Databricks vs. Airflow From a Management Perspective, Part 2
10 min read |
This is the second in a series of blog posts comparing Databricks and Airflow, this time from a management perspective. In my first post, I delved into the developer experience on Databricks and Apache Airflow®, highlighting their respective strengths and challenges in building a typical ETL workflow. If you’re interested in learning more about the basics of the two platforms, and what it looks like to develop data pipelines in both, give it a read!
In this follow up post, I’ll be comparing both of these platforms from a production management perspective. Instead of approaching it like a developer, I’ll endeavor to give you a comparison of what it looks like to manage both at scale. To do this, I’ll be examining things like monitoring tooling and scalability in both of these platforms, as well as how easily they can integrate with other common tools.
One thing we covered in the first blog that’s relevant to managers is the cost of both services, so if you’re interested in learning more about it, please check out the first post!
Ease of Setup and Configuration
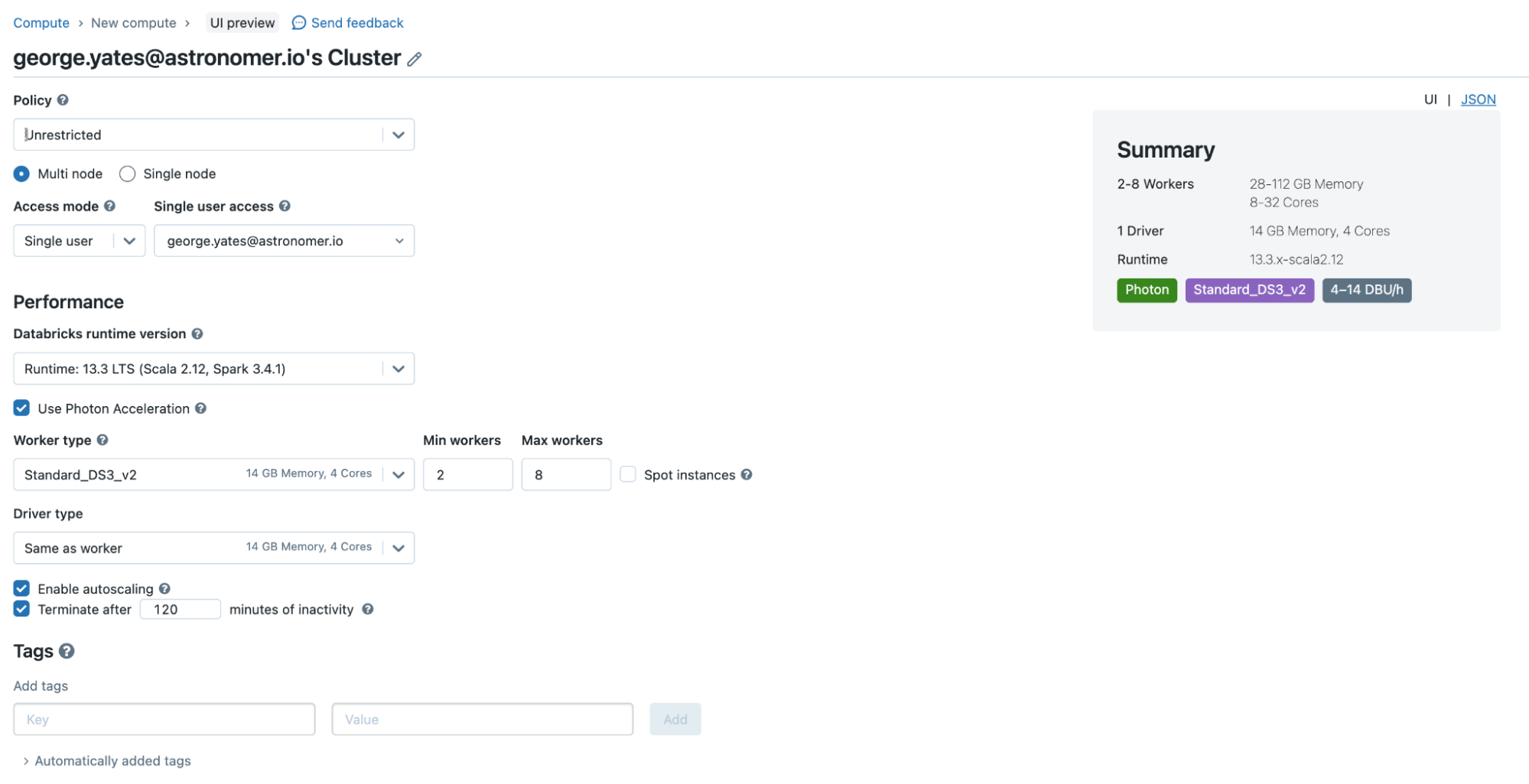
Databricks
As a cloud-native platform, Databricks eliminates the need for manual infrastructure setup and management. Users can choose pre-configured Spark clusters tailored for various data tasks, from analytics to machine learning, and deploy them from the Databricks UI.
However, this setup does necessitate access to an external cloud account, and you’ll need to go through some networking setup to allow Databricks to deploy cloud resources for you. Once you’ve gone through that process, subsequent deployments are just a click of a button.
One downside of this approach is that you are restricted to using compute in configuration arrangements that have been determined by Databricks, with no support for custom compute configurations. Since Databricks is a paid cloud service, you can utilize their documentation and customer service agents to help troubleshoot issues.
