A Short History of DAG Writing
9 min read |
When Airflow was first open-sourced by Airbnb in 2015, it took the data engineering community by storm, quickly becoming one of the most viral, widely-adopted open-source projects in the world. At over 10 million pip installs a month, 28,000 Github stars, and approaching a Slack community of 30,000 users, it has become an integral part of data organizations around the world.
Airflow’s viral adoption wasn’t driven by millions in VC-funded marketing, a particularly sexy user interface, or a reputation for being easy to install and run. What accounted for much of Airflow’s initial popularity was its promise of pipelines-as-code. Expressing ETL as source-controllable code now seems like table-stakes for a workflow management system, but coming off an era that was dominated by large, vertically-integrated ETL providers and entering an era defined by cloud-native workflows and tight feedback loops, doing code-driven workflow management in an open-source language was actually quite a disruptive proposition. And the market responded appropriately; despite its early idiosyncrasies, Airflow got adopted everywhere.
Early adopters, including the initial beneficiaries of Airflow at Airbnb, weren’t working in the context of cloud data warehouses and didn’t have the luxury of standing up a greenfield stack; they were data engineers taming the entropy of the massively complex network of cron that was running critical data processes.
And developer interfaces in Airflow evolved accordingly, leading to several unintentional limitations. For example, because Airflow was initially designed to impose a task dependency layer on top of existing cron jobs, there was no first-class support for sharing data between tasks. Additionally, writing and testing code required understanding the Airflow domain-specific language, running Airflow on your laptop, and a basic understanding of docker, virtualization, and the Airflow service architecture. In other words, writing data pipelines required users to understand the ins-and-outs of Airflow.
The Expanding Scope of Data Practitioners
Learning Airflow is a reasonable ask for an advanced data engineering team, but the expanding definition of the data practitioner in the modern era has meant that workflow management is no longer the sole province of data engineering. The rise of the analytics engineer, the broadening scope and utility of data ingestion, and the increasing need to operationalize and orchestrate ML pipelines alongside other critical processes in an organization have all drawn different kinds of personas into the orchestration layer. All of them expect to be able to develop and deploy workflows using the interfaces and programming frameworks that are familiar to them — and not all of them are Airflow experts.
Take a team tasked by their C-suite with building analytics dashboards that show daily user growth on the organization’s ecommerce website, as well as predictive models that forecast that user growth over several months:
- A data engineer might focus on consistently extracting and cleansing raw data sets from an OLTP system to an OLAP system, priming operational data for analysis and data science.
- An analytics engineer might build a consistently-updated table and dashboard on MAU growth over the past several months based on that raw data.
- A data scientist might build and deploy a predictive model that leverages that transformed data to project how MAU growth will proceed over the next several months.
At a high level, this ends up looking like one big, stepwise process — a DAG, if you will — handling data ingestion (EL), transformation (T), and data science tasks.
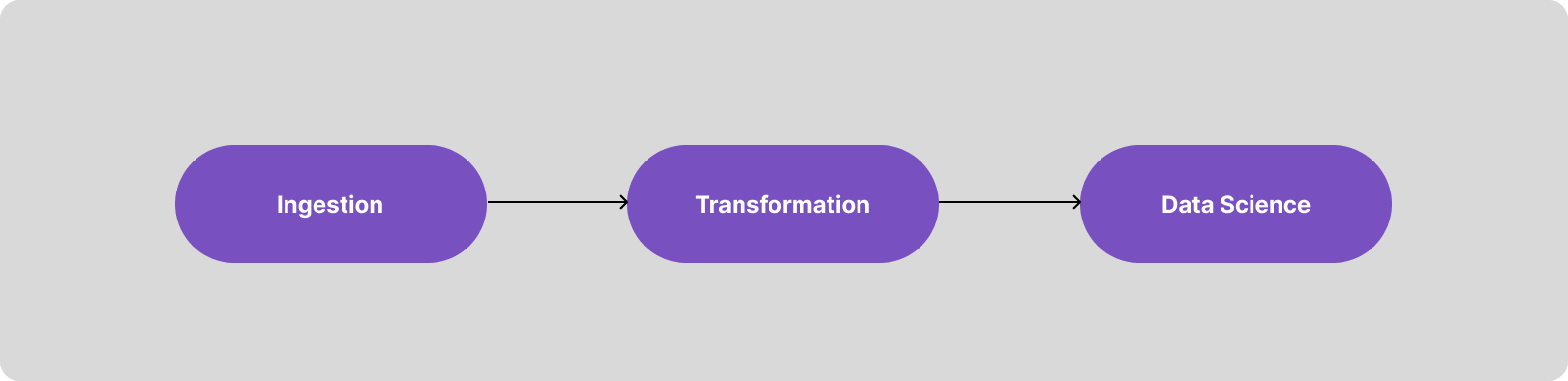
At ground level, though, where real-world teams build to solve specific problems, this pattern seldom materializes in such a simplistic way. Organizational boundaries, divergent scheduling requirements, and separation of ownership typically mean that each step of this big pipeline materializes as a separate “micropipeline”, each owned by an individual domain and dependent on a dataset produced by the upstream team.
