Introducing the Astro Cloud IDE
9 min read |
The vibrant open-source community around Apache Airflow® has been innovating and defining new ways of authoring pipelines since the project’s inception. Powerful new features like dynamic task mapping and data-aware scheduling have increased productivity and allowed for more expressive workflows for the data engineer. (For more context on the evolution of DAG writing, check out my colleague Pete DeJoy’s post, “A Short History of DAG Writing.”)
Meanwhile, as the general need for data has increased — and with it, the need for broad access to data orchestration across organizations — we at Astronomer have been working to improve the Airflow DAG authoring experience. Airflow’s ability to express pipelines and orchestration logic as code is powerful, but when the only way to define pipelines is via Airflow’s domain-specific language, it becomes restrictive for those who don’t know Airflow well.
Our cloud-based orchestration platform, Astro, has made Airflow easier to use for a wide variety of data practitioners, and today we’re excited to introduce a new feature that makes the Astro experience even more accessible: the Astro Cloud IDE, a notebook-inspired tool for writing data pipelines. The main interface of the IDE makes it easy to author Airflow pipelines using blocks of vanilla Python and SQL. Users can easily define tasks, pipelines, and connections without knowing Airflow.
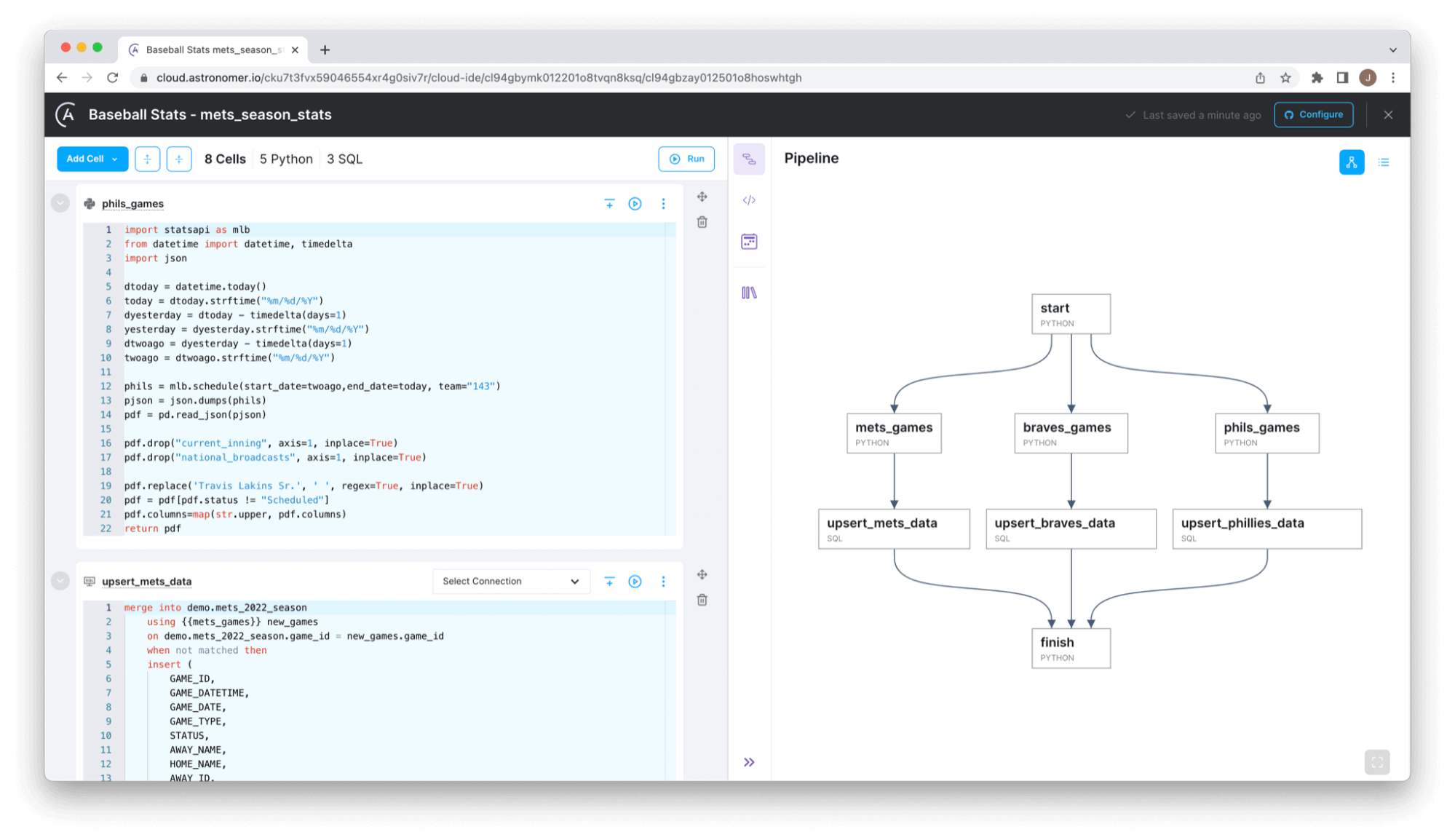
Figure 1: The Cloud IDE pipeline editor, showing an example pipeline composed of Python and SQL cells.
To understand the power of the IDE, imagine a common orchestration use case: A data analyst, Maggie, has been tasked with creating a dashboard to show her company's monthly active users (MAU). The dashboard data needs to be refreshed nightly so that stakeholders are always looking at the latest information. To do this, Maggie must extract user information from a data warehouse, aggregate it, and write the aggregated data to a new table, all on a nightly schedule. Traditionally, this would be handled in one of two ways:
- Maggie would write a SQL query in her editor of choice (e.g., the Snowflake UI). Once the query was finalized, she would send it to her colleague on the data engineering team, Sophia, to get it scheduled in Airflow.
