Watch the recording


Note: There is a newer version of this webinar available: Airflow 101: How to get started writing data pipelines with Apache Airflow®.
Welcome to the webinar on data orchestration with Apache Airflow®! Today, we’re going to walk you through the Airflow orchestration basics such as core components and elements of the Airflow UI, and then show you how to orchestrate your DAGs. Enjoy!
This presentation is going to focus on Airflow 2.
What is Apache Airflow®?
Apache Airflow® is a way to programmatically author, schedule, and monitor your data pipelines.
Apache Airflow® was created by Maxime Beauchemin while working at Airbnb as an open-source project in late 2014. It was brought into the Apache Software Foundation’s Incubator Program in March 2016 and saw growing success afterward. By January of 2019, Airflow was announced as a Top-Level Apache Project by the Foundation and is now considered the industry’s leading workflow orchestration solution.
Airflow is built on a set of core ideals that allow you to leverage the most popular open source workflow orchestrator on the market while maintaining enterprise-ready flexibility and reliability.
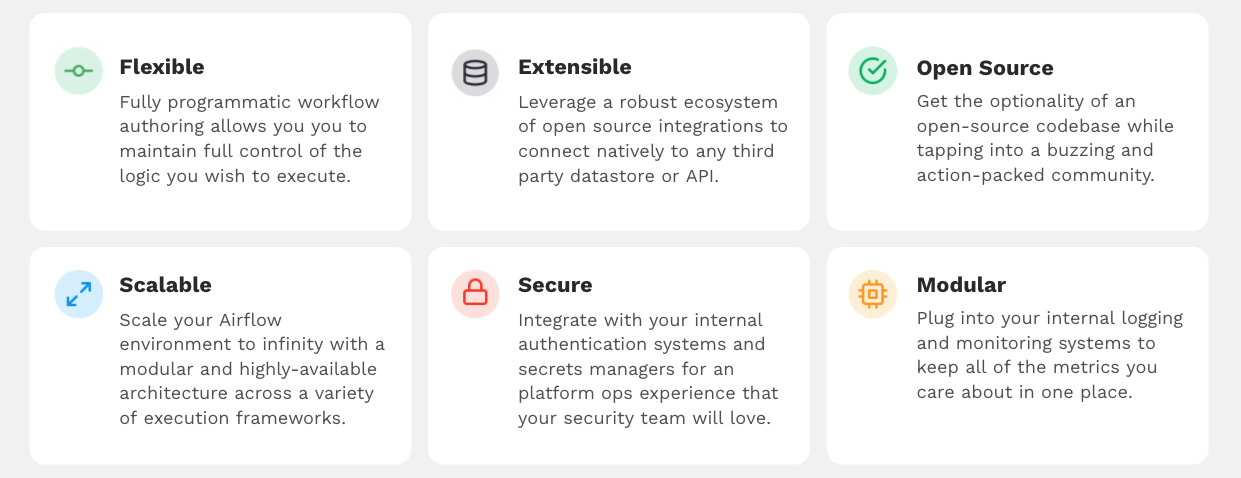
Flexibility All of your pipelines are defined as Python code, which means that anything that you can do with Python you can do with Airflow.
Extensibility, modularity Airflow comes with a robust open source community that has helped to develop a network of Airflow integrations with other tools.
Scalability Airflow is infinitely scalable, which comes in handy if it’s used as an enterprise-grade orchestrator.
Security Airflow allows you to integrate with your internal authentication systems and secrets managers for a platform ops experience.
If you want to learn more about the core components and concepts of Airflow,head over to our previous webinar where we dive deeper into all the basics.
Airflow UI
For a step-by-step guide on how to make Airflow run locally, check out our CLI Quickstart. Also, feel free to check out a webinar by Marc Lamberti on running Airflow with Helm Chart.