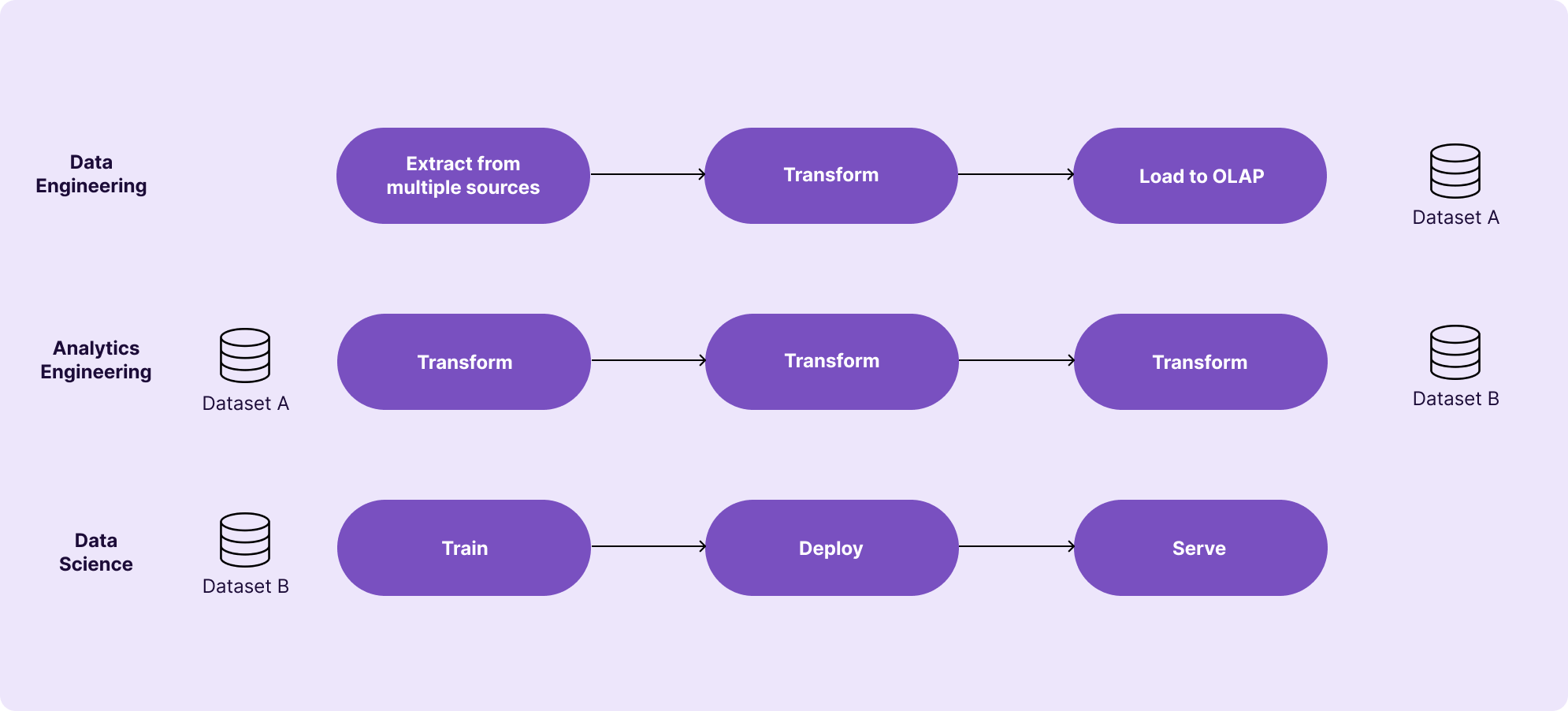
This division of ownership is generally good, because it allows for a decentralized mode of operation that enables teams to ship quickly – and Airflow now supports a native dataset object that makes it much easier to manage dependencies between decentralized teams!
