrade process, refer to Upgrading to Airflow 2.0+ from the Apache Airflow® Project and Upgrade to Airflow 2.0 on Astronomer if you’re running on our platform.
Get Involved
We’re thrilled to have shared Airflow 2.0 with the community. The features outlined above create an exciting foundation on top of which developers all over the world have gone on to build.
If you’re interested in getting involved with the wider community, we encourage you to sign up for the Dev Mailing List or join the Apache Airflow® Community in Slack. For real-time announcements and updates, follow Astronomer and ApacheAirflow on Twitter.
Finally, please join us in sincerely thanking the many Airflow contributors who worked tirelessly to reach this milestone. In no particular order, a huge thank you goes out to: Ash Berlin-Taylor, Kaxil Naik, Jarek Potiuk, Daniel Imberman, Tomek Urbaszek, Kamil Breguła, Gerard Casas Saez, Kevin Yang, James Timmins, Yingbo Wang, Qian Yu, Ryan Hamilton and the hundreds of others for their time and effort into making Airflow what it is today.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.