Micropipelines: A Microservice Approach for DAG Authoring in Apache Airflow®
15 min read |
As data teams work to discover and deliver insights, they use a large variety of data sources, such as applications, databases, and files. In the process, they usually have to transform some or all of the data so that it can be aggregated in a consistent form. After this, the data gets analyzed and summarized through multiple steps, using a variety of tools, before arriving at critical business insights. This sequence of steps is called a data pipeline, and today, these pipelines are often large and monolithic, responsible for all the steps from gathering the source data to producing the eventual business insights.
Much like large monolithic applications, large monolithic pipelines are difficult to maintain and enhance. Even the smallest change in format of an incoming data feed, for example, causes the entire pipeline to be updated and redeployed.
Moreover, monolithic pipelines often pose a critical challenge to enterprises that need business insights to be available in a timely manner. For most organizations, certain insights are far more time-critical than others. Revenue tracking and trends are typically reviewed on an hourly basis, for example, as compared to sales productivity or advertising effectiveness metrics, which may be reviewed only monthly. But since monthly sales productivity metrics may depend on some of the data produced by the hourly revenue-tracking task, a data engineer might build both processes into the same monolithic DAG, to make it easier to manage this dependency. The problem is that having these varied data analysis tasks in the same pipeline makes it difficult to get revenue tracking on a timely basis with a high degree of efficiency.
Now, with the release of Apache Airflow® 2.4, monolithic pipelines can be decomposed into smaller, loosely coupled components — or micropipelines — which can then be orchestrated together. It’s a transformative development, made possible by the new release’s introduction of Datasets as a top-level concept.
Dataset Definition
A dataset is a logical abstraction for a data object such as a database table or a file containing data. Airflow now supports a native Dataset class, enabling DAG authors to define a dataset object, identified by a URI, which provides an unambiguous reference to the dataset, such as a fully qualified path to the database table or file.
Micropipeline Definition
A micropipeline is a small, loosely coupled data pipeline that operates on one or more input datasets and produces one or more output datasets. Micropipelines can be started simply as a result of input datasets being updated, without needing explicit time-based scheduling.
Since micropipelines can be deployed and scaled independently, the entire data system can now be tuned as needed for optimal business needs, to make sure critical data products are available on time.
Additionally, this independence means that individual micropipelines can be developed in different programming languages, such as Python or SQL, which will ultimately empower data team members who have different skill sets and make it easier to use the right tool for the job. For example, regular expression-handling in data cleansing may be best done in Python, whereas aggregate data handling may be best done in SQL, and machine learning in Spark.
Monolithic Pipelines and Their Drawbacks
Apache Airflow® has had very broad integration support over the years, enabling the creation of data pipelines across files, cloud data warehouses such as Snowflake, BQ, and Redshift, data lakes such as Hadoop, and data analysis frameworks such as Spark and TensorFlow. Airflow's ability to work with such a wide range of data sources and analytic frameworks has been critical to its success. Data vendors and data teams worldwide have taken advantage of this breadth and have created pipelines spanning varied data systems.
The monolithic pipeline shown below is from a (fictitious) financial analysis organization that provides information about the expected financial results of public companies. In the cases of, say, a publicly held Luxury Retailer and a publicly held Household Retailer, the organization might perform an analysis based on aggregated consumer spend at the companies’ stores, using aggregated payment data from credit and debit cards.