But in companies we’ve worked with, we’ve noticed some challenges associated with this distribution of ownership. Perhaps the most significant is the challenge of authorship: each one of these personas comes to the orchestration layer with their own toolchains, skill sets, and workflows, but going from business logic — the actual functional code that makes up each node in the above graph — to an operational Airflow pipeline connecting all those nodes requires the user to understand both the fundamental principles of software engineering and the nuances of Airflow. This ends up being problematic, as it leaves the practitioner tasked with productionizing a pipeline with two subpar options:
- Learn Airflow. Learning the ins-and-outs of the Airflow Python library isn’t a challenge for a data engineer, but for an analytics engineer or data scientist, learning Airflow really means learning software engineering. It’s a lot to ask of a user who just wants to schedule some interdependent queries and functions!
- Get someone else to do it. Someone with competence in Airflow, typically from the data engineering team.
As you might expect, folks often end up choosing option 2. And as a result, we see bottlenecks developing in core data platform teams, wherein a core group of Airflow experts ends up spending more time productionizing other teams’ SQL queries and Python models than actually doing their day jobs.
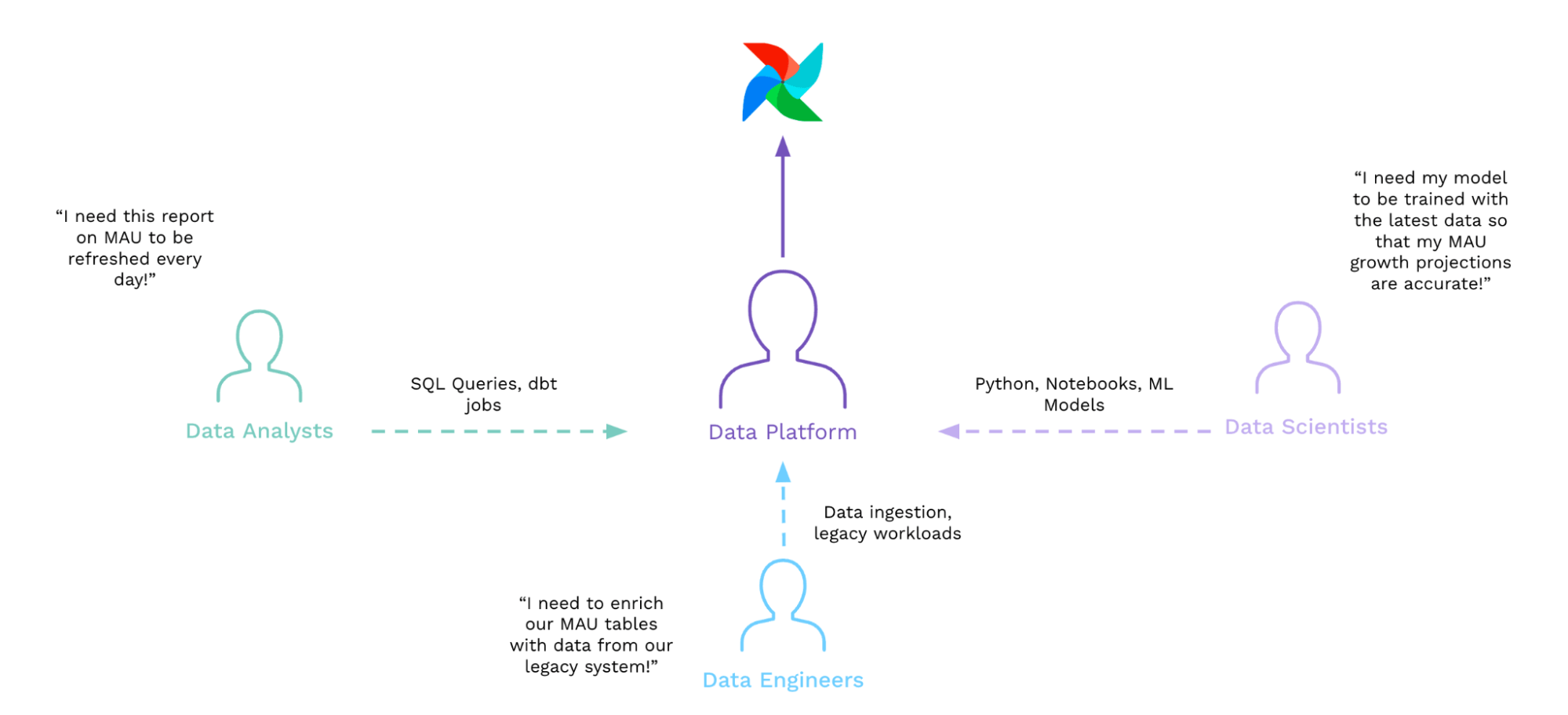
In these cases, talented data engineers — who signed up expecting to apply their software engineering knowledge and skills to wrangling the increasing entropy of their organization’s data universe — instead find themselves doing low-leverage, undifferentiated work. Modern use cases require Airflow to do things it wasn’t designed for, and data engineers end up paying a considerable price, as do the organizations that should be benefiting from their talents.