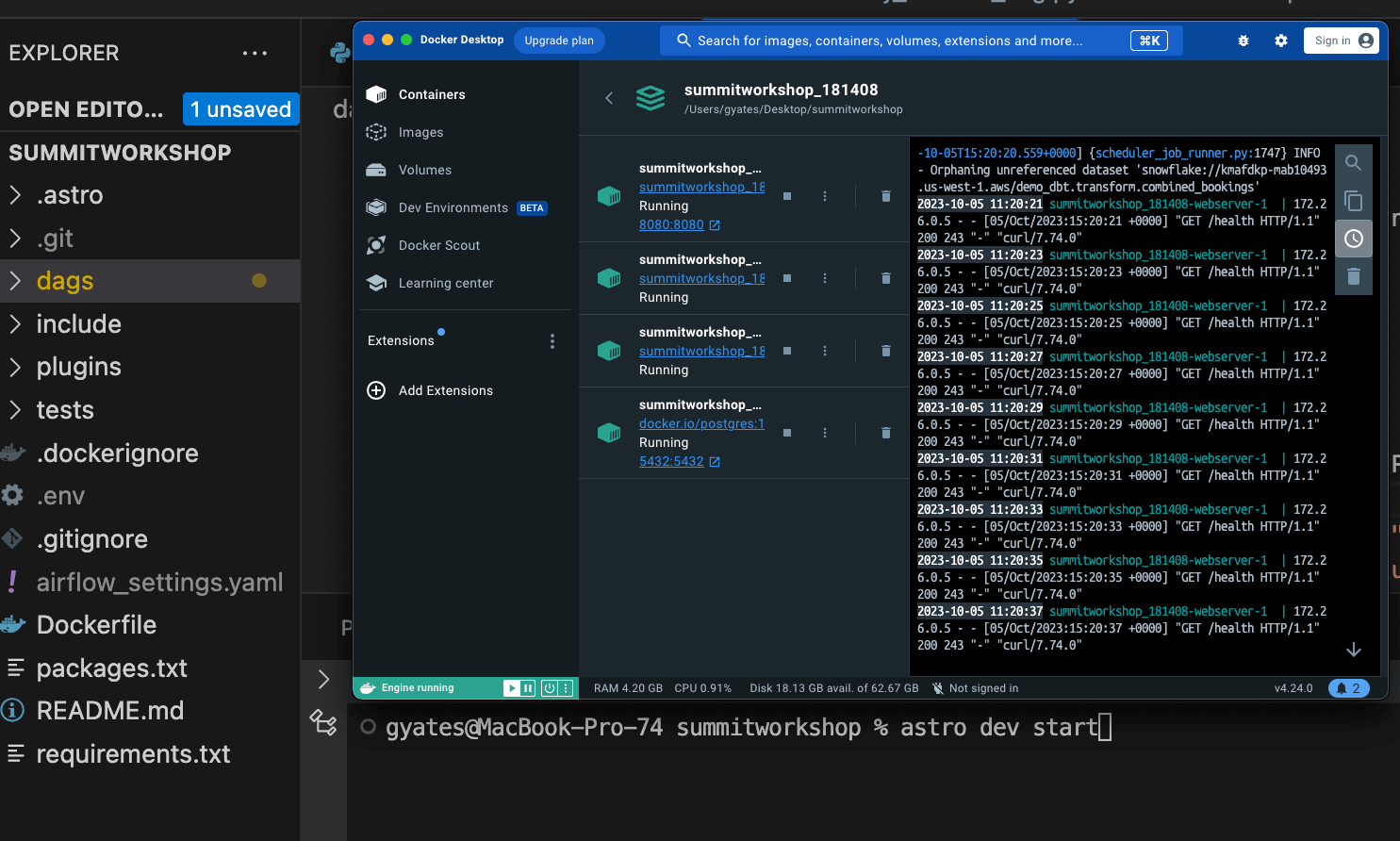
Airflow
Airflow, being an open-source platform, requires a more hands-on approach to setup and configuration. While this means there's an initial learning curve, it also offers greater flexibility and control over the environment.
Users need to manually set up the Airflow scheduler, trigger, web server, and worker nodes, ensuring they are correctly interconnected. Configuration files, like the airflow.cfg, allow for fine-tuning of the platform's behavior and integrations.
While the setup process might be more involved compared to managed platforms like Databricks, the payoff is a highly customizable environment tailored to specific workflow needs. Many users choose to go with managed Airflow services like Astronomer, which take away the headache of setting up Airflow manually while maintaining full customizability.
The extensive documentation and active community further assist in guiding new users through the setup process.