Let’s start with the basics. Once you have Airflow running this is what you would be looking at:
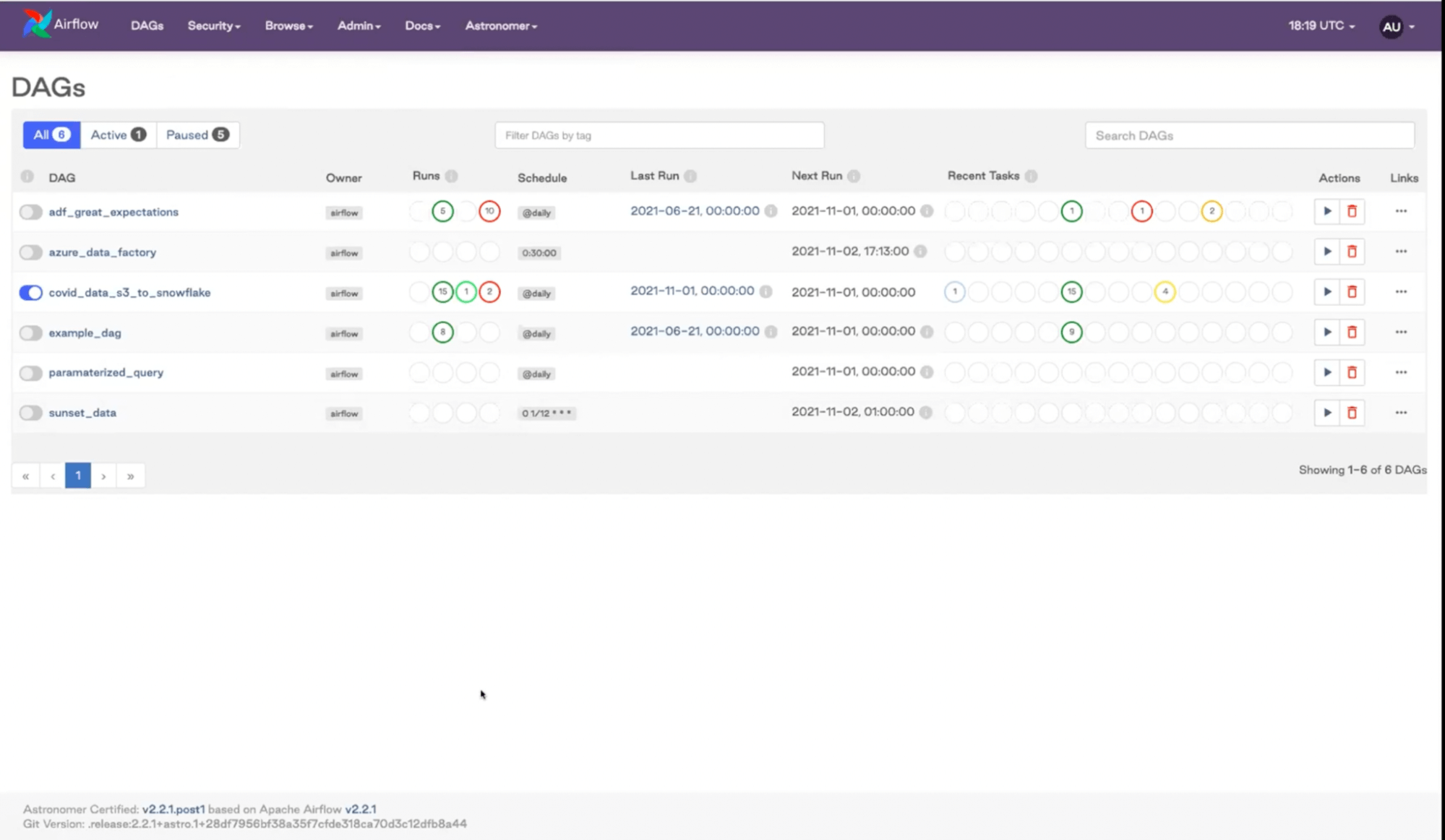
The home screen shows the DAGs. Remember to turn them on as it’s not done by default.
We’re using covid_data_s3_to_snowflake data as an example. Let’s go to the graph view.