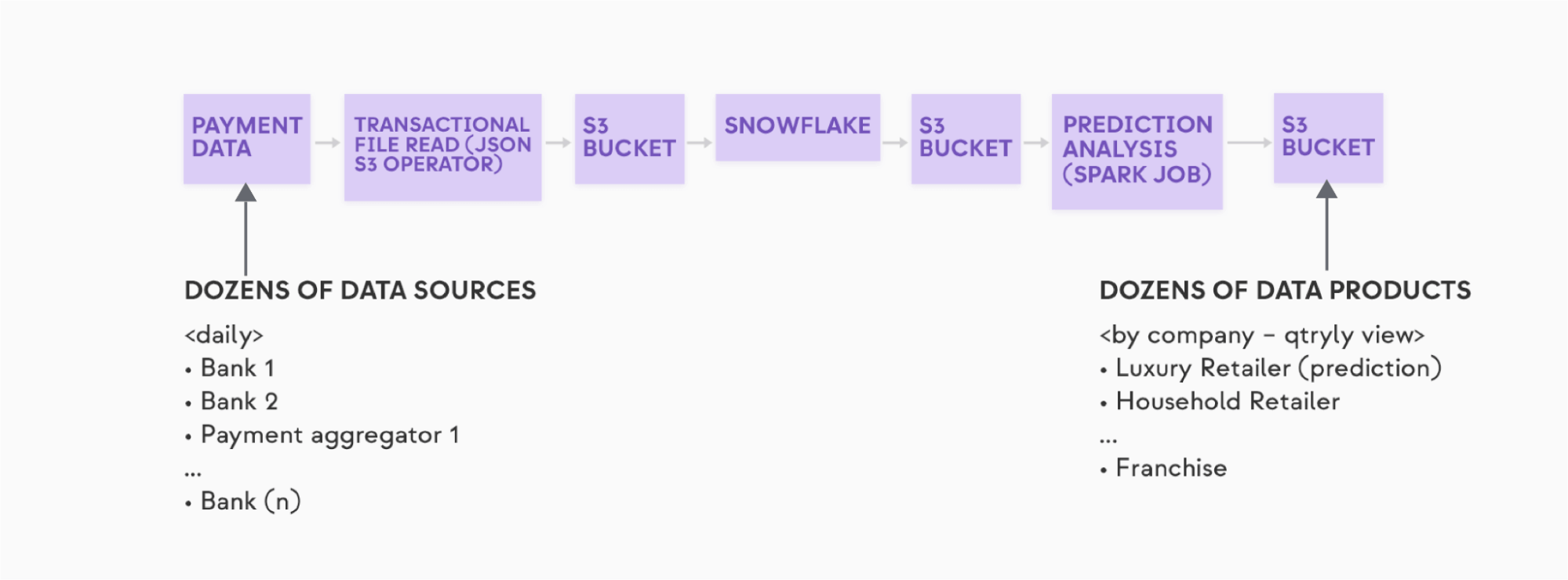
The pipeline covers a lot of ground:
- The incoming payment data comes as discrete data feeds from dozens of payment processors and banks, and needs to be transformed, using regular expressions, to a common form. This data is reported by the data sources on a daily basis.
- The data is then aggregated together into a Snowflake data warehouse.
- The aggregated data is then analyzed using Spark for prediction of the quarterly results, and compared to expectations.
- The curated results of the analysis are then made available by company — e.g.,. Luxury Retailer A, Household Retailer X, etc. — as a “Data Product” in individual files in a S3 bucket.
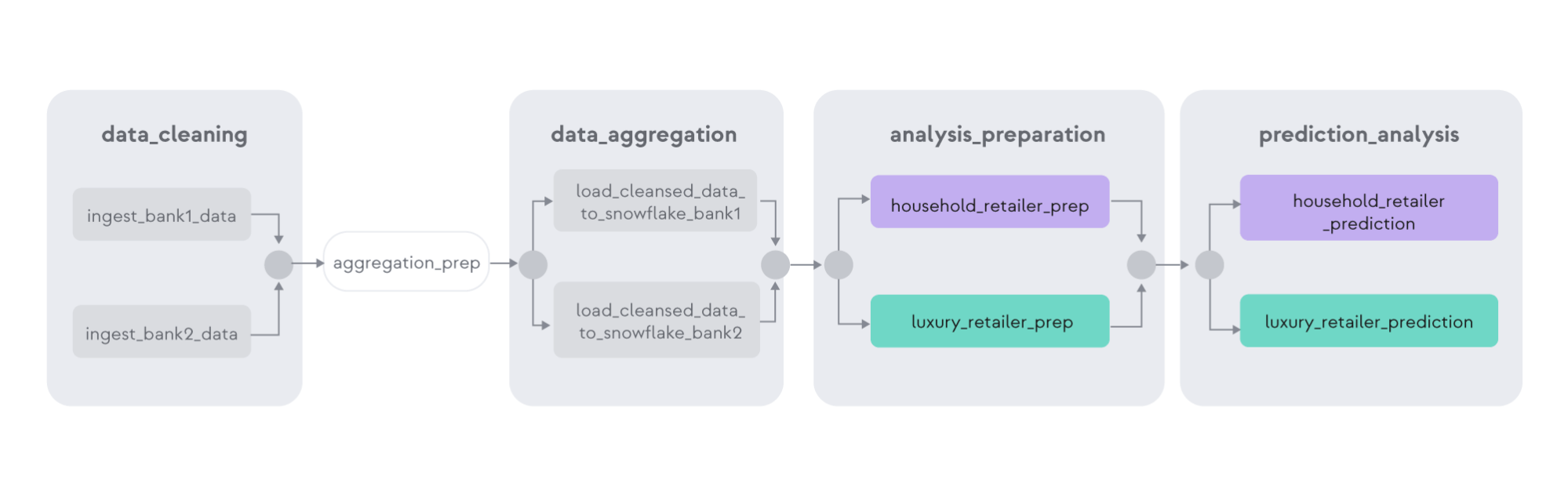
The view of this pipeline in Apache Airflow® is shown below as an Airflow UI graph view, which presents the sequence of steps it takes to execute the entire pipeline:
Imagine that as business grows, this financial insights organization signs a deal to cover the expected results for a larger Franchise Company. The transactions for this Franchise Company are much greater — in terms of both payment transaction volume and variety of incoming transactional data — than for either of the two retailers, because of the large number of franchises from which the data needs to be gathered. To get this larger spread of data, the insights organization signs a deal with a payment processor to increase the spread of input data.