Ease of Monitoring
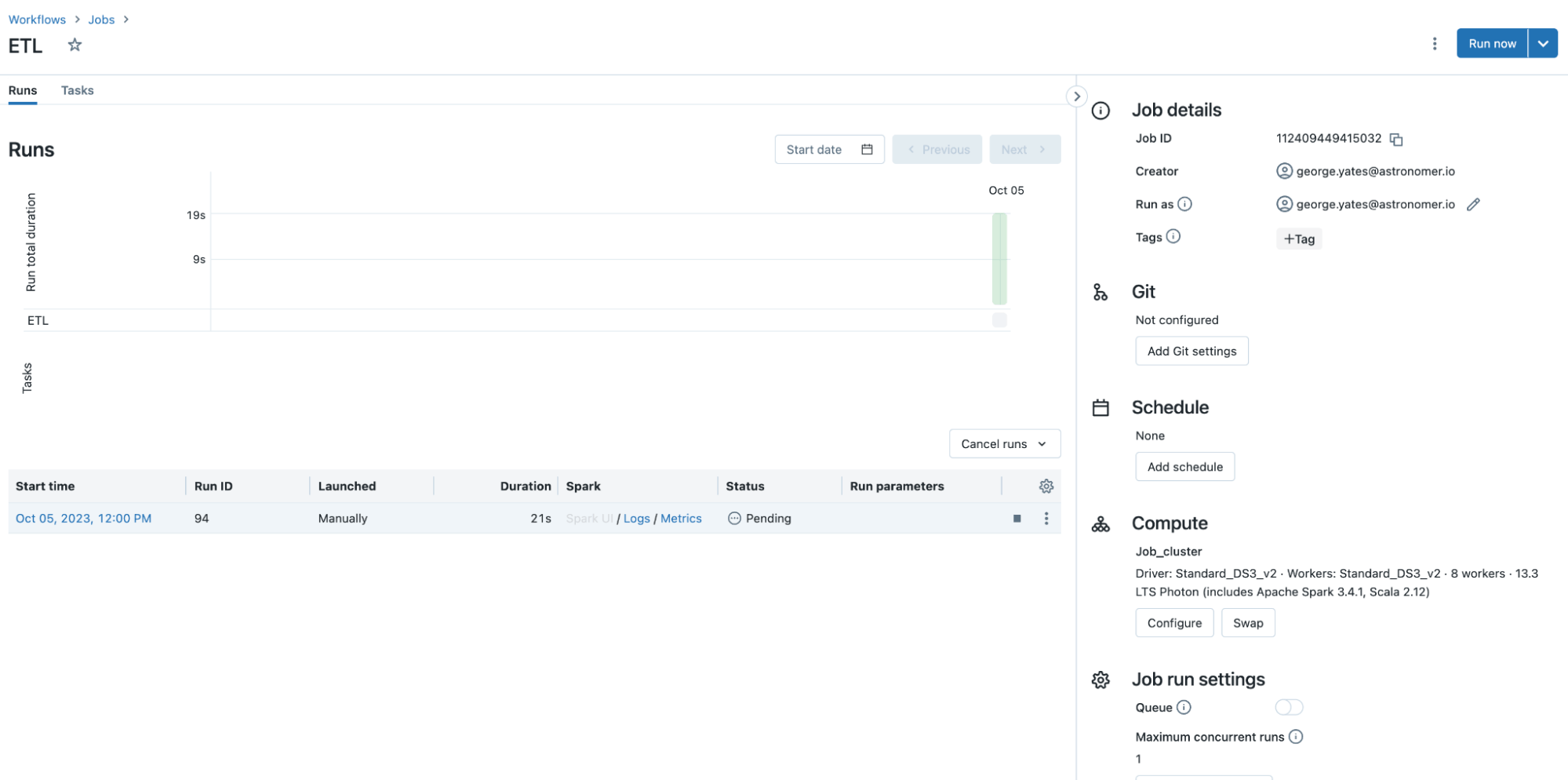
Databricks
Databricks provides a robust suite of monitoring tools designed to give users a clear view of their data operations within Databricks. The platform's built-in dashboards offer real-time insights into the performance and status of jobs, clusters, and notebooks.
Users can easily track the progress of running tasks, view historical job metrics, and diagnose issues with detailed logs. Alerts and notifications can be set up to inform teams of any anomalies or failures, ensuring timely intervention.
Additionally, Databricks' integration with monitoring solutions like Prometheus and Grafana allows you to bring Databricks metrics into a central monitoring platform.
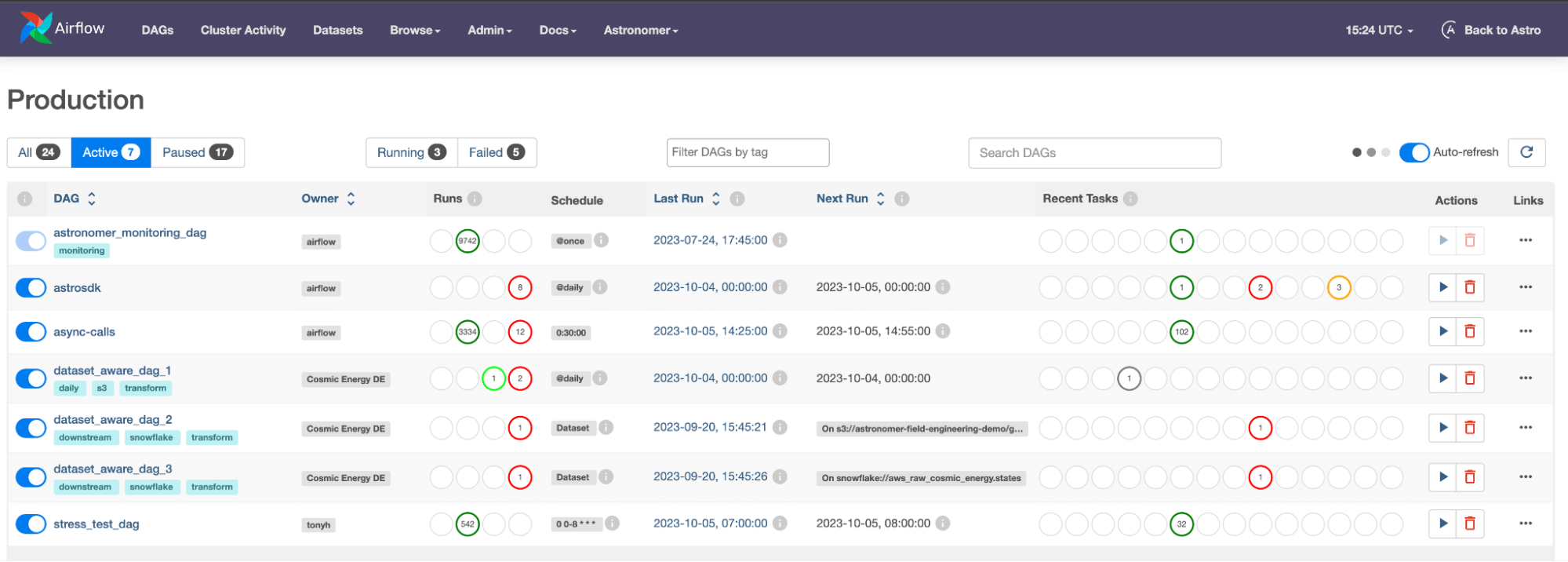
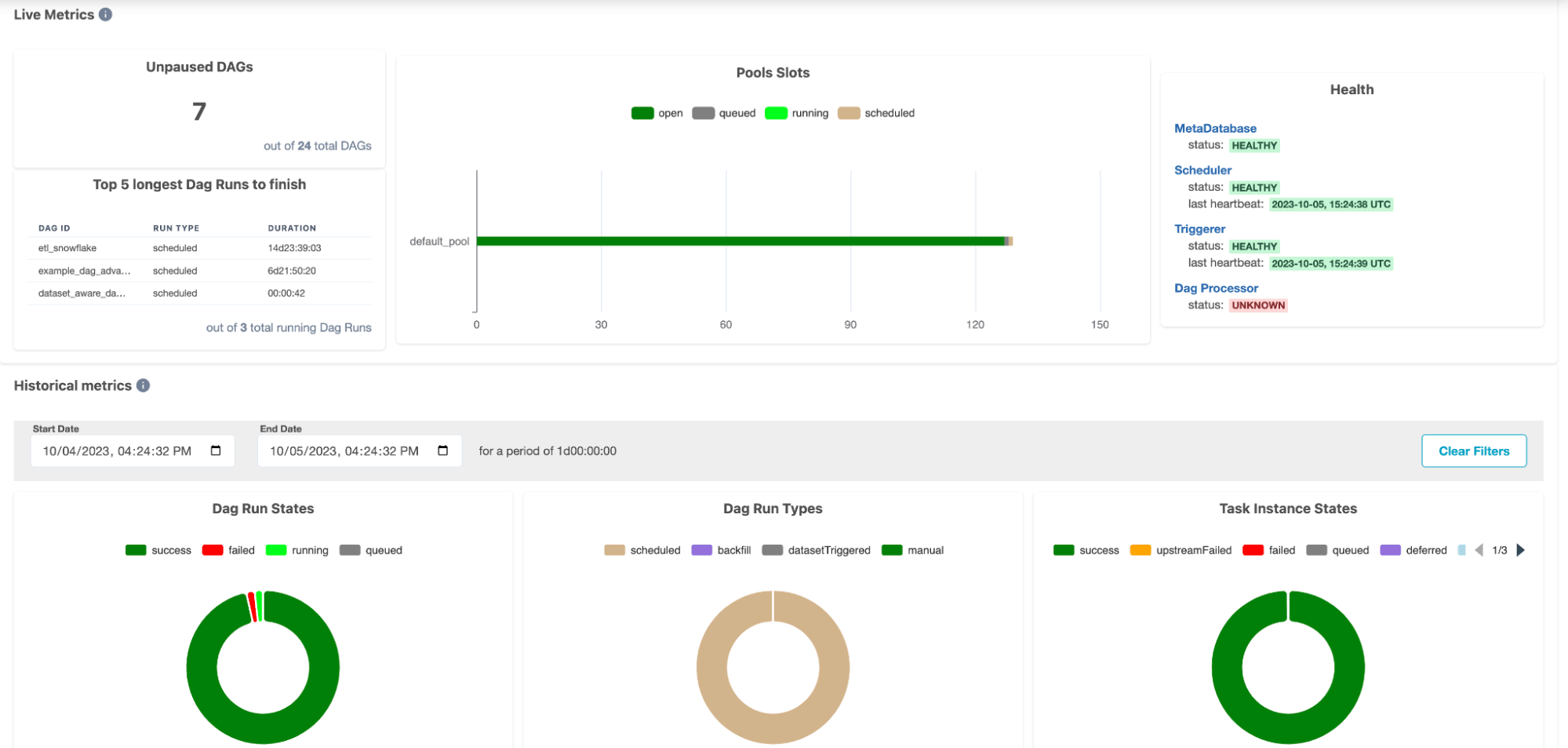
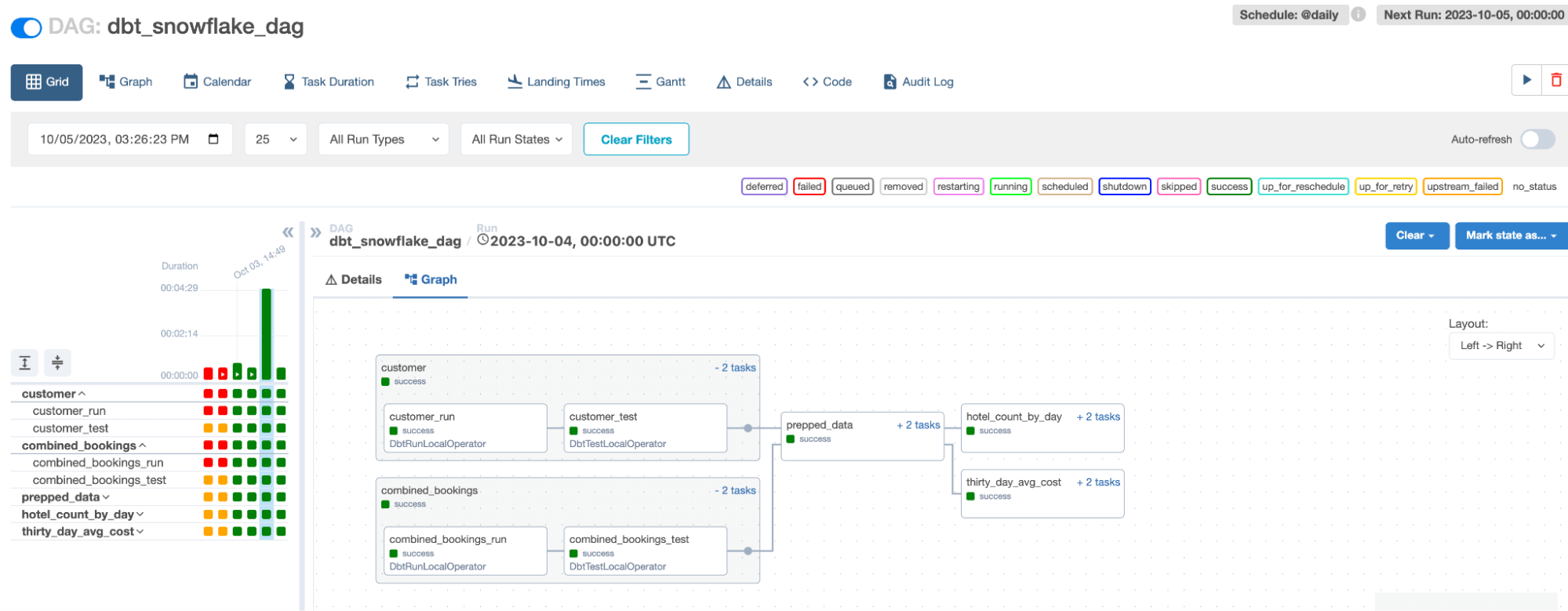
Airflow
Airflow's web-based user interface stands out as one of its primary monitoring tools. Through this UI, users can visually track the progress of their workflows, known as