- Or, Maggie would understand Airflow well enough to author the data pipeline herself; to do so, she would need to run Airflow locally and switch between many interfaces (her SQL query editor, the Airflow UI, and her terminal).
These solutions put a significant burden on either Sophia, the data engineer, or Maggie, the data analyst. In the first option, Sophia is pulled away from her own workload and becomes responsible for productionizing someone else’s code. In the second, Maggie must learn how to author, run, and schedule Airflow DAGs, in addition to doing her work as a data analyst.
Get a demo to see the Astro Cloud IDE in action.
For the Data Analyst: From Idea to Airflow DAG in Less than an Hour
Let's look at how the Astro Cloud IDE empowers Maggie (the data analyst) to self-service her orchestration needs.
Maggie logs into the Cloud IDE and finds her project, which is where pipelines, connections, requirements, and other configurations are defined. Once she’s in her project, she can create a new pipeline. After doing that, she is taken to the pipeline editor. The left side of the pipeline editor shows the notebook view (Figure 2, below), where she can add new Python and/or SQL cells, or edit existing cells. The right side contains a sidebar with graph and code views, a scheduling interface, and an environment section. The environment section contains all the context Maggie needs to create her pipeline — things like Python requirements, connections, and variables.
Figure 2: Creating a new pipeline in the Cloud IDE.
When Maggie goes to the Connections section in her Environment tab, she sees the Snowflake connection set up by Sophia. She clicks Add Cell, selects SQL, and now she's ready to start writing her query to get the user data.
As soon as she writes her first draft of the query, Maggie can execute it and see the results, just as she is accustomed to doing in SQL worksheets. She notices that a handful of customers only log in and take no other action, and she decides to exclude those for her MAU count. Once she updates the query, she can instantly re-run it and see her desired results, promoting rapid prototyping and development.
Figure 3: Writing and running SQL to query a Snowflake table.