Wanting to leverage the existing data pipeline infrastructure, the data team adds this new incoming dataset to the existing monolithic pipeline, and also clones the prediction algorithms used for the other companies to estimate results for the Franchise Company. The updated pipeline is shown below:
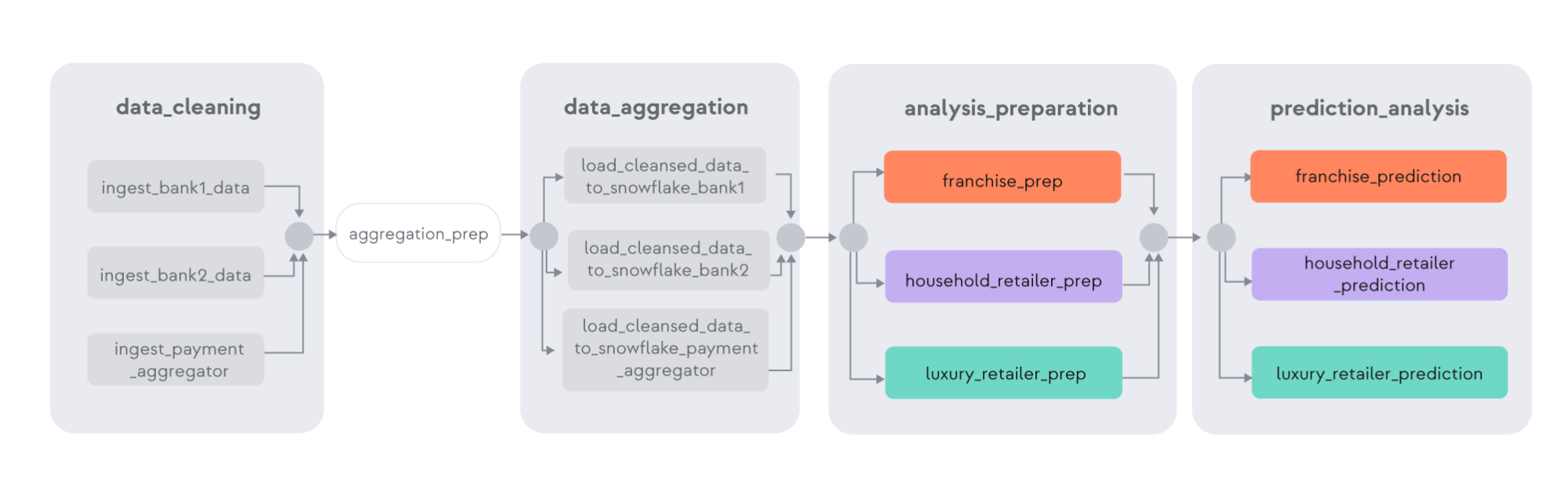
The data team expects that the analysis for the Franchise Company could take longer. But they are shocked to find that the estimates for the other companies, whose data is already running in the DAG, are also delayed, by more than 300%.