Directed Acyclic Graphs (DAGs), and get a granular view of each task's status. Color-coded states indicate the health and progress of tasks, making it easy to identify bottlenecks or failures. Detailed logs for each task provide insights into execution details and potential issues.
In Airflow 2.7, there is now a cluster activity page as well, where you can monitor the health of your underlying compute nodes. A key benefit of Airflow is that these monitoring capabilities can be layered onto any service that Airflow is managing. This allows you to do things like add retry operations or set up custom alerting mechanisms for any external application or service that Airflow is managing.
Additionally, Airflow offers integrations with external monitoring tools like Datadog, allowing teams to integrate Airflow’s logging capabilities into their existing monitoring stack.
Integrations
Databricks
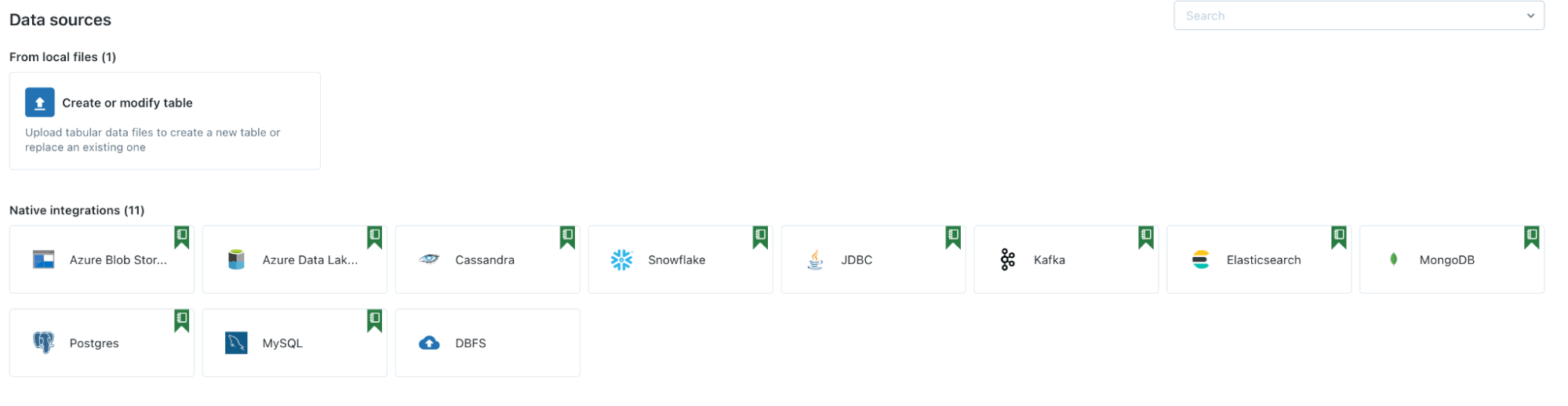

Databricks’ approach to integrations is to keep them at the code level, requiring users to define connection details in notebook code cells in order to import/export data from external services like Snowflake or S3. To support this, Databricks provides many pre-formatted connection code blocks that you can copy and paste into your notebooks to interact with external tools.
All the end user then needs to do is fill out their connection details, and they can then use a connection function within their code to perform external operations. Unfortunately, there is no centralized connection management system, so you’ll have to recreate connections for each new notebook or pipeline that you’re creating.
Additionally, if Databricks doesn’t offer an official connector, there isn’t an easy way to create a custom connector to add unsupported systems. However, there is a rich API to programmatically manage Databricks operations, making it easy to integrate into existing workflows. This makes a combination of Databricks and Airflow a perfect fit, as Airflow allows you to manage almost any system in conjunction with your Databricks workflows.
