Schedule DAGs in Apache Airflow®
Schedule DAGs in Apache Airflow®
One of the fundamental features of Apache Airflow® is the ability to schedule DAGs. Airflow offers many different options for scheduling, from simple cron-based schedules, over data-aware scheduling with assets to event-driven scheduling based on messages in a queue.
In this guide, you’ll learn:
- How to interpret the timestamps associated with a DAG run.
- How to set DAG parameters that control scheduling.
- The options available for scheduling DAGs.
This guide gives an overview of scheduling options. There are a number of related guides that cover specific types of scheduling in more detail:
- Assets and data-aware scheduling
- Event-driven scheduling
- Rerun Airflow DAGs and tasks (including backfilling)
Assumed knowledge
To get the most out of this guide, you should have an existing knowledge of:
- Basic Airflow concepts. See Introduction to Apache Airflow.
- Airflow DAGs. See Introduction to Airflow DAGs.
- Date and time modules in Python3. See the Python documentation on the
datetimepackage and thependulumdocumentation.
DAG run timestamps
A DAG run is a single execution of a DAG attached to a point in time. On the DAG run details page you can see different timestamps associated with your DAG run.
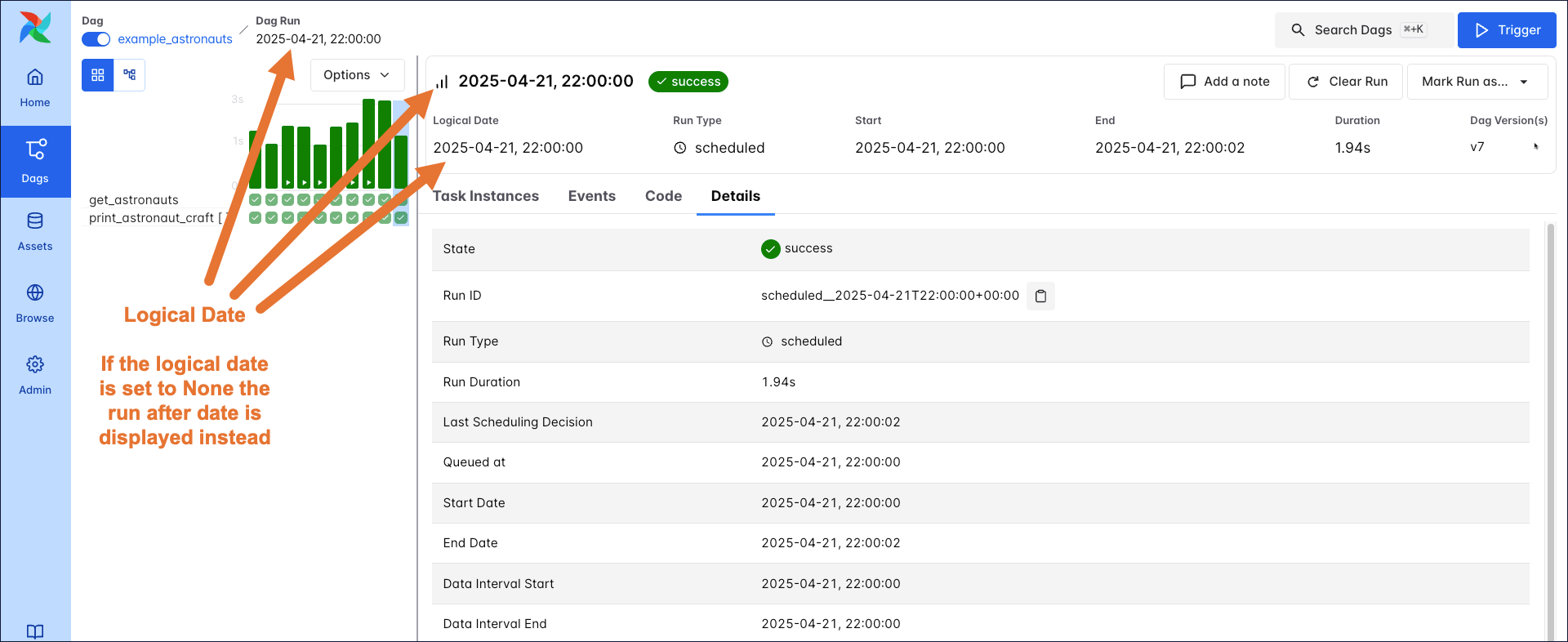
- Logical Date: The point in time after which a specific DAG run can start. This timestamp is displayed prominently in the Airflow UI as the main date the DAG run is associated with. The logical date can be set to
Noneby the user for DAGs that are triggered using the Airflow REST API or Airflow UI. - Run after: The point in time after which a specific DAG run can start. If a logical date is supplied, the run after date is set to the logical date. If the logical date is
Nonethe run after date is set to the current time as soon as the DAG run is triggered. - Start and Start Date: The time the DAG run actually started. This timestamp is unrelated to the DAG parameter
start_date. - End and End Date: The time the DAG run finished. This timestamp is unrelated to the DAG parameter
end_date. - Duration and Run Duration: The time it took for the DAG run to complete, difference between the start and end date timestamps.