The timeline views of the monolithic DAG runs before and after the addition of the Franchise Company's data are shown below:
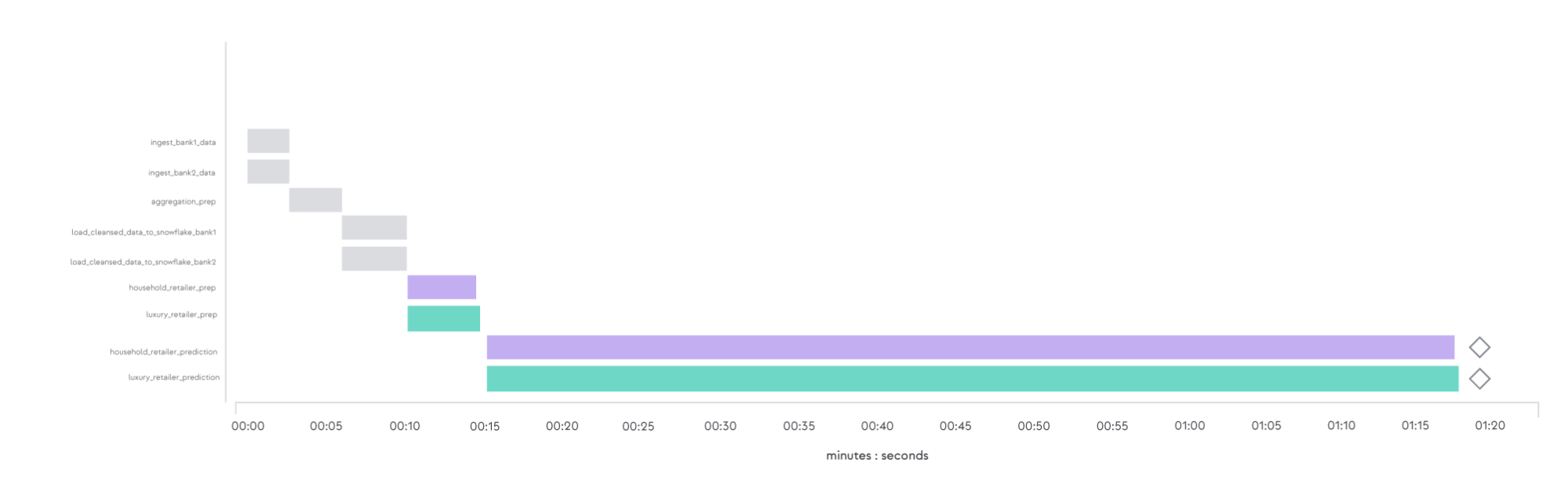
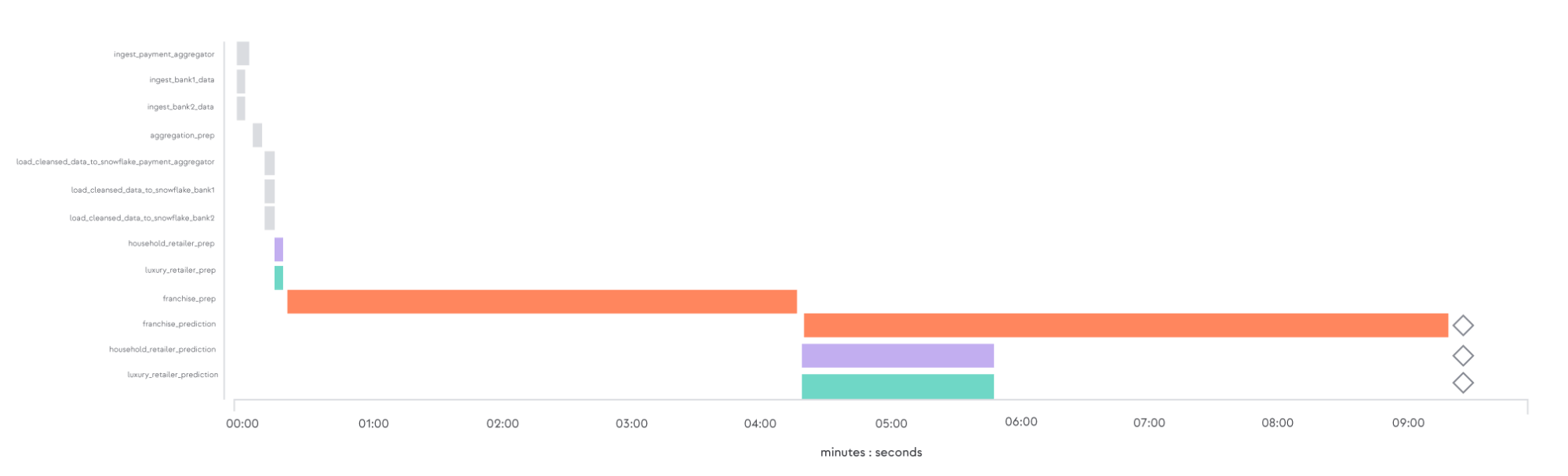
This use case illustrates one of the core problems of monolithic pipelines. The introduction of even a single long-running task can delay the delivery of all of the data products being processed. In most situations this is unexpected, causing frustration when delays in the delivery of business-critical data impact production operations.