Evolving Interfaces
Both the Airflow community as a whole and we at Astronomer have been keen on solving this problem over the last few years. In fact, many open source projects have emerged from the community to support different use cases, all of which we’ve learned from in designing first-class support for modern workflows.
Taskflow API
First came the release of the Taskflow API in Airflow 2.0, which allowed users to natively define DAGs, tasks, and leverage XCom via a functional API. This meant that, rather than writing Python classes and explicitly declaring dependencies between them, users could simply define Python functions that natively share data, decorate them, and have the DAG implicitly derived from their references. This improved the interface for authoring DAGs and tasks significantly, and allowed users to define similar workflows with much less code than they needed prior:
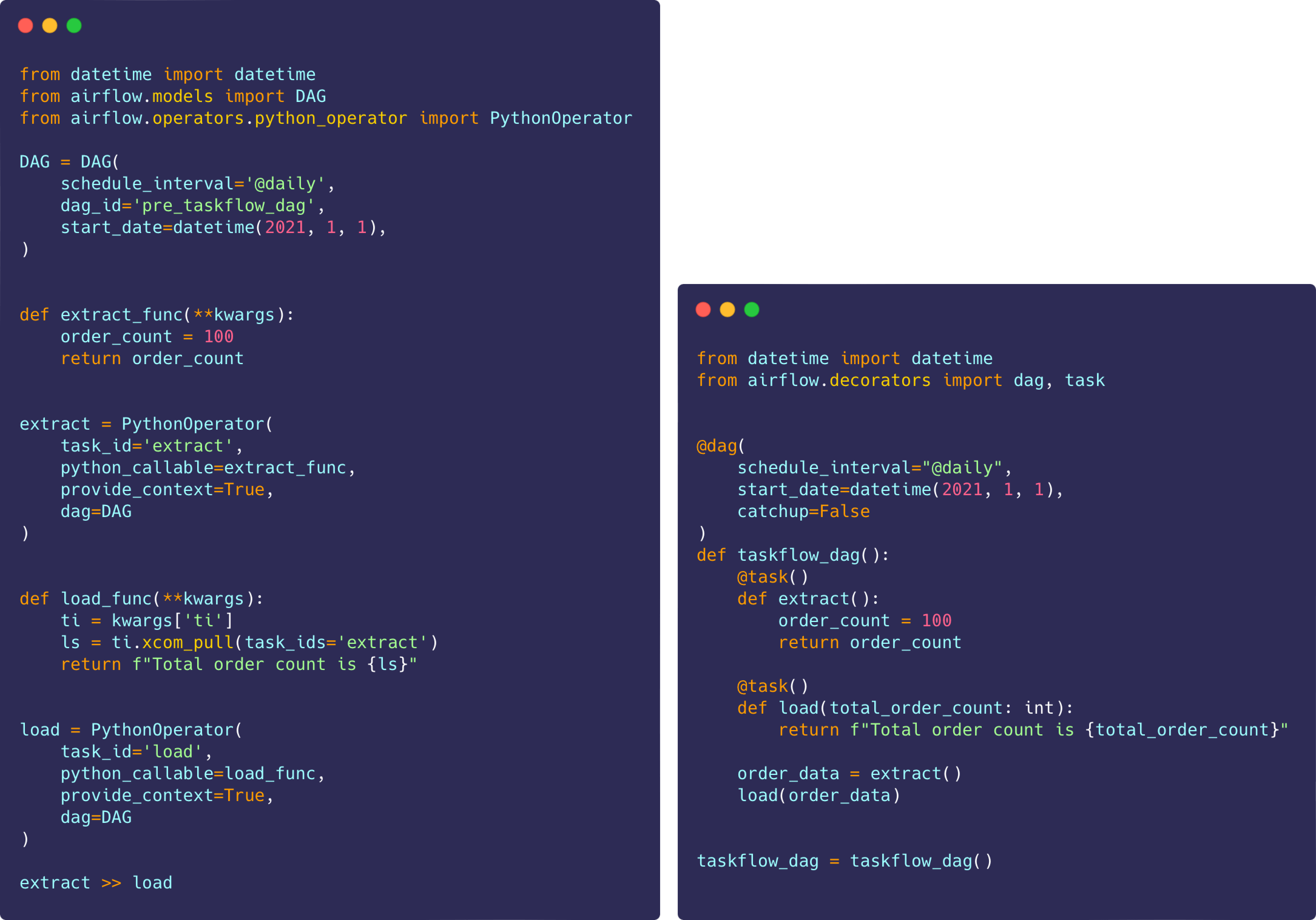
DAGs that express the same core logic without (left) and with (right) the Taskflow API.
The story around data-centric DAG authoring became even more powerful with the addition of Custom XCom Backends. Prior to Airflow 2.0 the only real medium for leveraging XCom as an intermediary data layer was the Postgres database sitting underneath the Airflow application. This worked great for simple messages, but wasn’t the best storage interface for larger data objects like Pandas Dataframes. So, to complement the Taskflow