- Run ID: The unique identifier for the DAG run. The run ID is a combination of the type of DAG run, for example
scheduledand the logical date. If the logical date isNone, the run after date is used with an added random string suffix to ensure uniqueness. The run ID is used to identify the DAG run in the Airflow metadata database. - Last Scheduling Decision: The last time a scheduler attempted to schedule task instances for this DAG run.
- Queued at: The time the first task instance was queued for this DAG run.
There are two additional timestamps that are only meaningful when using the CronDataIntervalTimetable.
- Data Interval Start: When the
CronDataIntervalTimetableis used, the data interval start timestamp of a DAG run is equivalent to the run after date of the previous scheduled DAG run of the same DAG. When using other schedules, the data interval start timestamp is equivalent to the run after date of the current DAG run. If the DAG run is triggered with the logical date set toNone, the data interval start timestamp is alsoNone. - Data Interval End: When the
CronDataIntervalTimetableis used, the data interval start timestamp of a DAG run is equivalent to the run after date of the current scheduled DAG run. If the logical date is set toNone, the data interval end timestamp is alsoNone.
For manual Dag runs via the Airflow UI you have the option to choose Specify Manually to provide a custom Data Interval.
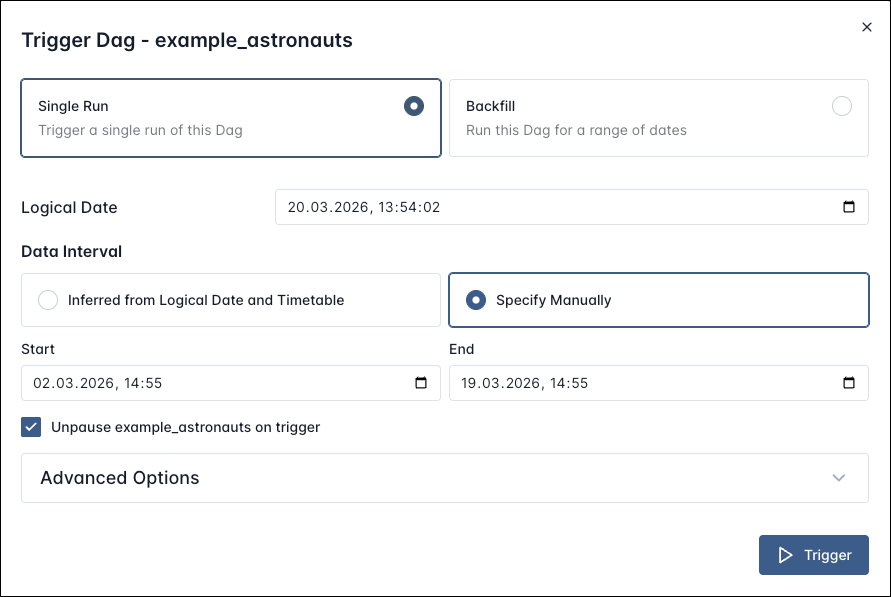
This will create one Dag run where the context variables data_interval_start and data_interval_end are set to the custom values you provided. This is different from creating a backfill where one Dag run per schedule interval is created for the time period you specified.
For more information on the data intervals and the differences between the CronDataIntervalTimetable and the CronTriggerTimetable, see the Airflow documentation.
