Apache Airflow® 2.4 — Everything You Need to Know
13 min read |
When Airflow 2.3 dropped just over four months ago, we called it one of the most important-ever releases of Apache Airflow®, thanks mainly to its introduction of dynamic task mapping.
The same can be said of today’s Airflow 2.4 release, which introduces a “datasets” feature that augments Airflow with powerful new data-driven scheduling capabilities.
[tl;dr] What’s new in Airflow 2.4?
Data-driven scheduling
- New data-driven scheduling logic inside of Airflow 2.4 automatically triggers downstream DAGs to run once their upstream dependencies successfully complete.
- You use Airflow’s new
Datasetclass to define dependencies between specific upstream tasks and downstream DAGs.- You can break up monolithic pipelines and run multiple upstream and downstream DAGs in their place, so that adding a new data source or new transformation logic to one won’t adversely affect the performance of the others — which helps in prioritizing your business-critical pipelines.
- Data-driven scheduling is fungible enough to be adapted to many common use cases as well as cutting-edge ones like model maintenance in ML engineering.
And also…
- A new consolidated
scheduleparameter is available as an alternative to Airflow’s existing schedule and timetable parameters.- A new CronTriggerTimetable makes Airflow’s scheduling syntax behave more like cron’s.
- Support for additional input types for use with Airflow’s dynamic task mapping feature.
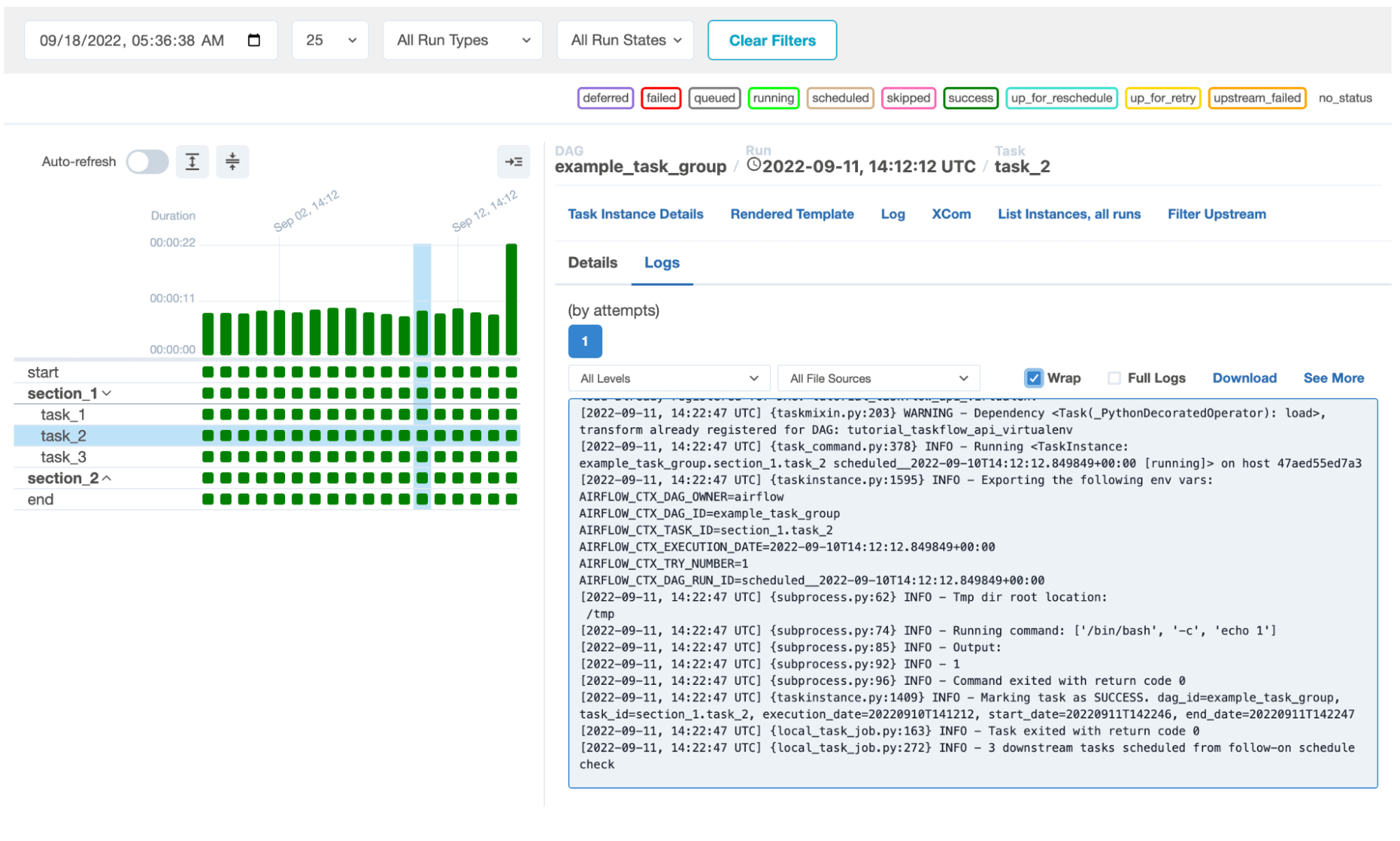
- Several significant UI improvements, including an ability to drill down into log files from Airflow’s grid view.