After she's done getting the rows she wants, Maggie needs to aggregate the rows. Having had a bit of experience working with Pandas DataFrames, she decides to do this aggregation in Python. After she adds her Python cell, she can reference the SQL results by name, and the Astro Cloud IDE will automatically convert her SQL results to a Pandas DataFrame. She writes her .groupby()statement and executes it, seeing her results below the cell. When she glances to the right to look at her pipeline graph, she notices the Cloud IDE automatically picks up on the dependency based on her data reference (Figure 4).
Figure 4: Sharing data between Python and SQL cells.
Now that she has her aggregated data, Maggie wants to write the results to a table in her Snowflake warehouse that will eventually act as a source for her dashboard. Since she's just started this pipeline, she's not sure if this destination table exists yet, so she creates two SQL cells: one to make the table (if it doesn't exist) and one to populate it with her grouped DataFrame. Since there's no data dependency, Maggie manually declares a dependency between the cells to ensure the create-table cell runs before the insert (Figure 5).
Figure 5: A completed pipeline in the Cloud IDE.
Once she's done, Maggie can click the Commit button (Figure 6) to view her changes and commit them to a GitHub repository. She’s gone from idea to Airflow DAG in less than an hour.
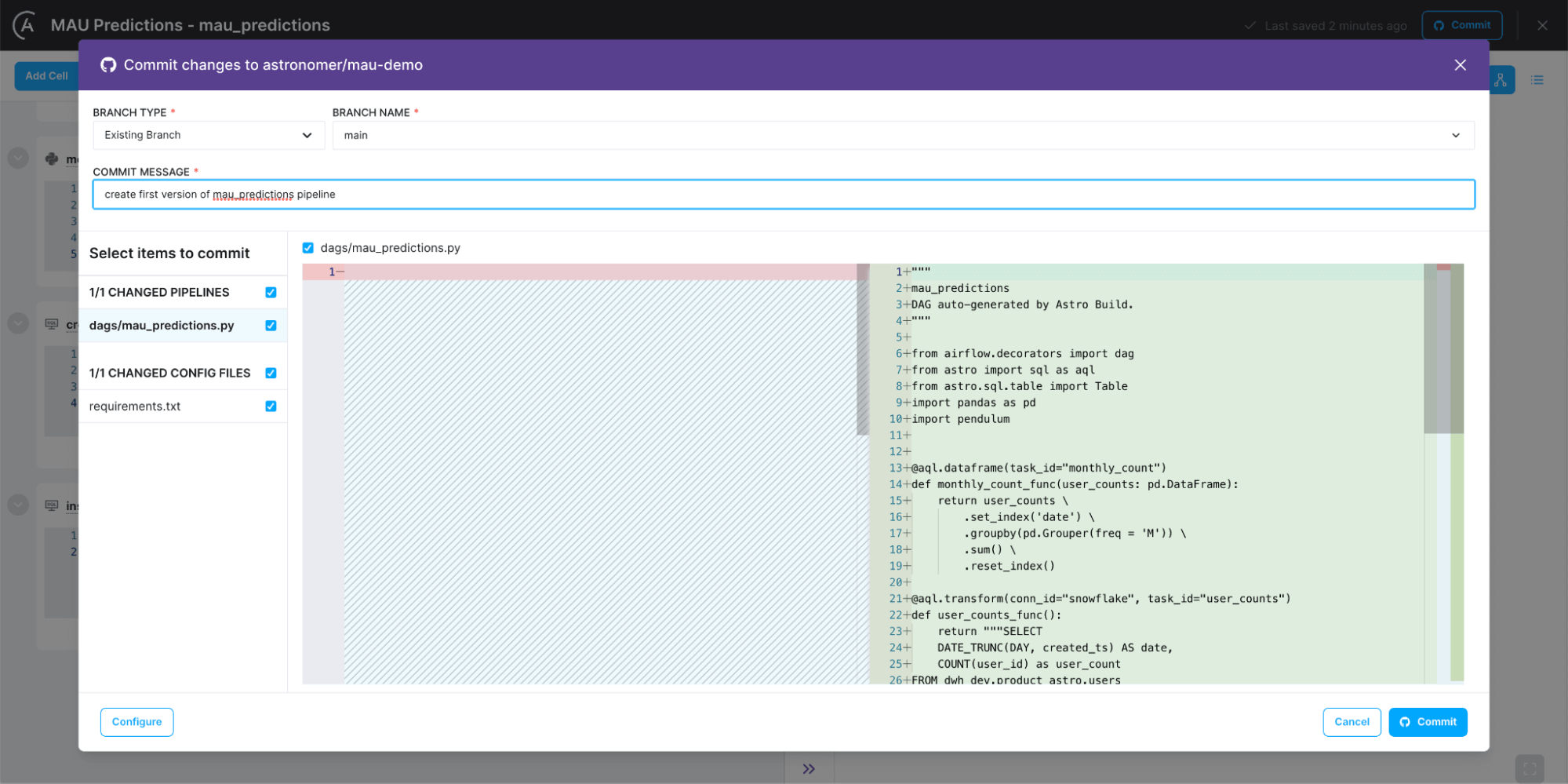
Figure 6: Committing a pipeline from the Cloud IDE to a GitHub repository as an Airflow dagfile.