API, the Airflow community built and released Custom XCom Backends, which allow the user to bring any storage vehicle they’d like to handle the data being exchanged between tasks, including flat file storage like Amazon S3. A native API for declaratively writing DAGs paired with a pluggable storage layer created a very nice story around “data awareness” in Airflow.
Astro SDK
Airflow 2.0 brought a tremendous improvement to Pythonic workflows and set the foundation for data centric task orchestration. However, as we surveyed the ecosystem and took a look at what our own data team was doing, it became apparent that folks were still implementing one-off solutions to writing SQL-native DAGs and sharing data between SQL and Python. So our team at Astronomer built and launched the open-source Astro SDK to allow for both extremely straightforward SQL task definition and magic SQL>>Python interoperability.
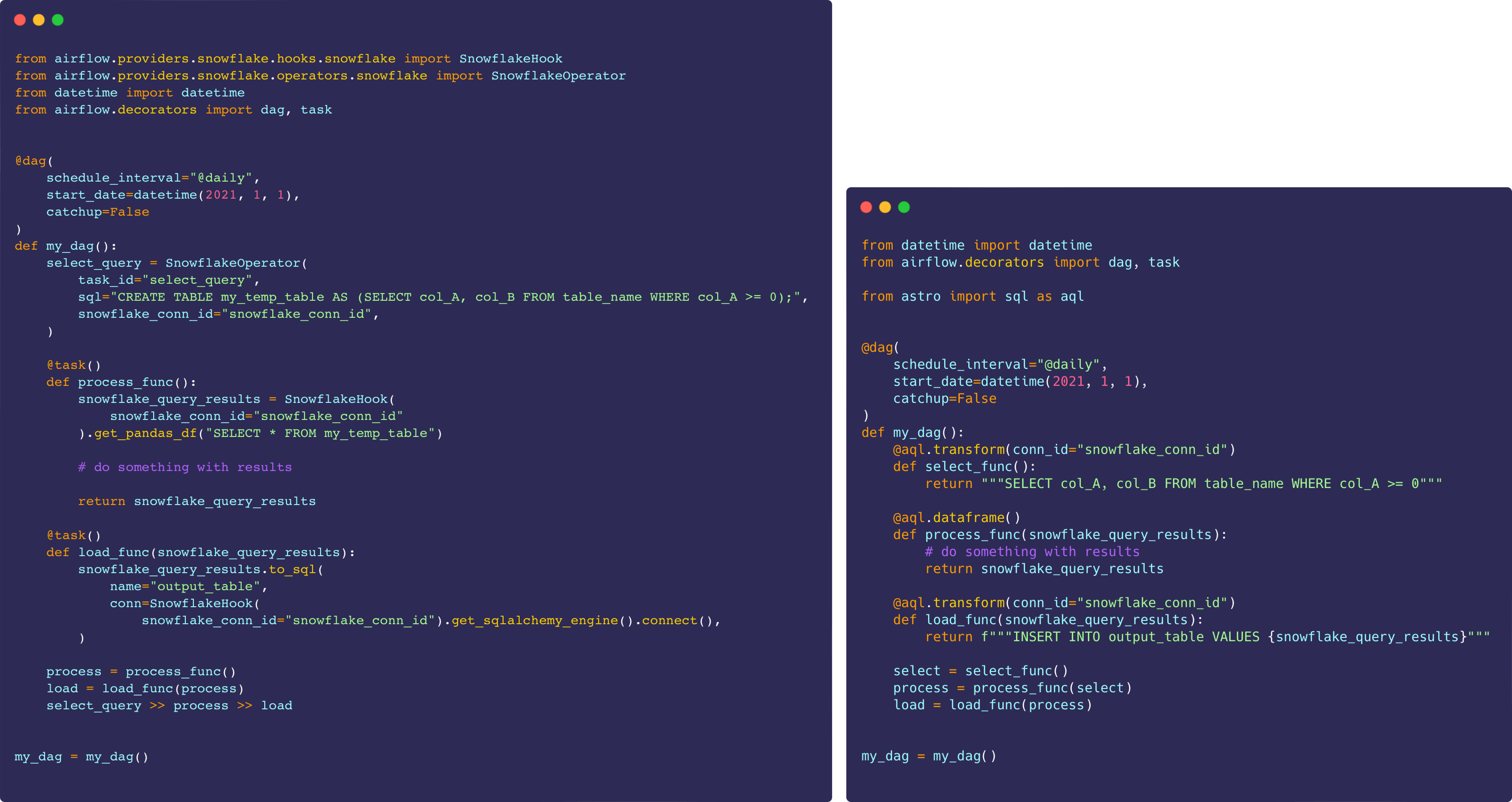
DAGs that express the same core logic without (left) and with (right) the Astro Python SDK.
Where we go from here with authoring
While the Taskflow API and Astro SDK have together made a quantum improvement to the Airflow DevEx, there are still areas that we’re eager to address, both in our contributions to Airflow and in the further development of Astro, our Airflow-powered orchestration platform. Namely:
- Tighter Feedback Loops: The local development feedback loop when running Airflow is still suboptimal — writing, running, and testing a DAG requires users to run Apache Airflow® locally, click through a webserver to run tasks, and parse unwieldy log files in a local UI when things go wrong. We believe this feedback loop should be tighter; we will soon be shipping a set of commands for the open-source Astro CLI that will enable users to run DAGs and tasks via simple commands and get helpful output in their terminals, all without running Airflow locally.
- Fewer Barriers to Entry: Doing Airflow still requires users to understand the basics of software engineering: To get anything running, you need to know some Airflow DSL, manage requirements, and be pretty good with Python. We think that users should be able to go from a simple Python function in a notebook, or SQL query in a worksheet, directly into a production orchestration system without understanding or writing a single line of orchestrator logic. With that in mind, we’re working on both a cloud-based IDE and a set of open-source CLI utilities that allow users to get the best pieces of Airflow while staying in a framework or interface of their choice.
- Simplified Environment Management: Managing credentials in the age of the cloud is a universal problem, but the nature of orchestration makes this problem more visible, since the DAG writing process requires users to move quickly between dev, stage, and prod environments, running code both from local and cloud machines. We believe there should be a secure way to write and test code against pre-configured environments, without having to worry about guarantees of consistency or tracking down those pesky Snowflake credentials you already added to your dev Airflow instance.
While we’ve come a long way, we feel like we’re just scratching the surface of what we can do to create a world-class developer experience for Airflow users. Stay tuned.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.