Reimagining Airflow for Data Engineers and Data Scientists with the Astro Python SDK
6 min read |
Guess what: Airflow isn’t just for data engineers.
If you’re a data scientist or someone new to Airflow who's familiar with basic Python, we’ve got something big for you: the fastest way to get started writing Airflow data pipelines. While Apache Airflow® is an incredibly powerful tool, supported by a strong open source community of user-contributors, there are considerable barriers to entry. Until now, someone new to Airflow would need to learn a great deal of Airflow-specific knowledge—involving operators, tasks, hooks, XComs, bit shift operators, and more—to be able to start writing Airflow pipelines in the form of directed acyclic graphs (DAGs).
Today, we’re excited to announce the production-ready release of the Astro Python SDK—an open source Python framework for writing data pipelines that run on Airflow. To use it, you need only learn seven Python functions and two Python classes. As a data scientist, you can write not only your data transformations in Airflow, but also your own extract and load operations. In other words, you don’t need to wait for spare cycles from a data engineer to load data into your warehouse and get started on writing your transformations. All data practitioners will find DAG authoring with the SDK easier than with standard Airflow.

An elegant DAG authoring library for data scientists and data engineers
Benefits of writing DAGs with the Astro Python SDK include:
- Shorter, simpler DAGs: Reduce your code by about 50% by eliminating boilerplate logic.
- No knowledge barriers: Write your transformation logic in Python or SQL, whichever is best for you and your data. Since the SDK will convert your data from a dataframe to a Table and back for you, you can easily go back and forth between your Python and SQL data transformations.
- Orchestration logic managed for you: Details like creating dataframes, storing intermediate results, passing context and data between tasks, and creating Airflow task dependencies are all handled automatically.
- Database- and filesystem-agnostic: Tasks can be written in the same way regardless of the source or target systems.
These benefits result in a data-centric DAG authoring experience superior to one that uses traditional Airflow operators.
Purpose-built functions for ELT pipelines
The Astro Python SDK simplifies writing data pipelines. We’ve focused first on extract, load, and transform (ELT), as that is one of the most common use cases for Airflow.
ELT-specific functions in the SDK include:
- load_file: Loads data from a file (CSV, JSON, or parquet files stored locally or on S3 or GCS) into your data warehouse or a dataframe
- transform: Transforms your data with a SQL query. It uses a
SELECTstatement that you define to automatically store your results in aTableobject. - dataframe: Permits transformation on your data using panda dataframes.
- append: Appends the results of your transformations to an existing table in your database.
All functions are thoroughly documented with examples and versioned reference materials.
For an example of how these functions simplify the DAG authoring experience, let’s look at loading a CSV file from S3 to Snowflake. The example below shows how to implement this task using, in the first case, traditional Airflow operators (SnowFlakeOperator and S3toSnowflakeOperator) versus, in the second, an Astro Python SDK function (load_file).
create_table = SnowflakeOperator(
task_id="create_table",
sql=f"""CREATE OR REPLACE TABLE
{SNOWFLAKE_DATABASE}.{SNOWFLAKE_SCHEMA}.{SNOWFLAKE_SAMPLE_TABLE}
(home_id char(10),address char(100), sqft FLOAT)""",
snowflake_conn_id=SNOWFLAKE_CONN_ID,
)
load_data = S3ToSnowflakeOperator(
task_id='load_homes_data',
snowflake_conn_id=SNOWFLAKE_CONN_ID,
s3_keys=[S3_FILE_PATH + '/homes.csv'],
table=SNOWFLAKE_SAMPLE_TABLE,
schema=SNOWFLAKE_SCHEMA,
stage=SNOWFLAKE_STAGE,
file_format="(type = 'CSV',field_delimiter = ',')",
)load_data = load_file(
input_file=File(path="s3://airflow-kenten/homes1.csv", conn_id=AWS_CONN_ID),
output_table=Table(name="HOMES", conn_id=SNOWFLAKE_CONN_ID)
)The Astro Python SDK allows you to write this load task with two lines of code instead of 13. Moreover, since the load_file task is system agnostic, you don’t need to provide S3- or Snowflake-specific parameters or have detailed knowledge of how the specific S3toSnowflakeOperator works.
