Apache Airflow® 2.3 — Everything You Need to Know
11 min read |
Believe it or not, Airflow 2.3 might be the most important release of Airflow to date.
That’s a bold claim. After all, Airflow 2.0 debuted with a refactored scheduler that eliminated a prior single point of failure and vastly improved performance. And then there’s Airflow 2.2, which introduced support for deferrable operators, allowing you to schedule and manage tasks to run asynchronously. This gives you new options for accommodating long-running tasks, as well as for scaling their Airflow environments.
So Airflow 2.0 and 2.2 were big releases — but 2.3 is arguably even bigger.
[tl;dr] What’s new in Airflow 2.3?
- Dynamic task mapping lets Airflow trigger tasks based on unpredictable input conditions
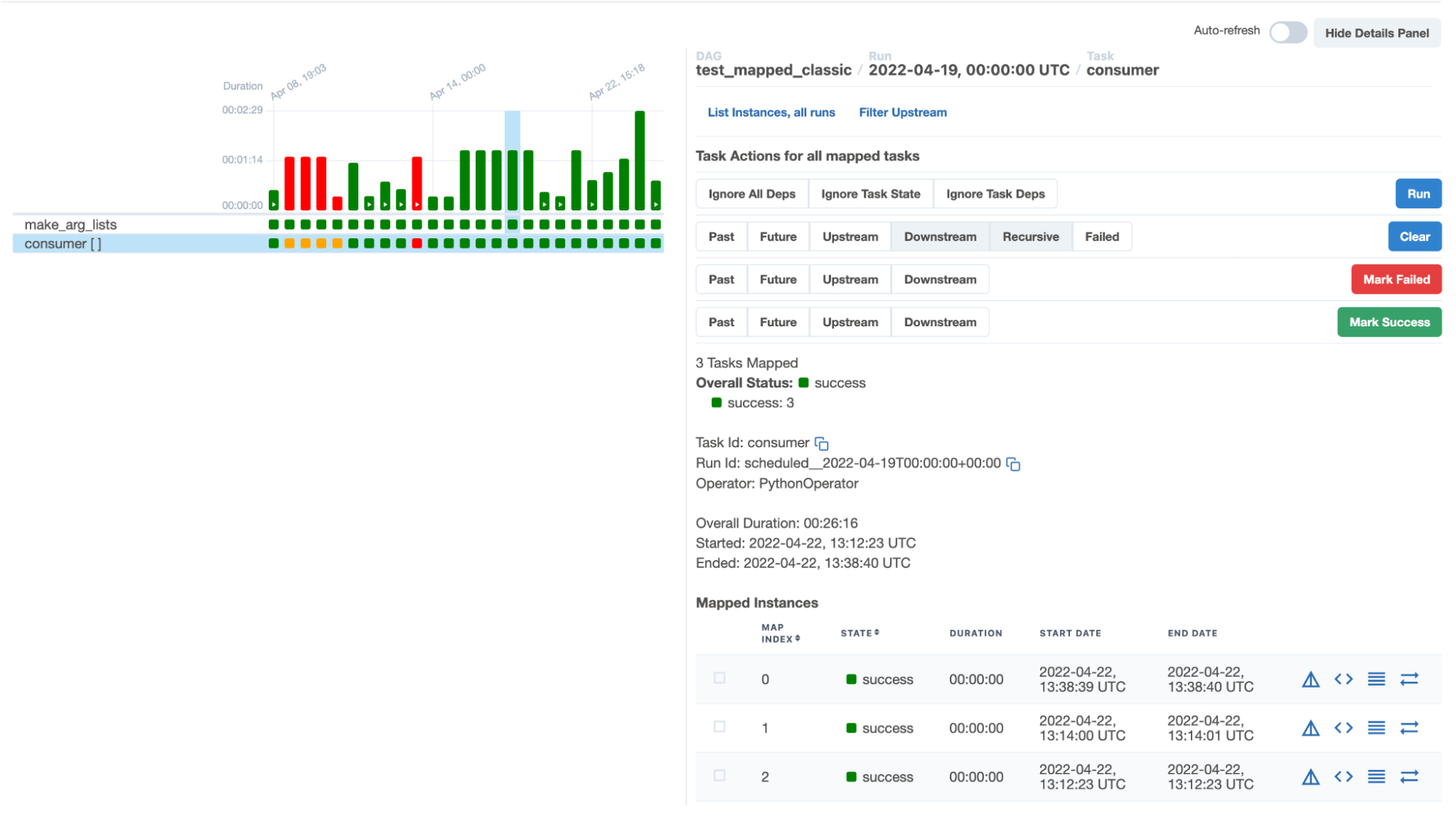
- A new, improved grid view that replaces the tree view
- A new LocalKubenetesExecutor you can use to balance tradeoffs between the LocalExecutor and KubernetesExecutor
- A new REST API endpoint that lets you bulk-pause/resume DAGs
- A new listener plugin API that tracks TaskInstance state changes
- New ability to store Airflow connections in JSON instead of URI format
- A new command built into the Airflow CLI that you can invoke to reserialize DAGs
Airflow 2.3 implements the dynamic task mapping API first described in AIP-42 — a genuine game changer for the hundreds of thousands of teams that depend on Airflow today. For one thing, it’s an extremely useful new capability that becomes available to users with just a minor version upgrade, meaning it maintains full backward compatibility with Airflow 2.x. For another,dynamic task mapping is an inceptive feature — a new capacity the Apache Airflow® community will build on as we keep expanding what it is possible to do with Airflow.