Airflow
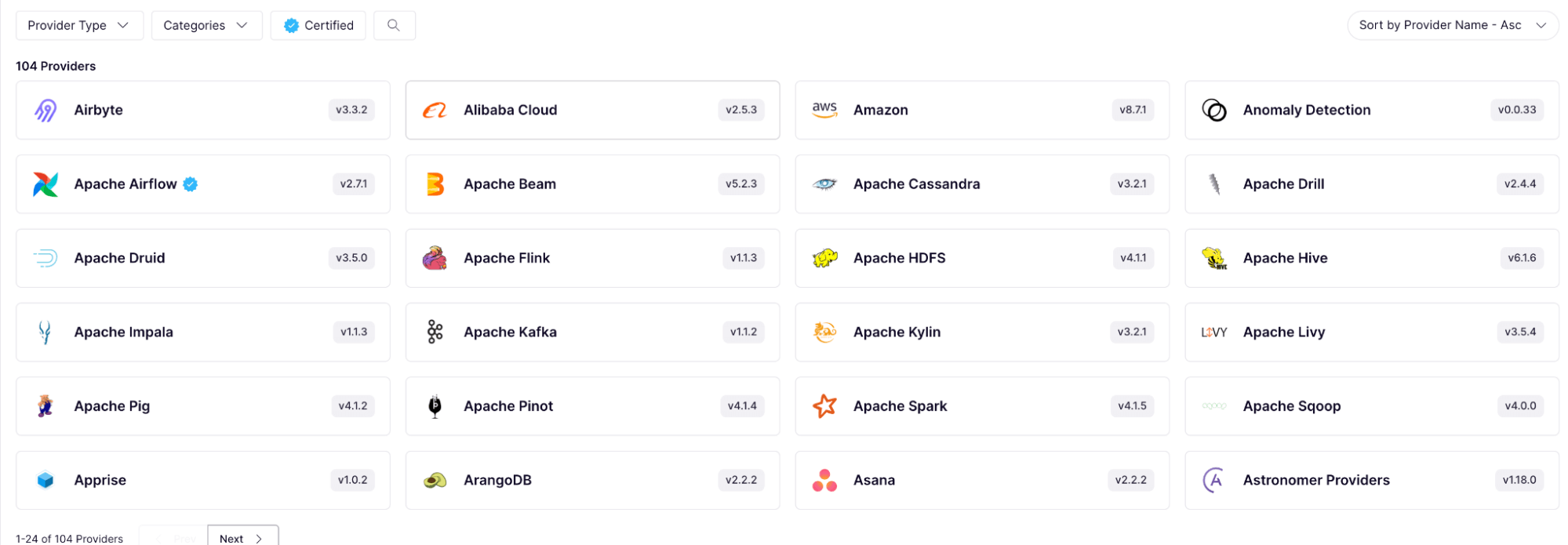
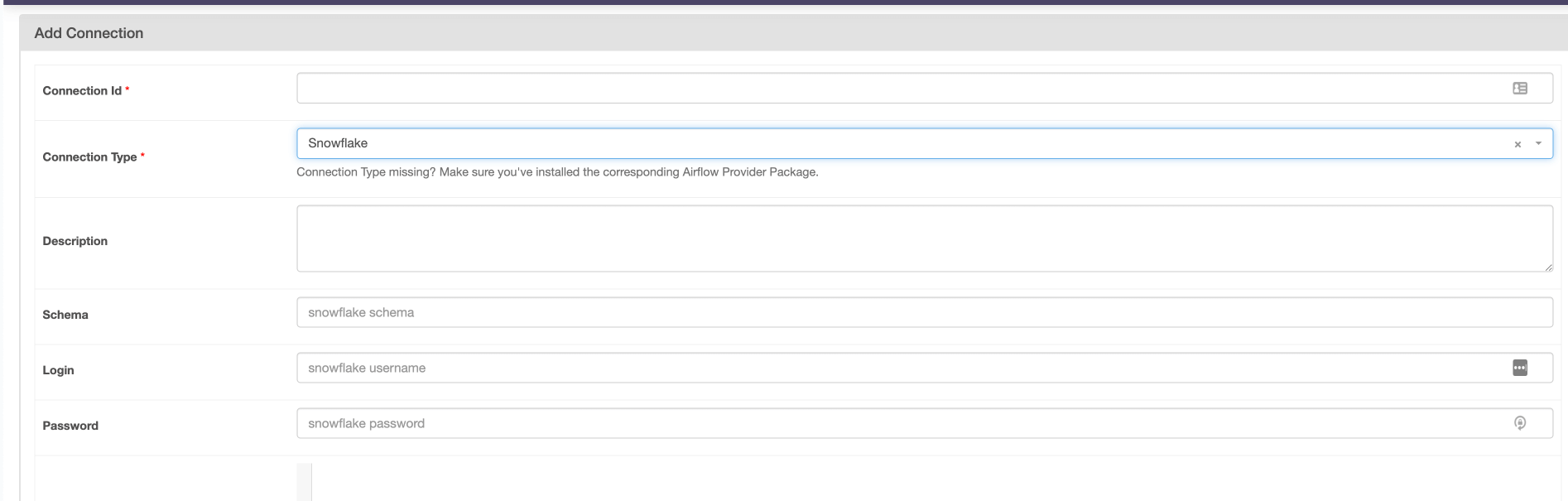
Airflow's strength in integrations lies in its extensible architecture. Being an open-source platform, it boasts a vast library of providers developed by its active community. These providers contain hooks and operators that enable Airflow to integrate with a plethora of data tools, cloud providers, and databases. Whether it's Amazon S3, Databricks, dbt, or Snowflake, there's likely an operator or hook available to facilitate the integration.