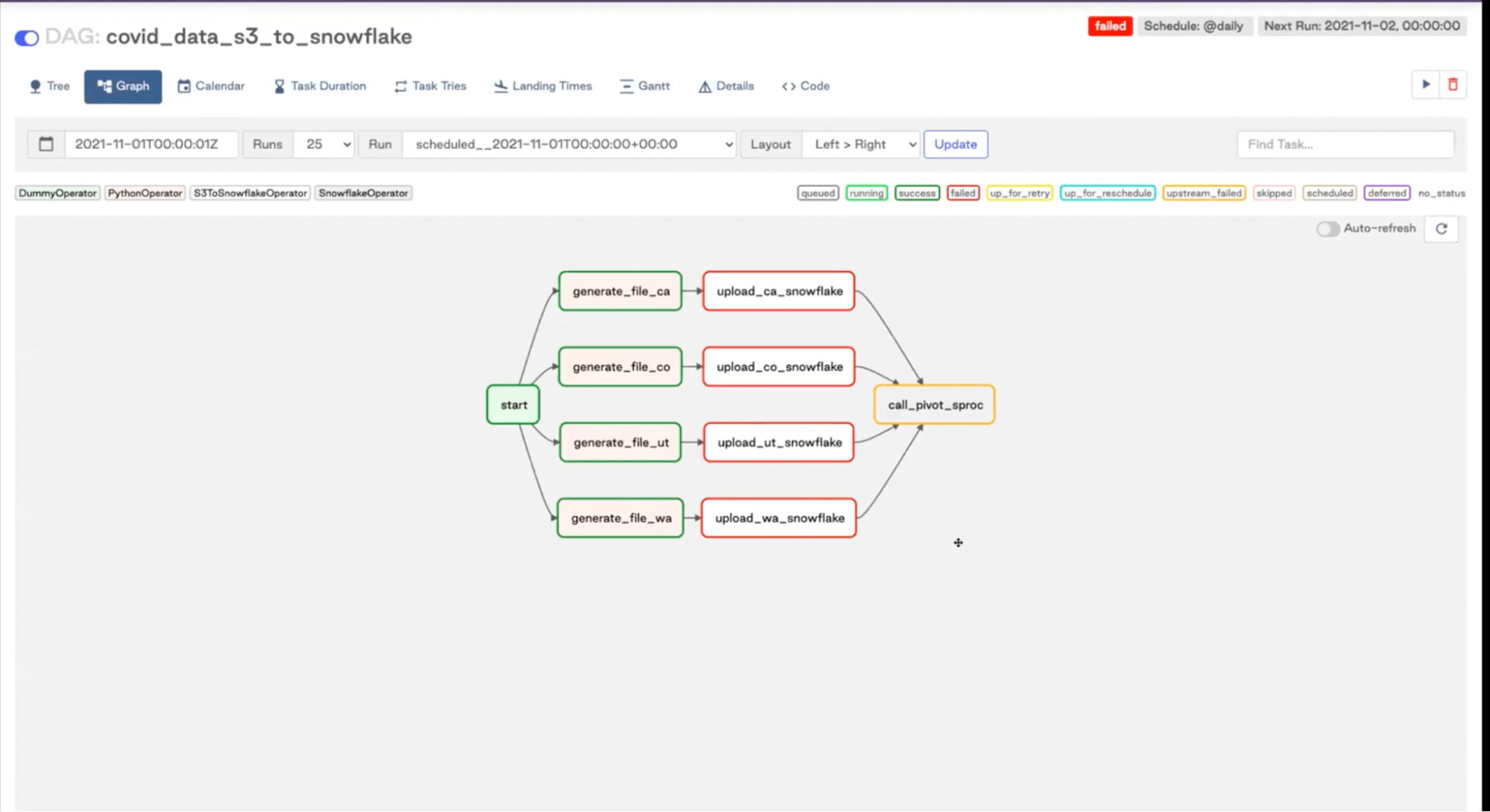
The graph view is especially helpful when developing DAGs—you can make sure that your DAGs dependencies are defined in the way you want them to.
The tree view shows you the status of your recent DAG runs.
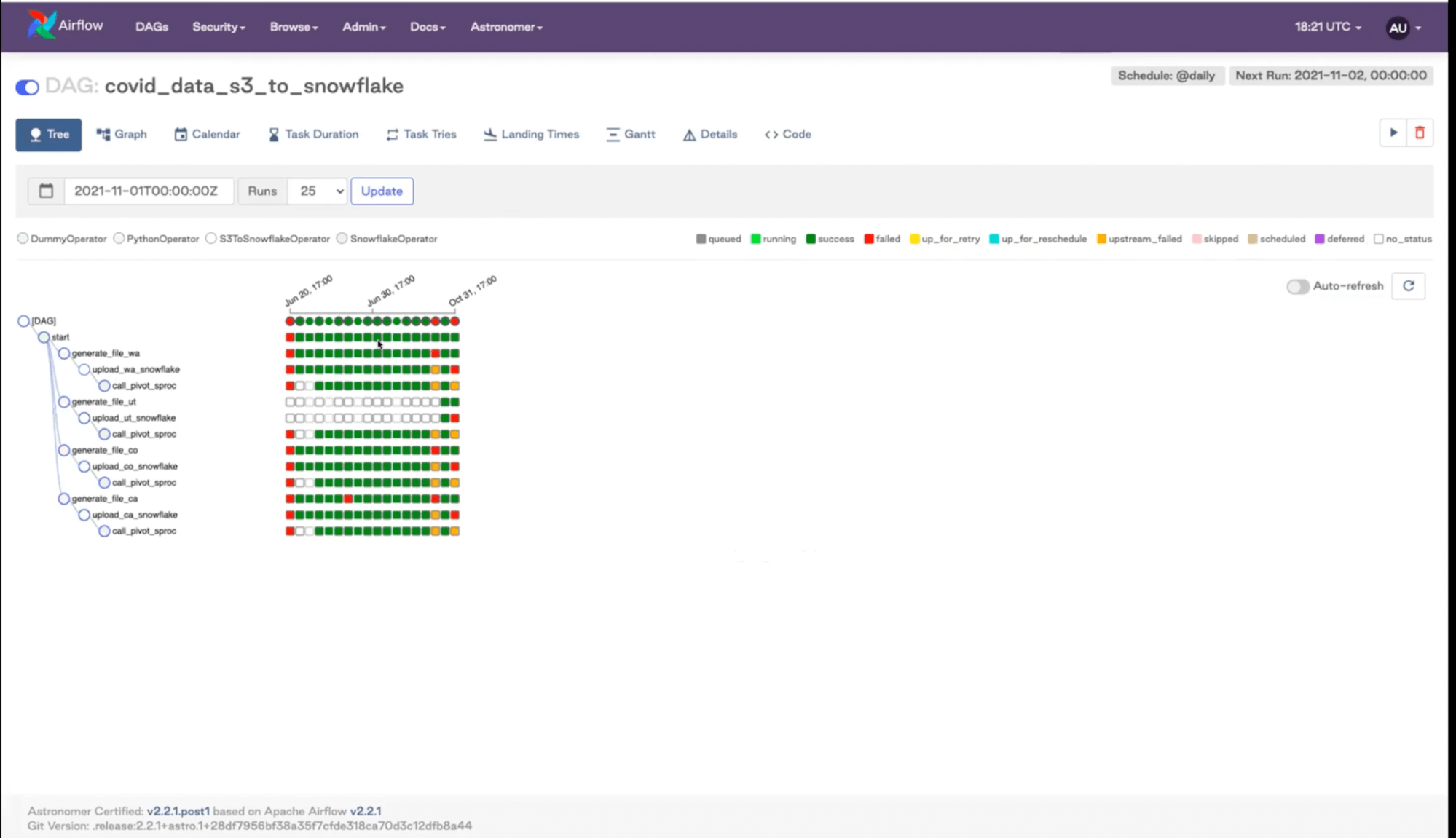
Looking at the Airflow UI is a great way to figure out what’s going on with your DAGs. If