Schedule DAG parameters
The following parameters ensure your DAGs run at the correct time:
start_date: The timestamp after which this DAG can start running. When using theCronDataIntervalTimetable, thestart_dateis the moment in time after which the first data interval can start. Default:None.schedule: Defines the rules according to which DAG runs are scheduled. This parameter accepts cron expressions, timedelta objects, timetables, and lists of assets. Default:None.end_date: The date beyond which the DAG won’t run. Default:None.catchup: A boolean that determines whether the DAG should automatically fill all runs between itsstart_dateand the current date. Default:False. Aside from this automatic behavior, you can also manually trigger DAG runs for any date in the past. See Backfills for more information.
The following code snippet defines a DAG with a start_date of April 1, 2025, a schedule of @daily, and an end_date of April 1, 2026. The DAG will run every day at midnight UTC, starting on April 1, 2025, and ending on March 31, 2026. It doesn’t catch up on any missed runs automatically.
Don’t make your DAG’s schedule dynamic (for example, datetime.now())! This will cause an error in the Scheduler.
Time-based schedules
For pipelines with straightforward scheduling needs, you can define a schedule in your DAG using:
- A cron expression.
- A cron preset.
- A timedelta object.
Cron expressions are passed to a timetable under the hood. The default timetable used is the CronTriggerTimetable. You can use the [scheduler].create_cron_data_intervals configuration option to switch to using the CronDataIntervalTimetable instead, which was the behavior in previous Airflow versions. See Timetable comparisons for more information.
Cron expressions
You can pass any cron expression as a string to the schedule parameter in your DAG. For example, if you want to schedule your DAG at 4:05 AM every day, you would use schedule='5 4 * * *'.
If you need help creating the correct cron expression, see crontab guru.
Cron presets
Airflow can utilize cron presets for common, basic schedules. For example, schedule='@hourly' will schedule the DAG to run at the beginning of every hour. For the full list of presets, see Cron Presets.
Timedelta objects
If you want to schedule your DAG on a particular cadence (hourly, every 5 minutes, etc.) rather than at a specific time, you can pass a timedelta object imported from the datetime package or a duration object from the pendulum package to the schedule parameter. For example, schedule=timedelta(minutes=30) will run the DAG every thirty minutes, and schedule=timedelta(days=1) will run the DAG every day.
Limitations of cron-based schedules
Cron-based schedules run into limitations when dealing with irregular time-based schedules. For example when:
- Scheduling a DAG at different times on different days. For example, 2:00 PM on Thursdays and 4:00 PM on Saturdays.
- Scheduling a DAG daily except for holidays.
- Scheduling a DAG at multiple times daily with uneven intervals. For example, 1:00 PM and 4:30 PM.
Such schedules can be created using timetables.
Data-aware scheduling
With Assets, you can make Airflow aware of updates to data objects. Using that awareness, Airflow can schedule other DAGs when there are updates to these assets. To create an asset-based schedule, pass the names of the asset(s) to the schedule parameter. You can create schedules based on conditional logic involving multiple assets, or even combine asset-based schedules with time-based schedules.
Simple
This DAG runs when both my_asset_1 and my_asset_2 are updated at least once.
Conditional
This DAG runs when either my_asset_1 or my_asset_2 is updated.
Time
This DAG runs every day at midnight UTC and, additionally, whenever either my_asset_1 or my_asset_2 is updated.
Assets can be updated by any tasks in any DAG of the same Airflow environment, by calls to the asset endpoint of the Airflow REST API, or manually in the Airflow UI.
To learn more about assets and data driven scheduling, see Assets and Data-Aware Scheduling in Airflow guide. Assets can be combined with AssetWatchers to create event-driven schedules. For more information, see Event-Driven Scheduling.
Timetables
Each time-based schedule in Airflow is implemented using a timetable under the hood. There are a couple of built-in timetables, including the CronTriggerTimetable and CronDataIntervalTimetable. If no timetable exists for your use case, you have the option to create your own custom.
Continuous timetable
You can run a DAG continuously with a pre-defined timetable. To use the ContinuousTimetable, set the schedule of your DAG to "@continuous" and set max_active_runs to 1.
This schedule will create one continuous DAG run, with a new run starting as soon as the previous run has completed, regardless of whether the previous run succeeded or failed. Using a ContinuousTimetable is especially useful when sensors or deferrable operators are used to wait for highly irregular events in external data tools.
Airflow is designed to handle orchestration of data pipelines in batches, and this feature isn’t intended for streaming or low-latency processes. If you need to run pipelines more frequently than every minute, consider using Airflow in combination with tools designed specifically for that purpose like Apache Kafka.