Drawbacks of monolithic pipelines
- Risk to timeliness of critical business dataIn a monolithic pipeline producing many Data Products, it is extremely difficult to tune the pipeline, or the underlying infrastructure for scaling the pipeline, to ensure that the critical Data Products — which may be less than 20% of all Data Products — are produced in a timely manner, and to prevent the other 80% from taking capacity away from, and inadvertently causing delays to, the critical set.As shown above, it is common for one long-running data transformation to delay everything.
- Friction in DevelopmentMonolithic pipelines cause development friction as a data team grows, bringing on people with diverse skill sets — for example, a data analyst who is a SQL expert, but who needs to get help from a data engineer who knows Python to integrate a new analysis task into the pre-existing, Python-based monolithic pipeline. The development and deployment process ends up taking extra time, requiring two people to schedule and coordinate, rather than operating on a self-service model with high speed execution.
- Deployment riskChange poses a high degree of risk for monolithic pipelines, as it does for monolithic applications, since disruptions of critical time-sensitive pipelines are very costly to an organization. This creates a need for more testing, which causes additional friction and negatively impacts development velocity and time to value.
The Impact of Micropipelines
The exact same pipeline, when re-architected based on micropipelines, is not susceptible to these unexpected delays. This can be seen in the timeline view below of micropipeline-based DAGs corresponding to the Luxury Retailer, the Household Retailer, and the Franchise Company. The predictions for the Luxury Retailer and the Household Retailer are done in about 90 seconds, starting from Data Ingestion, all the way to prediction. In the simultaneously initiated execution of the Franchise Company’s set of micropipelines, the total time to prediction is longer, but this does not impact the time-to-prediction for the other companies because it does not block the availability of the other data products.
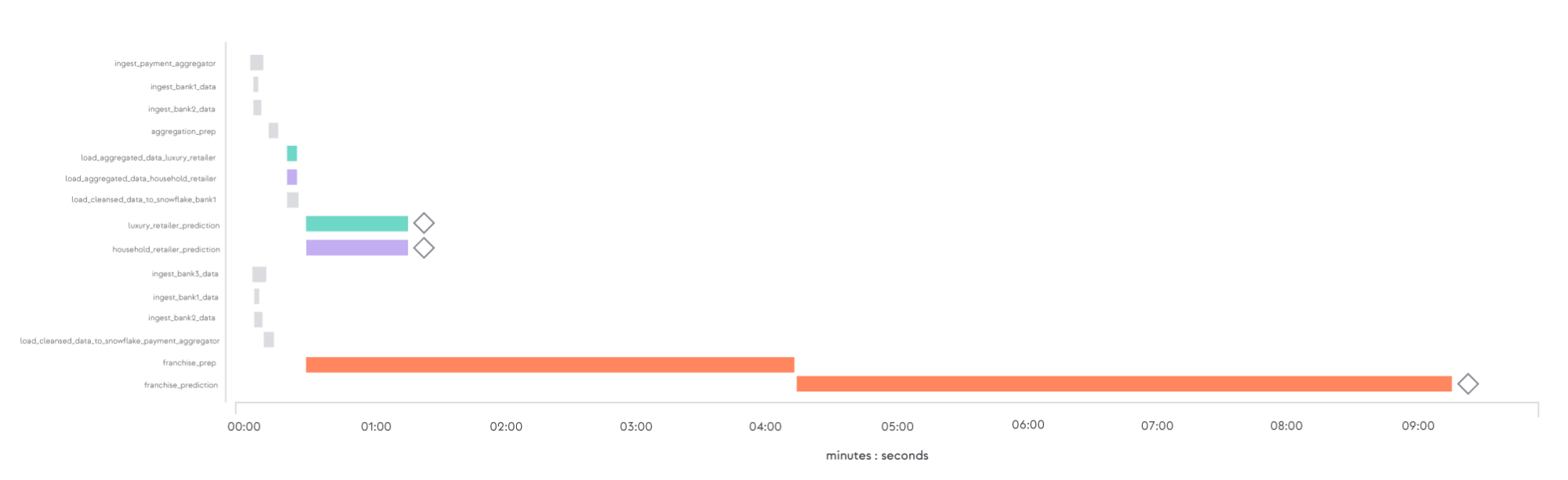
As shown above, micropipelines enable far more predictable data timeliness — in part because they enable clear separation between the tasks needed by Data Products, while still enabling the dependencies between them as needed.