Moreover, if a specific integration isn’t available, Airflow's design allows developers to create custom operators to meet their unique requirements and then save them for repeated use. Finally, Airflow also has a dedicated connection management system, allowing you to define connection details once, and reference them with a single string throughout your data pipelines.
This means that Airflow can be tailored to fit into virtually any modern data stack, making it the go-to choice for teams looking for a customizable orchestration tool that enhances their existing systems.
Scalability and Performance
Databricks
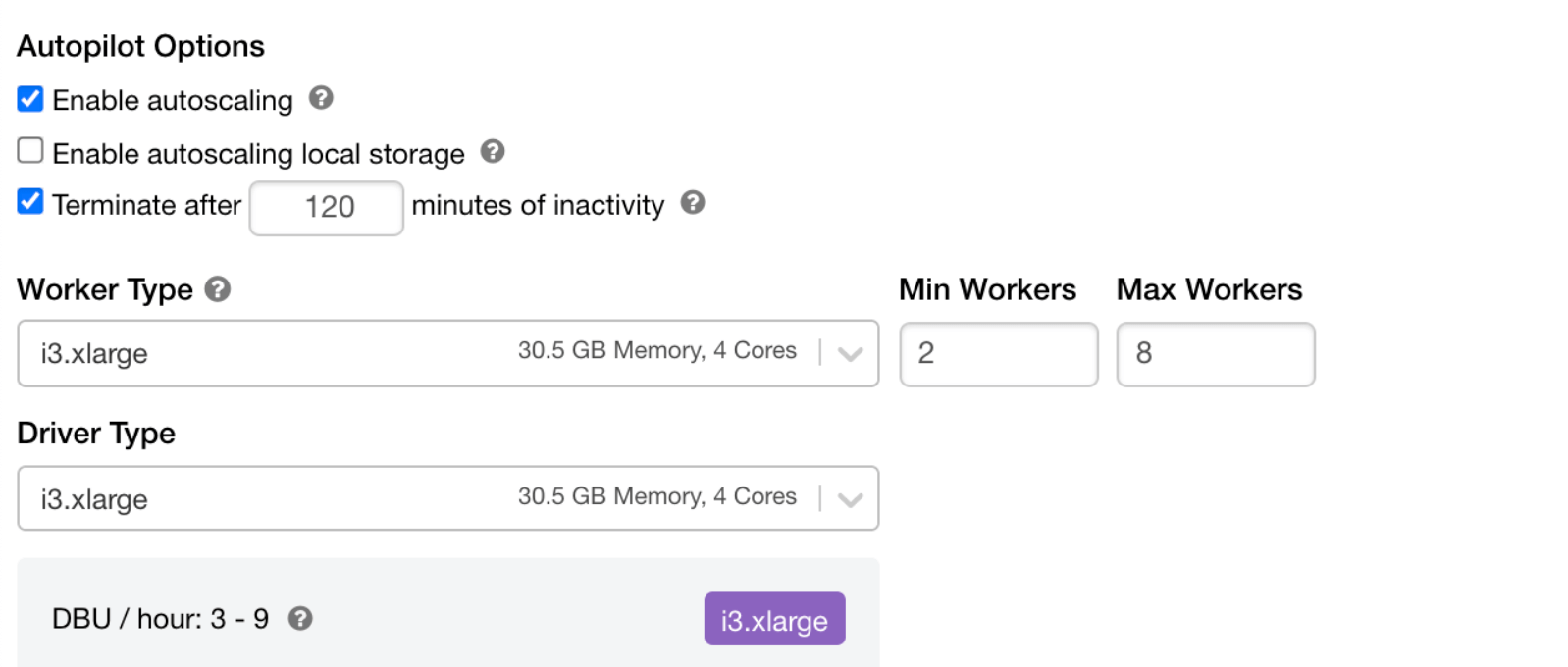
Built on top of Apache Spark, Databricks is optimized for big data processing, ensuring rapid data transformations, analytics, and machine learning tasks. Its cloud-native design allows for dynamic scaling, where clusters can be automatically resized based on workload demands, ensuring efficient resource utilization.
This auto-scaling capability means that Databricks can handle sudden spikes in data volume or computational needs without manual intervention. Additionally, Databricks' Delta Engine boosts performance by optimizing query execution, ensuring that even the most complex analytical tasks are executed swiftly.
Both auto-scaling and query optimization are very important within Databricks, as Spark clusters processing massive amounts of data can rapidly become very expensive if not properly managed. With its combination of Spark's distributed computing capabilities and cloud infrastructure, Databricks stands out as a high-performance data processing platform that scales with ease.