Task mapping is a meat-and-potatoes kind of thing. Its archetypal pattern is a for-loop: for any collection — of files, tuples, models, etc. — run the same task once per item in the collection. Dynamic tasks are essential when (for example) you can’t predict how many files (or tuples, models, etc.) you’re going to need to process: you just know you’re going to need to process some number of them.
Imagine being able to map tasks to variables, DAG configs, or even database tables. Instead of manually invoking an operator to perform these and similar tasks, Airflow is now able to dynamically change the topology of your workflow at runtime. The upshot is that dynamic task mapping pays immediate dividends right now — and will pay even bigger dividends in future.
Not only does this type of for-loop describe a common ETL pattern, it encompasses a very wide variety of use cases, about which more below.
Still, while dynamic task mapping may be the breakout hit of Airflow 2.3, the new release is not a one-hit wonder. Airflow 2.3 also queues up a new grid view, which replaces Airflow’s default tree view; a local Kubernetes (K8s) executor, which gives users a new, useful option for running different kinds of tasks; a new option for serializing Airflow connections; and a slew of other features.
Below, we dig into Airflow 2.3 — starting with dynamic task mapping.
Dynamic Task Mapping in Airflow
The case for dynamic task mapping is obvious enough. Basically, you have a scenario in which you need to process n items in a collection — say, files in a directory, a container in object storage, or a bucket in AWS S3. You can’t predict the value of n, but you want Airflow to automatically schedule and run n tasks against these files.
There were basically two ways to handle this scenario with Airflow prior to 2.3.
The first was to allocate a fixed number of Airflow workers and task them with pulling and processing the files in the collection. This scheme permitted parallel processing — but with a catch, which had to do with inefficient parallelization: Because you could not predict the number of files you’d be processing, you would either over- or under-provision Airflow workers to perform this work. There were ways to deal with this, such as sharding your workload across available workers and keeping them busy (e.g., by feeding even-numbered tasks to even-numbered workers, odd-numbered tasks to odd-numbered workers). But this scheme didn’t make optimal use of Airflow’s built-in parallelism, and it introduced cost and complexity via custom code that had to be maintained.
The second way was to create a monolithic task that processed all of the files one at a time, using just a single Airflow worker, instead of in parallel, using all available workers.
Dynamic task mapping permits Airflow’s scheduler to trigger tasks based on context: given this input — a set of files in an S3 bucket — run these tasks. The number of tasks can change based on the number of files; you no longer have to configure a static number of tasks.
As of Airflow 2.3, you can use dynamic task mapping to hook into S3, list any new files, and run separate instances of the same task for each file. You don’t have to worry about keeping your Airflow workers busy, because Airflow’s scheduler automatically optimizes for available parallelism.
Dynamic task mapping not only gives you a means to easily parallelize these operations across your available Airflow workers, but also makes it easier to rerun individual tasks (e.g., in the case of failure) by giving you vastly improved visibility into the success or failure of these tasks. Imagine that you create a monolithic task to process all of the files in the S3 bucket, and that one or more steps in this task fail. In past versions of Airflow, you’d have to parse the Airflow log file generated by your monolithic task to determine which step failed and why. In 2.3, when a dynamically mapped task fails, it generates a discrete alert for that step in Airflow. This enables you to zero in on the specific task and troubleshoot from there. If appropriate, you can easily requeue the task and run it all over again.
Dynamic Task Mapping in Action
As noted above, dynamic task mapping in Airflow 2.3 supports a large number of patterns and use cases — a number that will grow as Airflow evolves. One common use case — an ETL pattern that involves pulling data from a cloud service, transforming it, and loading it into a relational database — is laid out below. Imagine that you want to pull data from a REST API — say, a list of Pokémon characters, along with their distinctive abilities. Your ultimate goal is to load this data into a special pokemon_chars table in your Snowflake data warehouse.
To start things off, you have a task that (1) GETS character data (a list of name-value pairs) from the Pokémon REST API and (2) serializes this list to a CSV file in an S3 bucket. Your next task, (3), parses the CSV list in order to extract each Pokémon name-value pair, and (4) passes them (e.g., via Airflow’s TaskFlow API) to your next, dynamically mapped task.