For the Data Engineer: From Bottleneck to Enabler
Part of Sophia’s job as a data engineer on the data platform team is to ensure other teams have access to orchestration. The Astro Cloud IDE helps her with this initiative. She knows that Maggie, the data analyst, needs to write a transformation pipeline, so she sets up a project for Maggie, with a Snowflake connection and a GitHub repository connected. Check out our documentation for more details on how Sophia does this.
Maggie creates her pipeline, and when she’s done, she commits her changes to GitHub and creates a pull request. The Cloud IDE supports proper code promotion techniques by checking pipelines into source control as a method of deployment. This way, Sophia can review and merge the pull request when it’s ready, allowing the company’s usual continuous integration / continuous delivery (CI/CD) action to deploy the pipeline. If Sophia wants to set up a new deployment and repository for Maggie’s work, she can also do that very easily with the Cloud IDE’s recommended CI/CD configuration.
Now, all Sophia has to do is review and approve Maggie’s PR. From Sophia’s perspective, she’s reviewing a best-practice Airflow dagfile — exactly what she’s familiar with.
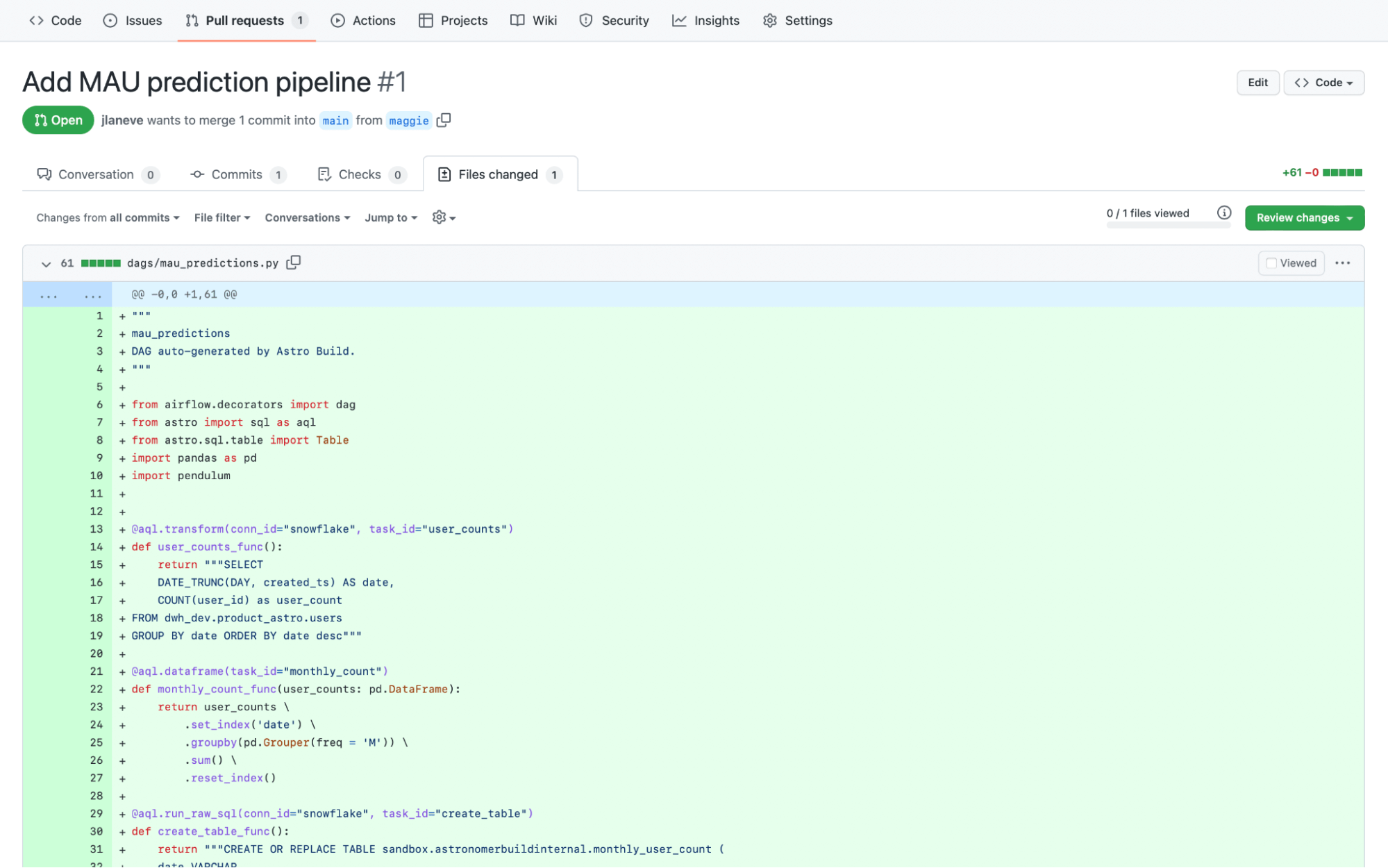
Figure 7: A sample pull request coming from a data analyst’s Cloud IDE pipeline. A data engineer can easily review and merge a request like this.
Coming Soon ... For the Data Platform Engineer: Enabling Functionality and Enforcing Best Practices
One of the most exciting features on the Astro Cloud IDE roadmap, set for release early next year, is the ability to create and manage custom cell types. The IDE currently supports Python, SQL, and Markdown cells, which go a long way toward providing easy access to orchestration. However, a large part of Airflow’s value comes from its robust ecosystem of operators, and users’ ability to extend those operators into custom use cases. In the Astronomer Registry alone, there are more than 1,000 operators that any Airflow user can import and use in their Airflow DAGs. Many organizations also develop Airflow operators and utilities that are internally published for use.
Here’s an example of how custom cell types can benefit a data platform engineer — let’s call him Otto. Otto works with a few data scientists who do their work in Databricks notebooks. These data scientists need to orchestrate their notebooks but don’t have much experience with Airflow. So, Otto has created an Airflow operator to run a Databricks notebook with some preset configurations around authentication, cluster configuration, etc. He’ll be able to register this operator as a custom cell type in the Cloud IDE, and it will be made available for immediate use.