you get a notification that your DAG failed, you can look at the tree and investigate by clicking on an orange or red status.
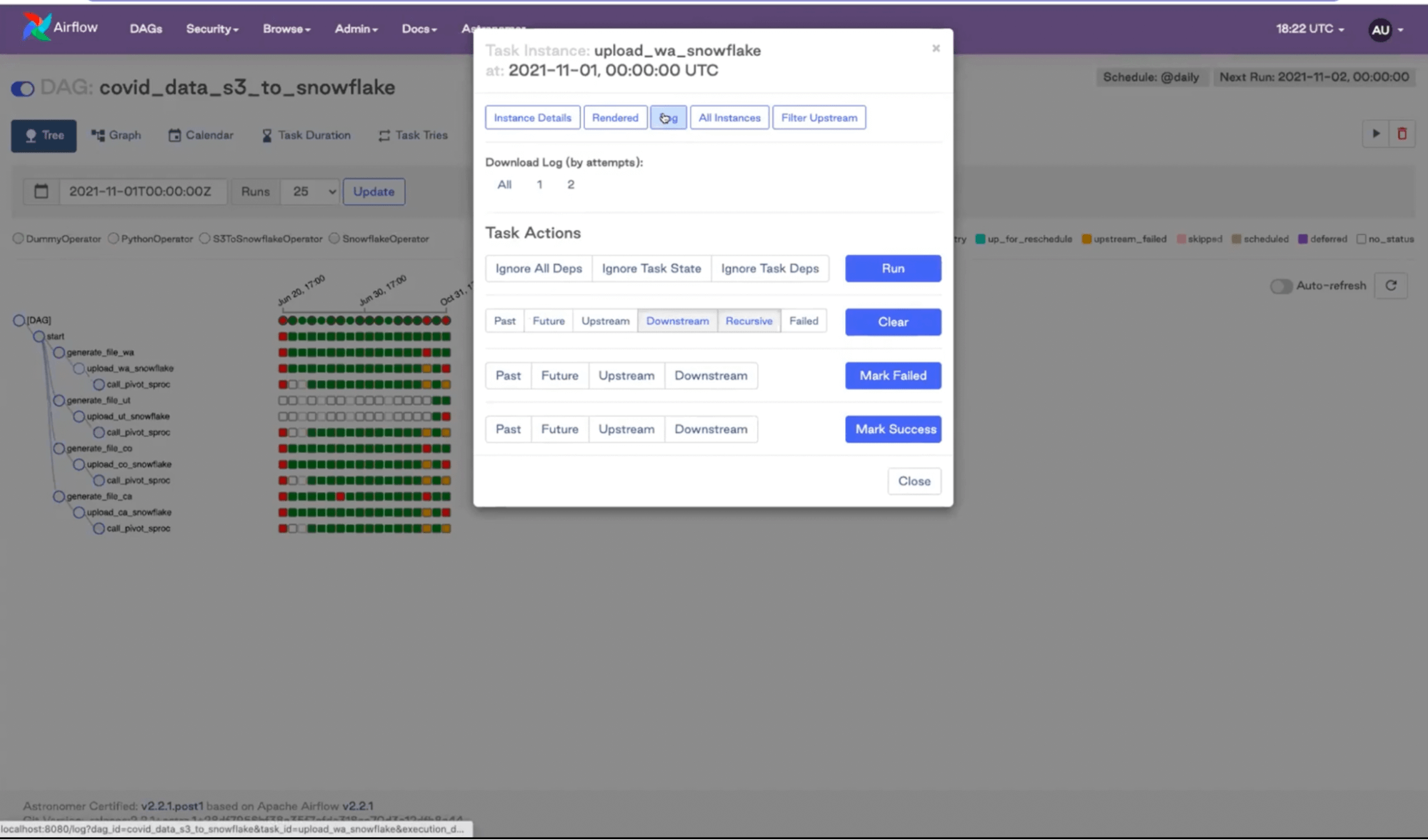
As you can see by looking at the graph view, we have some parallel tasks going on in our example:
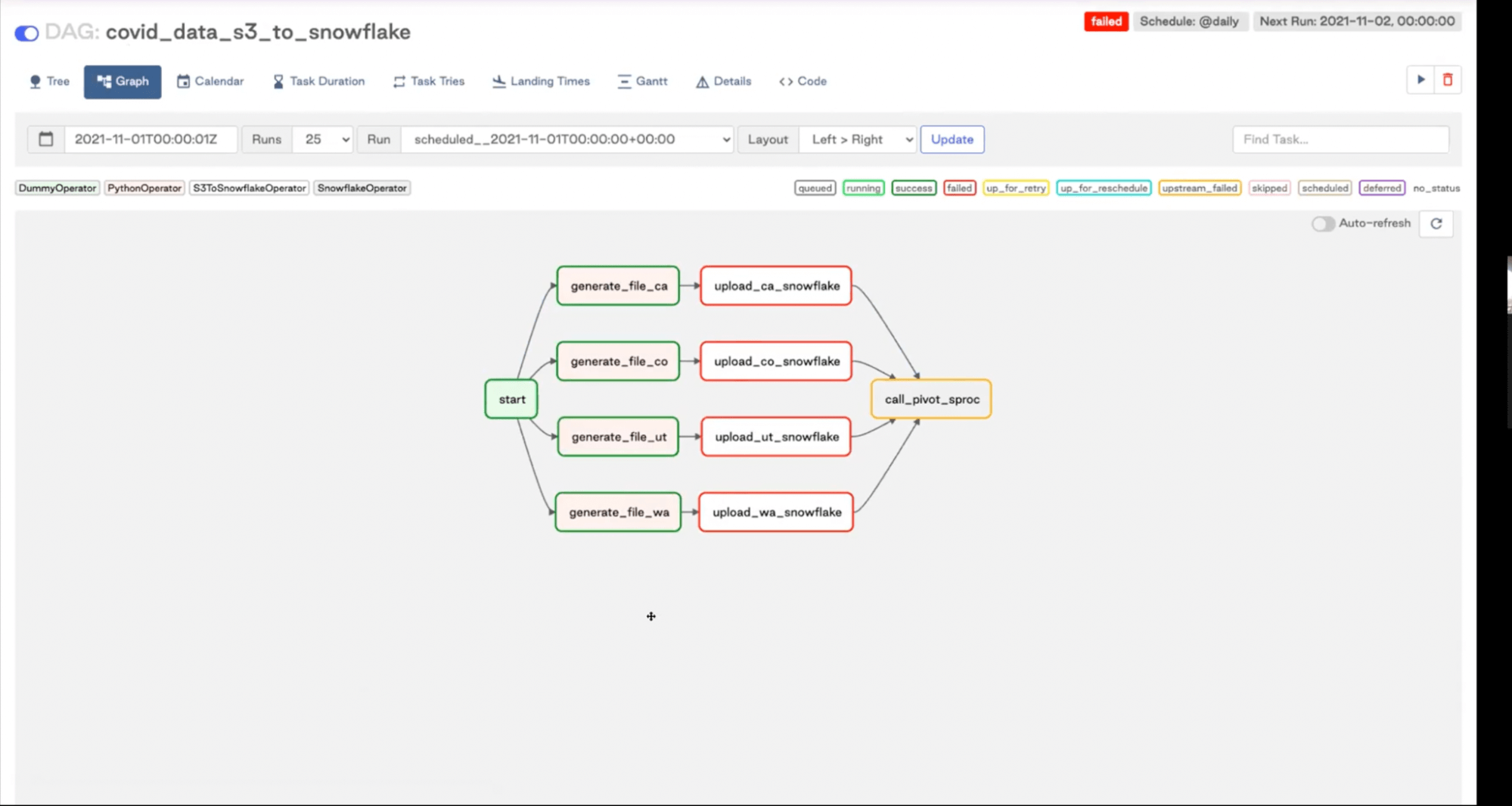
It’s a pretty basic ETL DAG, where we have a Python Operator, S3ToSnowflake