At this point, the Airflow scheduler queues the same task 908 times — the current number of Pokémon characters — for each name-value pair. The neat thing is that each of these 908 tasks runs in parallel, the scheduler distributing them across available Airflow workers. (If you’re running Airflow in our fully managed service, Astro, it will automatically scale to provision as many Airflow workers as your pre-defined capacity policies permit. Learn more about Astro.) Each worker serializes its name-value pair as a separate CSV file in a subdirectory in the same S3 bucket. From there, (5) the scheduler queues the 908 CSV files as a single task and uses Airflow’s S3toSnowflakeOperator to extract the name-value pairs and pass them to Snowflake’s REST API. Finally, (6) the Snowflake database instantiates this data in your pokemon_chars table.
Voila!
Airflow 2.3 Packs Plenty of Other New Features, Too
Airflow’s new grid view is also a significant change. The tree view it replaces was not ideal for representing DAGs and their topologies, since a tree cannot natively represent a DAG that has more than one path, such as a task with branching dependencies. The tree view could only represent these paths by displaying multiple, separate instances of the same task. So if a task had three paths, Airflow’s tree view would show three instances of the same task — confusing even for expert users. The grid view, by contrast, is ideal for displaying complex DAGs, such as tasks that have multiple dependencies.
The grid view also offers first-class support for Airflow task groups. The tree view chained task group IDs together, resulting in repetitive text and, occasionally, broken views. In the new grid view, task groups display summary information and can be expanded or collapsed as needed.
The new grid view also dynamically generates lines and hover effects based on the task you’re inspecting, and displays the durations of your DAG runs; this lets you quickly track performance — and makes it easier to spot potential problems. These are just a few of the improvements the new grid view brings. It’s an extremely useful new feature.
Airflow 2.3’s new local K8s executor allows you to be selective about which tasks you send out to a new pod in your K8s cluster — i.e., you can either use a local Airflow executor to run your tasks within the scheduler service or send them out to a discrete K8s pod. Kubernetes is powerful, to be sure, but it’s overkill for many use cases. (It also adds layers of latency that the local executor does not.) The upshot is that for many types of tasks — especially lightweight ones — it’s faster (and, arguably, just as reliable) to run them in Airflow’s local executor, as against spinning up a new K8s pod. This is a non-trivial gain.
And the new release’s ability to store Airflow connections in JSON (rather than in Airflow URI) format is a relatively simple feature that — for some users — could nevertheless be a hugely welcomed change. Earlier versions stored connection information in Airflow’s URI format, and there are cases in which that format can be tricky to work with. JSON provides a simple, human-readable alternative.
Altogether, Airflow 2.3 introduces more than a dozen new features, including, in addition to the above, a new command in the Airflow CLI for reserializing DAGs, a new listener plugin API that tracks TaskInstance state changes, a new REST API endpoint for bulk-pausing/resuming DAGs, and other ease-of-use (or fit-and-finish) features.
Concluding Thoughts
Airflow 2.3 is a landmark release. Its new dynamic task mapping API, in particular, is a foundational feature that will improve iteratively in each new release of Airflow.
You might ask, if Airflow 2.3 is such a big release, why didn’t Airflow’s maintainers just make it Airflow 3? The answer is that they wanted more users to get immediate access to Airflow 2.3’s great new features. This release maintains full backward compatibility with all Airflow 2.x releases: it will run all of your DAGs, tasks, and custom code without modification.
Airflow continues to improve at a phenomenal rate. To take just one metric: there have been almost 5,000 commits (up to and including the release of Airflow 2.3) since Airflow 2.0 was released in December 2020. This means 30% of all Airflow commits ever have occurred in just the last 16 months.
And as Airflow improves, it eliminates an expanding share of the tedious, repetitive work that would otherwise be performed by users. The dynamic task mapping API formalizes and integrates use case-specific logic that would otherwise have to be created and maintained as code by skilled users. By integrating this logic, Airflow makes it easier for all users to design their tasks to specific patterns — ETL, ELT, long-running tasks, and change data capture, to name a few — without having to write and maintain custom code to support these patterns.
In a sense, Airflow is getting “smarter,” in the process freeing users to focus on optimizing the performance and reliability of their tasks. To the extent that improvements in Airflow eliminate the vicious cycle of creating and maintaining custom code, you could say that a portion of the burden of managing technical debt goes away, too.
Over the next 12 months and beyond, Airflow will evolve to support more and varied types of dynamic tasks. It will gain the ability to map tasks to variables, to DAG configs, to database tables, and so on.
What’s possible in Airflow today with dynamically mapped tasks is only the beginning.
Learn about the new features in Airflow 2.4 in our comprehensive overview.
If you’d like to know more about Airflow 2.3’s new and improved features, join our webinar with Airflow experts Kenten Danas and Viraj Parekh.
And to learn more about our fully managed data orchestration platform, Astro — which supports Airflow 2.3 today and will give you day-one access to all future Airflow releases — reach out for a demo customized around your organization’s orchestration needs.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.