Astro Python SDK functions are designed around Python objects that we have developed specifically for ELT use cases. For example, the load_file function above uses File and Table objects to define the input and output data. You use the Table object for your Python functions to communicate with each other. By contrast, in standard Airflow, you would have to use XCom or temporary tables to pass data between tasks. Both of these methods clutter your code, obfuscating your data transformation logic.
The Astro Python SDK 1.0 runs on any Airflow 2.0+ instance. When you execute a DAG built with the Astro Python SDK, you’ll find the experience similar to running other Airflow DAGs. In particular, you’ll find a one-to-one correspondence between SDK functions in your code and tasks you see in the Airflow UI.
Here’s how to implement the extract and transform steps of an ELT pipeline using the Astro Python SDK:
@transform
def extract_data(homes: Table):
return """
SELECT COUNT(*)
FROM {{homes}}
"""
@dag(start_date=datetime(2021, 12, 1), schedule_interval="@daily", catchup=False)
def example_sdk_dag():
# Load data from S3 to Snowflake
homes_data = load_file(
input_file=File(path="s3://airflow-kenten/homes1.csv", conn_id=AWS_CONN_ID),
output_table=Table(name="HOMES1", conn_id=SNOWFLAKE_CONN_ID)
)
# Perform a data transformation
extracted_data = extract_data(
homes=homes_data,
output_table=Table(name="count_homes"),
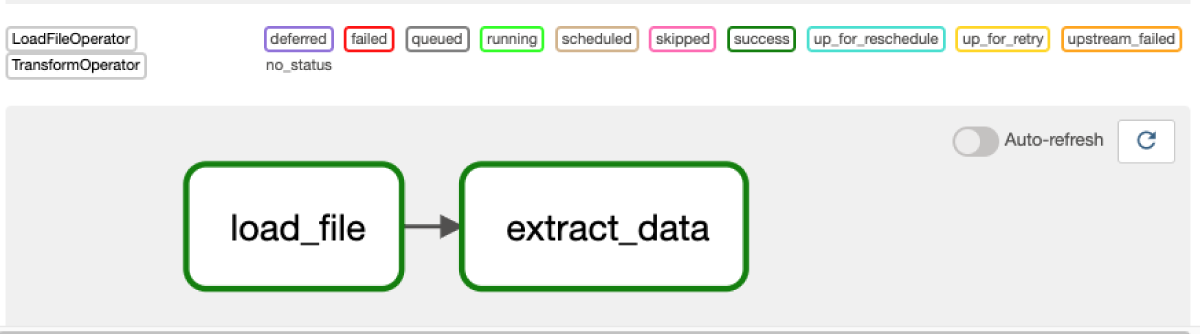
)In the Airflow UI, we see a familiar graph view with two tasks that have run successfully, where each task corresponds to a function call in the code to the Astro Python SDK.
Astro OSS as an improved data orchestration experience
The Astro Python SDK is available as Astro Open Source Software (OSS), under Apache 2.0 License, from http://github.com/astronomer. We are building Astro OSS to provide a richer DAG authoring and data orchestration experience to the Airflow community. Our work on Astro OSS is a natural complement to our continuing contributions to advance the core of Apache Airflow® OSS.
Beyond the Python SDK, Astro OSS includes the Astro CLI and Astro Providers. The Astro CLI is an open source binary that provides a self-contained local development environment in which you can build, test, and run Airflow DAGs and tasks on your machine. (Read about Astro CLI commands.) The Astronomer Providers package contains deferrable operators, hooks, and sensors that give organizations the ability to schedule long-running tasks asynchronously, reducing costs with provisioning on-premise and cloud-based infrastructure.
A library of examples to get you started
The Astro Python SDK 1.0 release includes thorough documentation, code examples, tutorials, and implemented use cases to get you started on a successful DAG authoring journey. We recommend the following resources:
- Tutorial for step-by-step instructions on how to create your first ELT DAG with the SDK
- A introductory webinar to the SDK
You can also find all of the source code in this repo. In the spirit of open source, we welcome your feedback and contributions to this active project.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.