Operator, and Snowflake Operator. We are grabbing data from an API endpoint, sticking that data into a table in Snowflake, and then calling the call_pivot_sproc procedure that’s doing some transformations for us.
Data Orchestration with Airflow
Let’s look at the code view:
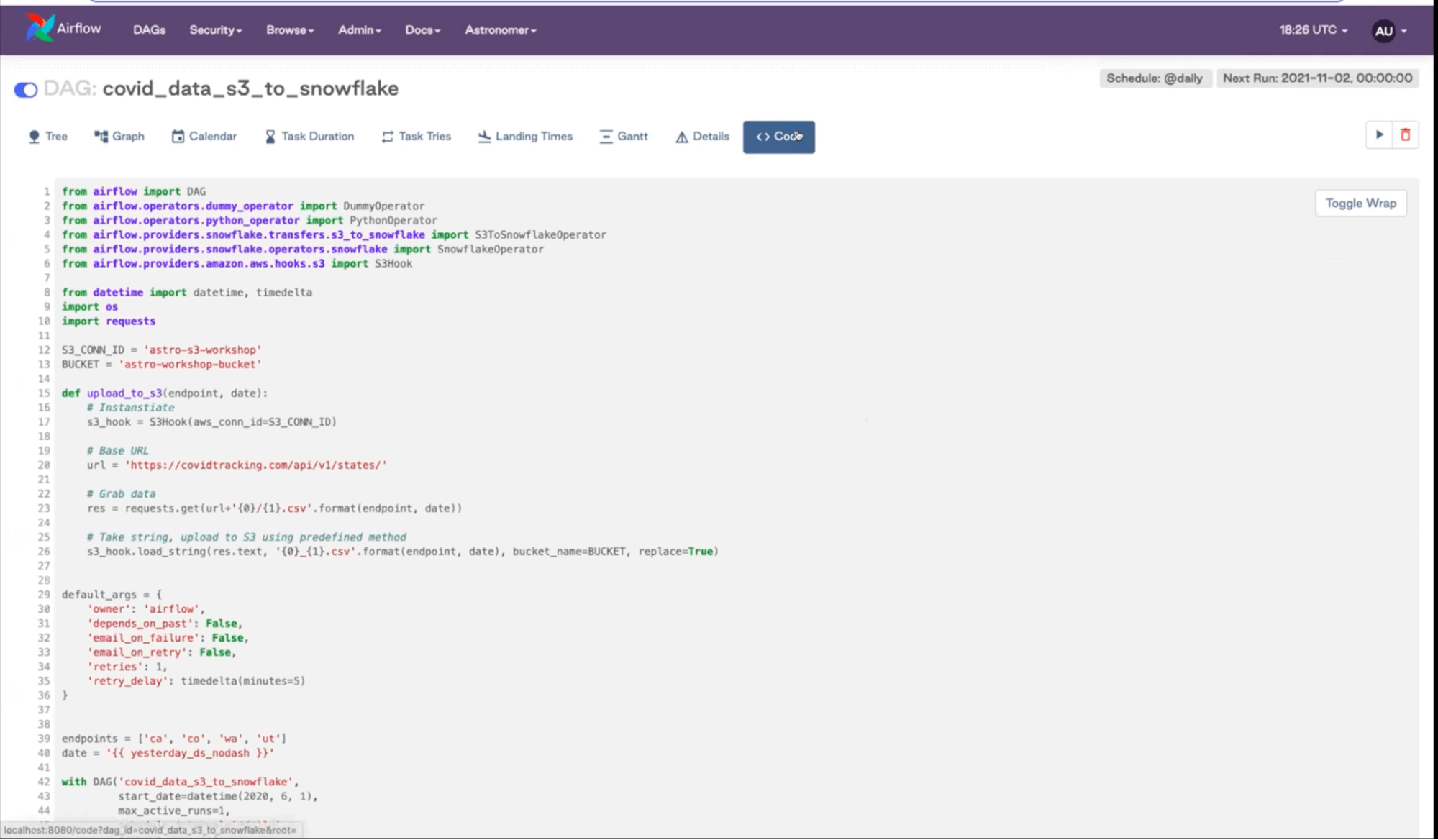