To explain how this composite pipeline was architected and developed, it is important to understand a couple of key concepts.
Enabling Componentization Using Datasets
The focus of the last couple of Airflow releases, including the new Airflow 2.4 release, has been on making the developer experience easier across the full lifecycle of data pipeline development, from authoring pipelines to enhancing and maintaining them over their natural evolution.
One key concept has been Datasets and DAG dependencies using Datasets. As explained above, a dataset is a logical abstraction for a data object such as a database table or a file containing data. In Apache Airflow® 2.4+, a Dataset is a top-level object that has explicit producer and consumer behavior specified. These specifications mean that what was previously one large pipeline with a sequence of tasks can now be split apart into several stages, as shown below, with the coupling between stages being intermediate Datasets.
An example of the previously covered composite pipeline, now using the Datasets feature, would look something like:
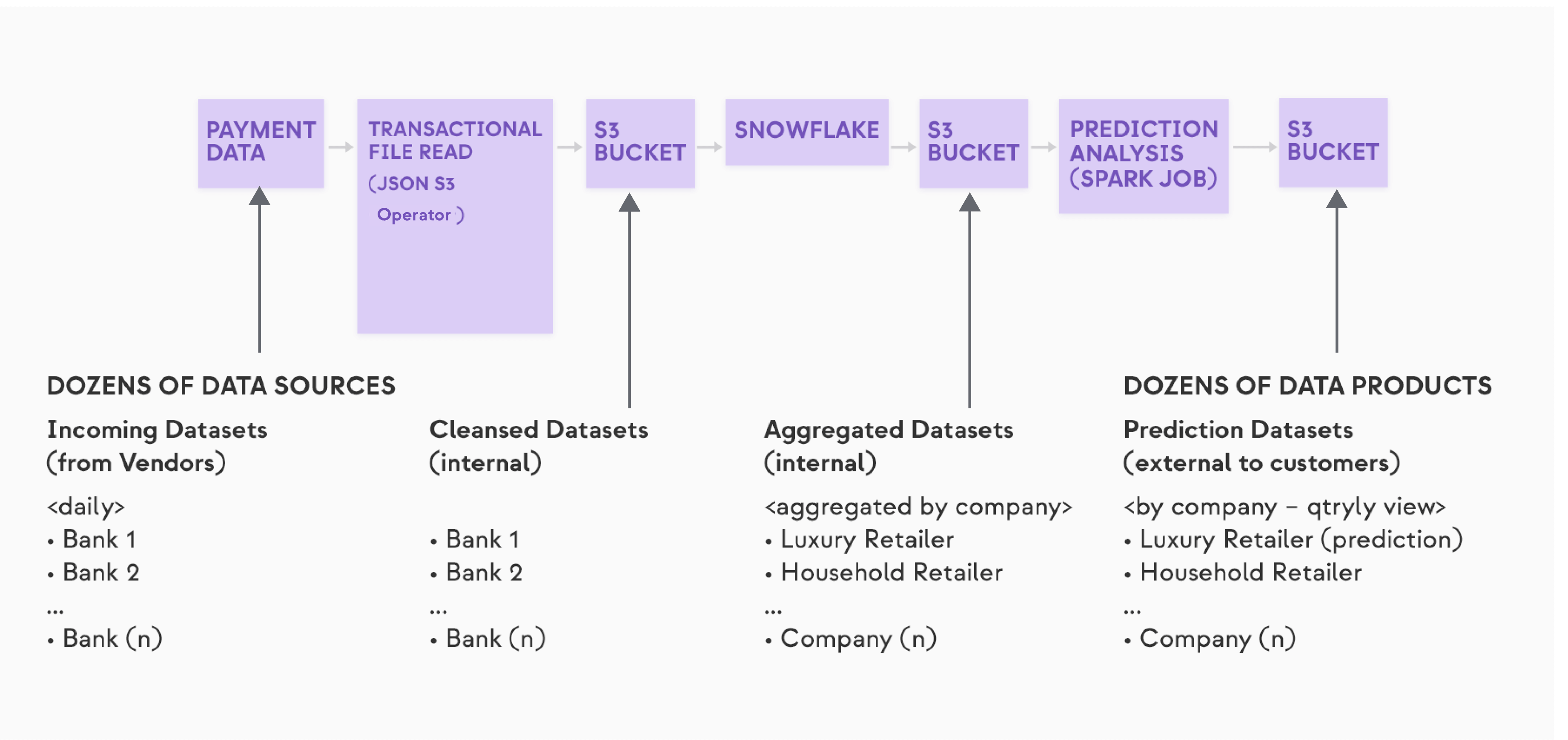
As illustrated here, the first, data ingestion stage of this pipeline could be a micropipeline, with the output being the “Cleansed Datasets.” The second, data aggregation stage could be a set of different micropipelines, with the input being the “Cleansed Datasets” and the output being the “Aggregated Datasets.” The third, “prediction analysis” stage could be another set of micropipelines, with the input being the “Aggregated Datasets” and the output being the “Data Predictions.”