Airflow
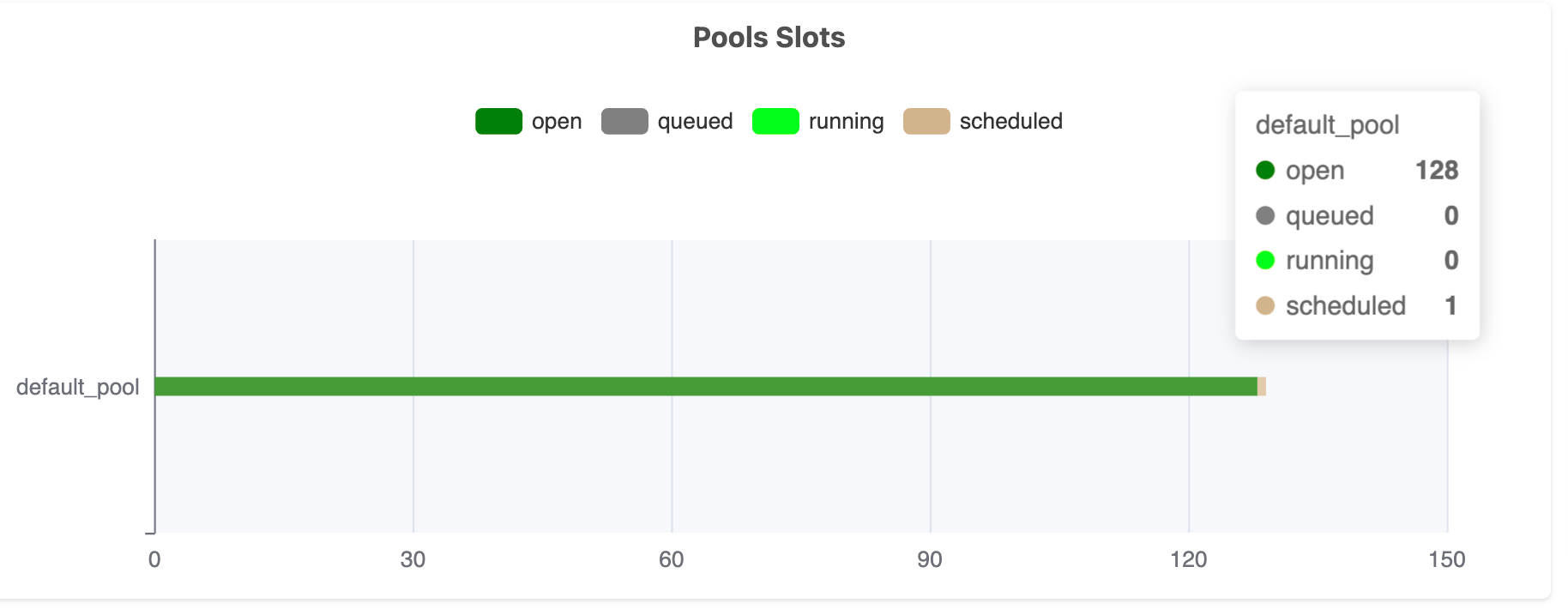

Airflow's modular design allows it to scale according to the demands of the workflows it orchestrates. By distributing tasks across multiple worker nodes to execute them in parallel, Airflow ensures that large workflows are executed efficiently.
Its CeleryExecutor, for instance, allows for the distribution of tasks across a cluster of worker machines, enabling parallel execution and enhancing performance. As workflows grow in complexity and volume, Airflow can be scaled horizontally by adding more workers to the cluster. Some managed Airflow services like Astronomer also provide auto-scaling capabilities to handle scaling as efficiently as possible.
Airflow’s open architecture also means you can choose to use whatever compute type is best suited to run your tasks, giving you additional flexibility to optimize your environment. Finally, because Airflow’s advantages come with its ability to manage external services, you can run most operations in those external services, leveraging their specializations to run each operation as efficiently as possible. An example of this would be using Airflow to ingest large amounts of data directly into Snowflake to make use of its scalable storage and compute, then kicking off a Databricks workflow to transform that data efficiently through an optimized Spark cluster.
Flexibility and Customization
Databricks
Databricks, while being a proprietary platform, offers a good degree of flexibility to its users. Its notebook-based environment supports multiple programming languages, including Python, Scala, SQL, and R, allowing data professionals to work in their preferred language. These notebooks can be customized with widgets and interactive visualizations, enhancing the user experience.
Additionally, Databricks provides APIs that enable integration with a decent set of external tools and platforms, allowing teams to tailor the environment to their specific needs. However, being a managed platform, there are some limitations in terms of deep customizations compared to open-source alternatives.
As mentioned earlier, if a service doesn’t already have a supported Databricks connector, it can be very difficult to link it to Databricks only using Databricks’ native tooling.
Airflow

Airflow's open-source nature is its biggest strength when it comes to flexibility and customization. Organizations have the freedom to modify the source code and underlying infrastructure to fit their specific requirements, making it one of the most adaptable data orchestration tools available.
This flexibility can be anything from altering environment variables to change how tasks are run, to adding new buttons to the Airflow UI that link out to external pages. Its plugin architecture is particularly extensible; users can create custom operators, hooks, and sensors to extend Airflow's functionality. This means that if a specific feature or integration isn't available out-of-the-box, it can be developed and added.
The platform's configuration files provide granular control over its behavior, allowing for fine-tuning based on specific operational needs. With its open architecture and active community, Airflow ensures that teams are not confined to a fixed set of features but can mold the platform as they see fit.
Conclusion
After going through both platforms from a management perspective, the advantages/limitations of each became crystal clear.
Databricks, a cloud-native platform, offers ease in setup and robust monitoring tools, emphasizing its strength in scalability and performance, especially for big data processing. However, its proprietary nature and focus on efficient big data processing means there are limitations in deep customizations, like connecting to unsupported services.
On the other hand, Airflow, an open-source platform, requires a more hands-on approach to setup but offers unparalleled flexibility and customization to suit any use case. Its extensible architecture allows for a vast range of integrations and its modular design ensures scalability.
Both platforms have their strengths, but for teams seeking a highly customizable and adaptable data orchestration tool to manage the modern data stack, Airflow stands out. By no means does this mean don’t use Databricks, instead I suggest using it as a part of your Airflow pipeline to perform its specialty, big data processing. Then, you can connect it to the rest of your data pipeline to leverage other systems strengths, while Airflow acts as your single pane of glass across all of your tools!

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.