We can’t actually change the code here. The UI is helpful to see what the code should be or, if you don’t have access to the actual code, you can go in here and find out what’s going on in the DAG.
If you look at the top, mostly what we’re doing is importing Airflow functions and all of the Operators that we’re using. The Python Operator is built-in with open source Airflow, but the rest of them come from Providers (as they are separate from the Airflow core) that you have to install separately.
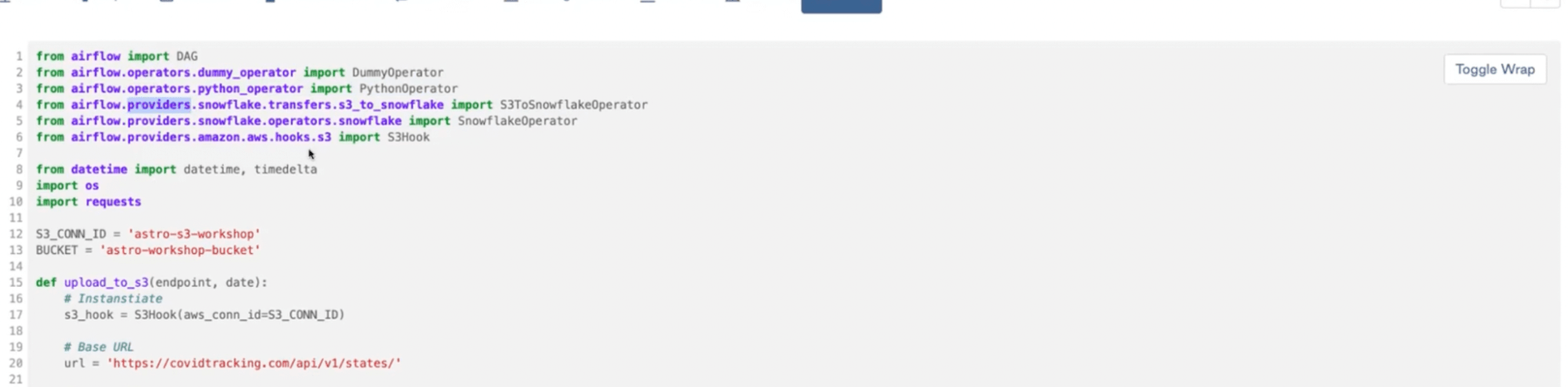
For our upload to S3, we’re defying this Python function (upload_to_s3):
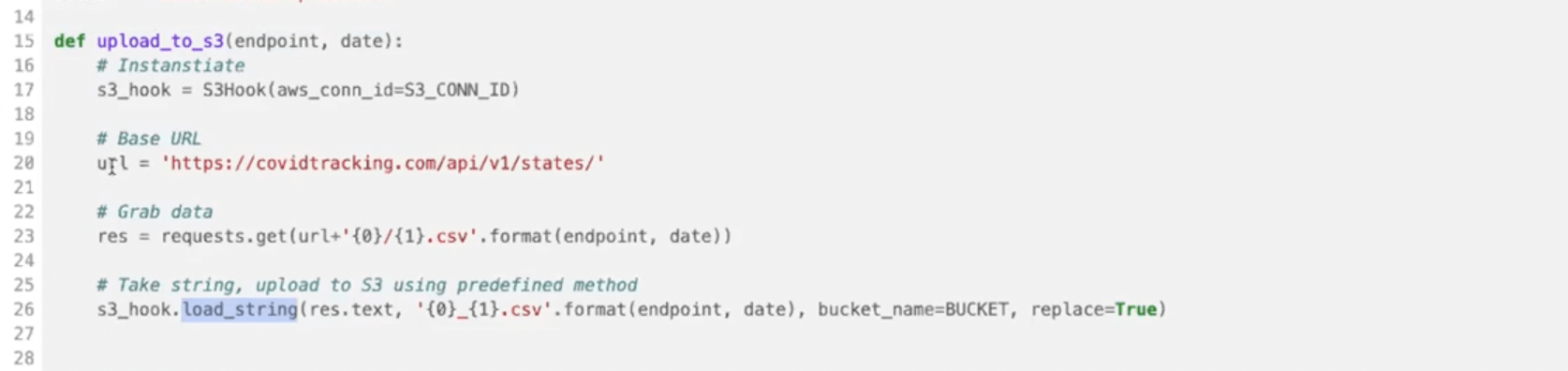
We’re also using a Hook. Hooks are a building block of Operators. They are an abstraction on an API that allows you to connect to another service.