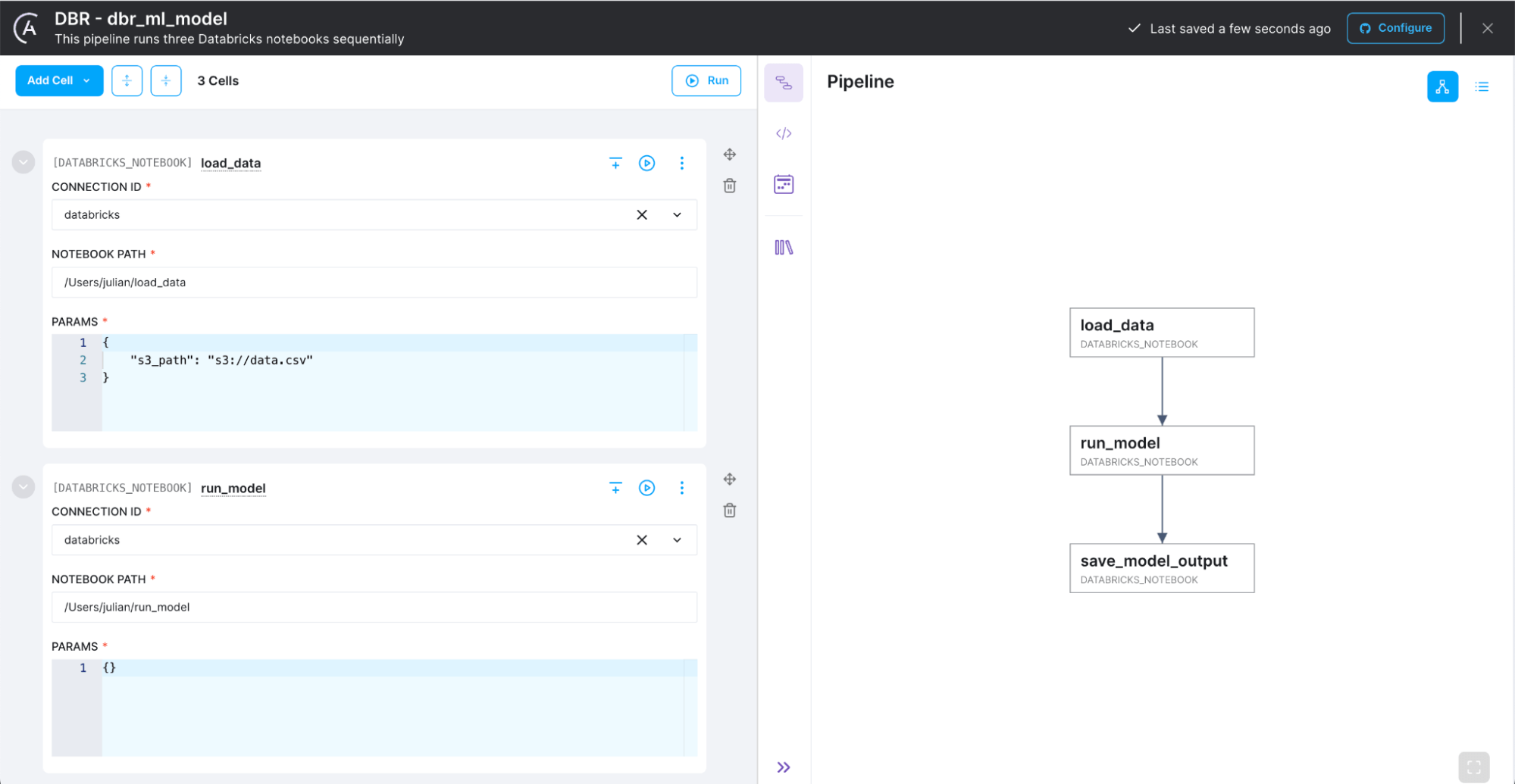
Figure 8: An early view of what custom cell types in the Cloud IDE look like.
These custom cell types also lay the groundwork for exposing more of Airflow’s functionality — it gives us a clear path toward supporting more Airflow operators as native cell types in the Cloud IDE. We’re still exploring this feature and the types of cells we can enable Cloud IDE users to create, so we welcome feedback.
How to Get Started With the Cloud IDE Today
The Astro Cloud IDE is available for all Astro customers. We’re going to continue iterating on the Cloud IDE to further improve the DAG authoring experience for practitioners across our customers’ data teams. You can find more information on how to use the Cloud IDE in our docs, or, if you’re looking to get started right away, check out our tutorial on Creating an ML Pipeline with the Cloud IDE. If you’re not yet an Astro user, get in contact with our team to schedule a demo.