In Airflow 2.4, you can use data-driven scheduling to break up large, monolithic DAGs into multiple upstream and downstream DAGs, and explicitly define dependencies between them. Doing so makes it easier for you to ensure the timely delivery of data to consumers in different roles, as well as optimize the runtime performance of your business-critical DAGs. Basically, if you have any downstream use case that depends on one or more upstream data sources, data-driven scheduling is going to transform how you use Airflow.
Other benefits include:
- Ensuring that data scientists, data analysts, and other self-service users always have access to the up-to-date data they need to do their work.
- Guaranteeing the timely delivery of the cleansed, conditioned data used to feed the business-critical KPIs, metrics, and measures that power operational dashboards.
- Enabling ML engineers and ops personnel to automate the process of retraining, testing, and redeploying production ML models, radically simplifying maintenance.
Data-driven scheduling is Airflow 2.4’s top-line feature, but it isn’t the only major change. The new release also introduces a schedule parameter that consolidates all of Airflow’s extant scheduling parameters. Now, authors can use that one parameter for all their tasks. And Airflow 2.4 expands the input types that DAG authors can use with its dynamic task mapping capabilities, fleshing out that capability first introduced in 2.3.
The rapidly improving Airflow UI benefits from a number of ease-of-use updates, too, while — behind the scenes — Airflow 2.4 packs several improvements that promise to reduce the amount of code DAG authors and ops personnel need to write and maintain. Once again, Airflow has gotten easier to code for, operate, maintain, and govern.
Data-Driven Scheduling Explained
Until now, DAG authors had to write, debug, and maintain their own logic to manage data dependencies. In earlier versions of Airflow, they sometimes used cross-DAG dependencies for this purpose, but these introduced external dependencies of their own, and — because Airflow lacked a native Dataset class — authors still had to use sensors to trigger dependent tasks.
A more common solution was to consolidate all dependencies into a single, monolithic DAG. This guaranteed that a successful upstream task run would automatically trigger downstream tasks in the same DAG; moreover, if an upstream dependency failed, the downstream tasks would not run, so DAG authors didn’t have to use (or write their own) task sensors to control for this. It was a workable approach, but monolithic DAGs can be difficult to debug and maintain; are prone to outages (because if a single task fails, the entire DAG fails); are not generally reusable; and do not give organizations a way to visualize and track datasets in Airflow.
The new release introduces a Dataset class that augments Airflow with the built-in logic it needs to run and manage different kinds of data-driven dependencies, exposing a single unified interface for inter-task signaling.
Data-driven scheduling works at the task level: you create a Dataset class and associate that with a specific task, which becomes a “producer” for one or more downstream “consumer” DAGs. A successful run by the producer task automatically triggers runs by any consumer DAGs. This makes a lot of sense: an upstream DAG might consist of hundreds of tasks, only one of which produces the dataset that a consumer DAG depends on. Or an upstream DAG might contain dozens of producer tasks, each corresponding to a separate consumer DAG.
By triggering data-driven dependencies at the task level, consumer DAGs can start sooner, enabling organizations to refresh the data consumed by their reports, dashboards, alerts, and other analytics in a timely manner.

Data-Driven Scheduling in Action
To take advantage of Airflow’s new datasets feature, DAG authors:
- Define a
Datasetclass and give a name to the dataset in their upstream DAG(s). - Reference that
Datasetin all producer tasks in their upstream DAG(s). - Define the
Datasetin their consumer DAG(s), if any, and use that as thescheduleparameter.
A good example involves one or more producer tasks that update the dimension and fact tables in a data warehouse. Once these producer tasks run and exit successfully, Airflow “knows” to run any consumer DAGs that depend on this data.