Our Python function uses this S3 Hook to make a connection to our S3 bucket. It grabs data from an API endpoint and then sticks it into the flat file on S3.
Next, we can define any default arguments. These are the arguments we can use in all the tasks in our DAG.

The most important ones are:
email_on_failureemail_on_retry
Email notifications are probably the most basic option in Airflow—it will notify you when something is going wrong with your DAG.
Another important part is retries. Airflow by default is not going to retry any of our tasks—if they fail, they fail. If you want your tasks to retry when they fail you can define how many times you want to retry here:

Next, we define the DAG itself:
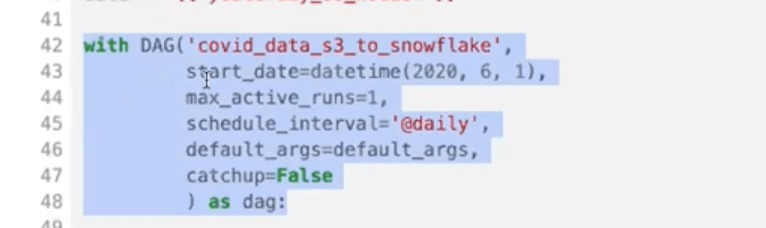
This is the most important part, that tells Airflow that this Python file sitting in your environment is actually a DAG.
You give it a name and a start date. The latter is essential because without the start date your DAG won’t be scheduled.
Another important thing to mention is catchup. By default, it’s set to True unless you override it. When it’s set to True, Airflow is going to run any DAG that would have been scheduled from the start date up until the current run.
Once the DAG is defined, you can define all of your Operators.
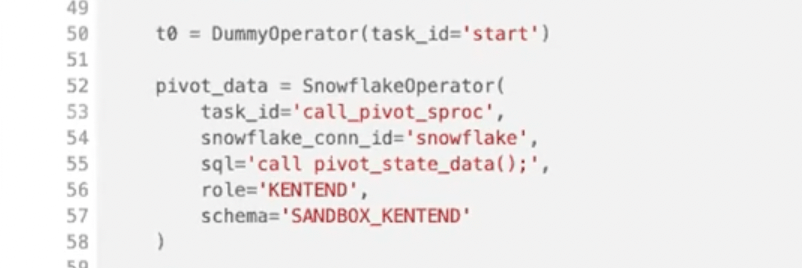
The other tasks (that run parallelly in our example) we’re actually creating dynamically within the DAG. Since you’re using Python, you have tons of options of how you define your DAGs.

Finally, you set up the dependencies:
For Hooks, Providers and Operators head to the Astronomer Registry.
That’s all! Thanks for joining us and see you next time.
Frequently Asked Questions
What is Airflow Orchestration?
Airflow orchestration refers to the process of managing, organizing, and scheduling complex workflows and data pipelines. It allows for the automation of tasks, ensuring they are executed in a specific sequence and under certain conditions, thereby streamlining and optimizing data processing and workflow management.
Is Airflow an ETL?
Airflow itself is not an ETL (Extract, Transform, Load) tool, but it is often used to manage ETL processes. It excels in scheduling, orchestrating, and monitoring the workflows involved in ETL, making it a powerful asset in handling data extraction, transformation, and loading tasks.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.