These micropipelines all have a simple, focused purpose: they operate on one or more input datasets and produce one or more output datasets.
The workflow described above is shown in two Airflow UI views below:
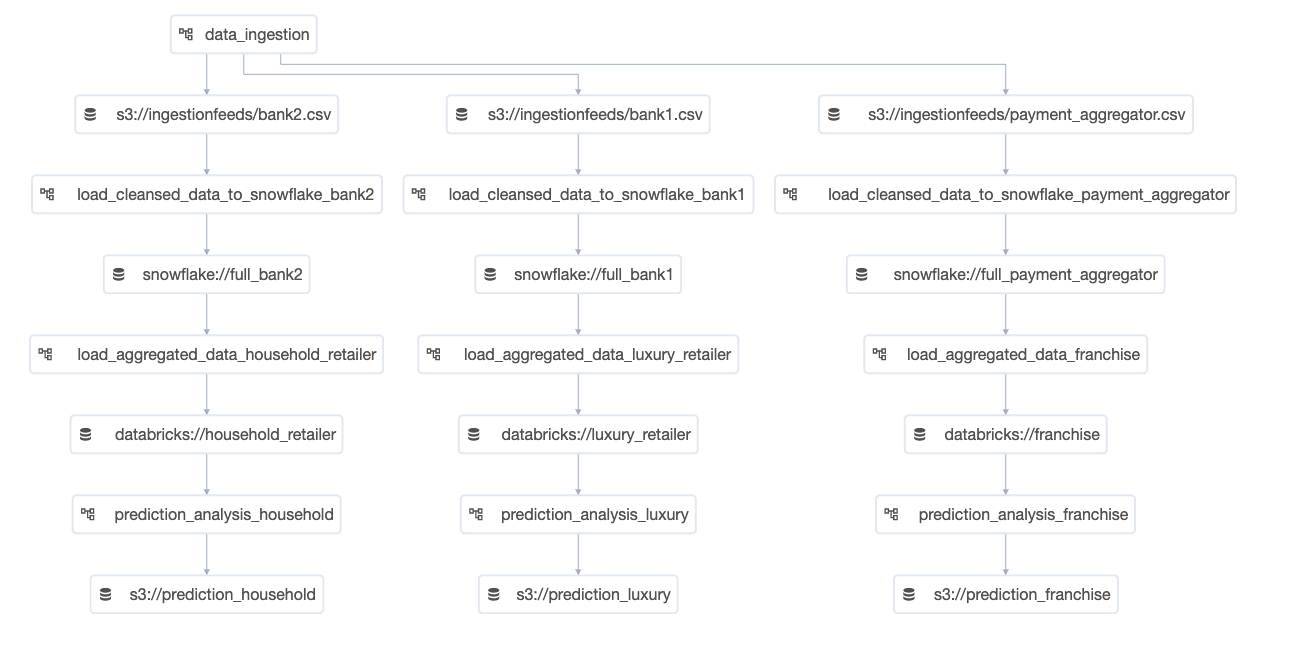

One of the key enhancements in Airflow 2.4 is that once these micropipelines are defined with input datasets, they don't need to be explicitly scheduled based on time: They can be automatically triggered based on the incoming dataset being updated. Therefore a common pattern with Airflow 2.4+ is to have only the first micropipeline in a series actually scheduled based on a time interval, and to then let the rest of the pipelines be automatically triggered and run by Airflow based on the incoming datasets being updated.