A dataset is any output of a producer task. It can be a JSON or CSV file; a column in an Apache Iceberg table; a table, or a specific column in a table, in a database; etc. The dataset is usually used as a source of data for one or more downstream consumer DAGs.
A consumer DAG might, for example, condense multiple upstream datasets into the CSV files that business analysts load into their data visualization tools. Or it might pull data from multiple upstream CSV files, Parquet files, and database tables to create training datasets for machine learning models.
Datasets are powerful because you can chain them together, such that one consumer DAG can function as a producer for the next DAG downstream from it. It's easy to imagine a chain of datasets in which the first consumer DAG — triggered by a producer task in an upstream ETL DAG — extracts a fresh dataset from the data warehouse, triggering a run by the next consumer DAG in the sequence, which cleanses, joins, and models this dataset, outputting the results to a second, entirely new dataset. The next and last consumer DAG in this imagined sequence then uses this second dataset to compute different types of measurements over time, outputting the results to a third and final dataset.
The Dataset class is fungible enough to be adapted to many common event-dependent use cases — including cutting-edge use cases, like model maintenance in ML engineering. New data added to upstream sources can trigger a consumer DAG that processes and loads it into the feature store used to train your ML models. This DAG can be a producer for the next steps in your pipeline, triggering consumer DAGs which validate (and retrain if necessary) your existing models on the updated data. In theory, you can even use datasets to more or less automate the maintenance of your ML models — for example, by creating consumer DAGs that automatically test and deploy your retrained models in production.
For DAG authors charged with creating and maintaining datasets, the new Dataset class promises to be a huge time-saver; for organizations concerned about governing datasets — which have a tendency to proliferate and become ungoverned data silos — it makes tracking and visualizing them much easier. (Admittedly, this ability is fairly basic in Airflow 2.4 today — users can see a “Datasets” tab in the Airflow UI; clicking on it displays the extant dataset objects — but is poised to improve over time.)

Beyond Datasets, One Scheduling Parameter to Consolidate Them All
Another big change in Airflow 2.4 is its consolidated schedule parameter, which was prompted in part by the new Dataset class.
In prior versions of Airflow, DAG authors used a pair of parameters — schedule_interval and timetable — to tell Airflow when to run their DAGs. To accommodate Dataset scheduling in Airflow 2.4, maintainers initially planned to introduce a third parameter, schedule_on. Ultimately, though, they decided to consolidate the functions of all three parameters into a new one: schedule, which can accept cron expressions, as well as timedelta, timetable, and dataset objects.
Fortunately, updating your DAGs to use the new schedule parameter is extremely simple. In existing DAGs, authors can paste it in as a drop-in replacement for the deprecated schedule_interval and timetable parameters. For new, dataset-aware DAGs, authors can use the schedule parameter to schedule DAG runs for both upstream DAGs that have producer tasks and any consumer DAGs that depend on upstream producer datasets.
Although schedule_interval and timetable are officially deprecated as of Airflow 2.4, Airflow will continue to support all three parameters for now. Support for the deprecated ones won’t be sunsetted until a future major release, giving organizations plenty of time to update their DAGs. And because schedule is literally a drop-in replacement for the older parameters, implementing this change should be as easy as using an editor to find-and-replace them. In practice, many organizations will likely write scripts to bulk-automate this process.
Other Airflow Improvements Simplify DAG Writing and Maintenance, Reduce Custom Coding
Another scheduling-related change in Airflow 2.4 is CronTriggerTimetable, a cron timetable that tells Airflow’s scheduler to use cron-like conventions. The background to this is that, by default, Airflow runs daily task instances 24 hours after their specified start time. So, if an author scheduled an end-of-week task to run on Sunday at 12 AM, it would actually run on Monday at 12 AM. (There’s a similar default interval for hourly tasks: if you schedule a task to run from 9-10 AM, it won’t actually start running until 10 AM.) A delay interval makes sense for certain types of batch jobs (e.g., end-of-day reports), but is a constant source of confusion for new Airflow users. Now, tasks can run on the day and at the time you specify, in accordance with cron conventions.
The new 2.4 release also augments Airflow’s dynamic task mapping capabilities, with support for expanded input types — namely expand_kwargs and expand_zip. Expand_kwargs is an escape hatch of sorts that enables DAG authors to address a large number of use cases; expand_zip , by contrast, is quite specific, albeit also quite useful: it tells Airflow to "zip" two lists together, such that a,b,c and d,e,f become (a,d), (b,e), and (c,f).