This enables an organization’s critical, well-tuned pipelines to run and produce business insights in a timely manner, without risk of being affected by an outlier that takes a long time.
How Micropipelines Are Built
The core Dataset and Data Driven Scheduling capability in Apache Airflow® 2.4 enabled the triggering and compartmentalization described above. To make the creation of these micropipelines simple and easy, we have extended the Dataset concept to the Astro Python SDK, an open-source development library for use with Apache Airflow®.
The SDK exposes a programmatic abstraction that simplifies the creation of Dataset types. The first couple of Dataset types created have been Files and Tables, though additional types, such as Dataframes, will be added soon.
File Datasets and cloud transparency
The File Dataset represents a standard file, and provides transparency of access regardless of location — whether that’s a local filesystem, GCS (Google Cloud Storage), S3 (on Amazon Web Services), or anywhere else. It is identified by a URI (Uniform Resource Identifier), including the absolute pathname of the file object and the connection credentials needed to access it if it is on a cloud service.
By providing a consistent mechanism of access regardless of location, the File Dataset enables both a smooth local development experience and a production experience on any cloud service without vendor lock-in.
Table Datasets and database transparency
The Table Dataset represents a table in a relational database, and provides transparency of access regardless of the database type — whether it’s Postgres, BigQuery (on Google Cloud), Redshift (on Amazon Web Services), Snowflake, or something else. It is identified by a URI, including the table name and optionally the database / schema names, along with the connection credentials needed to access this database table.
By providing a consistent mechanism of access regardless of the type of database being used, the Table Dataset enables a smooth development-to-production experience, and avoids code changes when moving from one cloud data warehouse to another.
Transfer Operations
Any data pipeline — including the example pipelines shown above — includes data movement, typically from Files to Database Tables, back to Files, to analysis engines such as Spark or TensorFlow.
A core tenet of the Astro Python SDK has been, “Make the easy things easy, and the hard things possible” (originally from Larry Wall).
In this spirit, data movement operations are made trivially easy by using the SDK, and provide complete transparency regardless of the source / type of data and the source / type of destination. Transfer operations are simple invocations on the File and Table Dataset objects and the underlying SDK handles all the details of the data transfer, leveraging native optimized transfer mechanisms such as S3 to Snowflake, when they exist.
Dynamic Task Templates
In many pipelines, the number of data objects such as files to be processed can vary over time, and may be unknown at the time of authoring a pipeline. Dynamic Tasks, released in Airflow 2.3, provides the core functionality to address this issue.
The Astro Python SDK provides Dynamic Task Templates that enable the processing of an unknown (and varying over time) number of data files stored across any cloud storage such as GCS and S3.
Evolving toward the functional authoring of micropipelines
In summary, there are three key implications of Airflow 2.4’s introduction of Datasets as a top-level concept.
- Datasets and Micropipelines:The core Dataset capability in Airflow 2.4, coupled with the advanced Dataset-based framework in the Astro Python SDK development kit, lays the foundation for a far simpler micropipeline authoring process, where the only code that needs to be written from scratch is the analysis algorithm. This analysis algorithm can consist of multiple steps for summarization and pattern identification.Composite pipelines that pull these micropipelines together can naturally evolve and scale by using the Dataset dependency mechanism described above.The resulting Datasets are the Data Products made available to customers, either internal or external.
- Functional and Declarative development:The natural evolution here will be that this analysis algorithm can be developed by a Data Scientist or Analytics Engineer in any appropriate language, such as Python, SQL or Yaml, and can be tested in development and deployed directly to production without needing any integration or intervention by a Data Engineer.This development will directly enable decentralized data ownership and self-service data analysis, which in turn will drive higher velocity, more value-added collaboration and a faster time to value.
- Orchestration enabling predictable, on-time Data Product availability:By making it simple to target scaling to specific priorities, and minimizing unintended consequences of additional adhoc deployments, micropipelines in Apache Airflow® enable more efficient data orchestration and reliable on-time Data Product availability.
Clearly, some of these concepts map closely to the core principles of DataMesh as articulated originally by Zhamak Dehghani. As these capabilities further evolve in Airflow and the associated Astro Python SDK development framework on top of Airflow, we will see the emergence of an Enterprise Data Mesh, all orchestrated at scale, that enables the right Data Products to be consistently available on time.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.