These additions, along with several others, help to reduce the amount of code that DAG authors need to write and maintain, because — as with the data-driven scheduling logic undergirding Airflow's new Dataset class — the necessary logic has now moved into Airflow itself.
Another example is a new UI option that administrators can use to configure a global task retry delay. Airflow’s default task retry delay is 300 seconds; previously, authors could change this by hardcoding it into their tasks. You can still do this — e.g., if you want to use a time limit other than the global value — but the new feature is a labor-saving alternative.
Similarly, Airflow 2.4’s option to reuse decorated task groups makes it much easier for authors to reuse collections of tasks to accommodate repeatable patterns in DAGs.
The Airflow UI is a locus of ongoing innovation. Also new in Airflow 2.4 is an ability to drill-down into logs from the default grid view, which enables users — either DAG authors or DevOps/SRE personnel — to click on a task (represented by a block in Airflow’s grid view) to see the log file associated with it, rather than being redirected to another page. The idea is to expose as much useful information as possible in an integrated UI workflow, so users don’t have to switch contexts.
Flexible Deferrable Operators to Replace Smart Sensors
For all its useful improvements, Airflow 2.4 is taking one capability away: smart sensors, first introduced in Airflow 2.0 (December 2020) as an experimental feature — a short-term fix, explicitly excepted from Airflow’s versioning policy — which DAG authors could use to trigger tasks to run in response to specific events. Smart sensors were useful, but they also had a few drawbacks: they worked for only a limited range of sensor-style workloads, had no redundancy, and had to run in the context of a custom DAG. Airflow 2.2 introduced a permanent solution to this problem — deferrable operators, a term used to describe a category of hooks, sensors, and operators capable of asynchronous operation — and included two novel async sensors, TimeSensorAsync and DateTimeSensorAsync. Deferrable operators are a more robust and flexible solution for supporting sensor-style event triggering. They support a broader range of use cases and workloads. Functionally, they far outstrip what you can do with smart sensors.
When Airflow 2.2.4 was released in February, support for smart sensors was officially deprecated, with a warning that support would be terminated as of Airflow 2.4; now, that Airflow 2.4 is available, smart sensors are no longer supported. The Airflow community produced only one known pre-built smart sensor, which has been superseded by an equivalent deferrable operator.
If you wrote smart sensors of your own, you can now reimplement them as deferrable operators. If you have questions about doing this, consider reaching out to us at Astronomer. Not only did we build the first deferrable operators for Airflow, we made them available under the Apache 2.0 license, and we’ve helped our customers reimplement their own smart sensors as deferrable operators. We can definitely be of assistance to you as you manage this breaking change.
An Upgrade That Cuts Complexity and Promotes Timely Delivery of Data
There’s a lot of amazing stuff in Airflow 2.4, but by any criteria, its support for datasets is the breakout star. Data-driven scheduling is going to change what organizations can do with Airflow. By augmenting Airflow with the built-in logic it needs to automatically manage different kinds of data-dependent events, the feature makes it much easier for data teams to break up large, monolithic DAGs into smaller, function- or process-specific DAGs — i.e., “datasets.” Data-driven scheduling allows organizations to more effectively optimize how, when, or under what conditions their pipelines run, enabling them to prioritize the timely delivery of data for business-critical processes.
For DAG authors, Airflow’s new Dataset class does away with a big source of tedium and frustration: the need to design elaborate logic to manage dependencies and control for different kinds of task failures between their DAGs. And from an operational standpoint, breaking up monolithic DAGs into discrete datasets ensures that they run reliably and are much easier to troubleshoot and maintain.
For the moment, data-driven scheduling in Airflow does have one significant limitation: dataset dependencies don't (yet) span separate Airflow deployments. You cannot have a run by a producer task in one deployment triggering a run by a consumer DAG in another. But for a novel implementation of a major new feature, data-driven scheduling is already hugely useful.
As this feature improves, it will become easier to track and visualize datasets within Airflow, as well as to manage and improve the quality of the data used to produce them. Organizations will be able to better understand how and for whom they’re producing datasets, along with what those people and teams are doing with them. They will be able to more easily identify redundant, infrequently used, or incomplete datasets, along with datasets that contain sensitive information, enabling them to more effectively govern the data produced and consumed by self-service users. The datasets capabilities we’re getting in Airflow 2.4 are just the beginning.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.