Watch the recording


Note: This webinar was recorded in November 2021 and Airflow is rapidly evolving with several new exciting features and best practices added since then. We recommend you also check out our up-to-date DAG writing best practices in Apache Airflow® guide.
Webinar links:
- Code examples from this webinar
Agenda:
- What is Apache Airflow®?
- Apache Airflow® core principles
- The core concept: DAGs
- 6+ more best practices
1. What is Apache Airflow®?
Apache Airflow® is a way to programmatically author, schedule, and monitor your data pipelines.
Apache Airflow® was created by Maxime Beauchemin while working at Airbnb as an open-source project in late 2014. It was brought into the Apache Software Foundation’s Incubator Program in March 2016 and saw growing success afterward. By January of 2019, Airflow was announced as a Top-Level Apache Project by the Foundation and is now considered the industry’s leading workflow orchestration solution.
- Proven core functionality for data pipelining
- An extensible framework
- It’s scalable
- A large, vibrant community
2. Apache Airflow® Core principles
Airflow is built on a set of core ideals that allow you to leverage the most popular open-source workflow orchestrator on the market while maintaining enterprise-ready flexibility and reliability. Obviously in Airflow, your pipelines are written as code, which means you're going to have the flexibility of Python behind you, and it was designed with scalability and extensibility in mind.

3. Core concept: DAGs
DAG stands for Directed, Acyclic Graph. It is your data pipeline in Airflow! The main rules: your DAGs flow in one direction and have no loops.
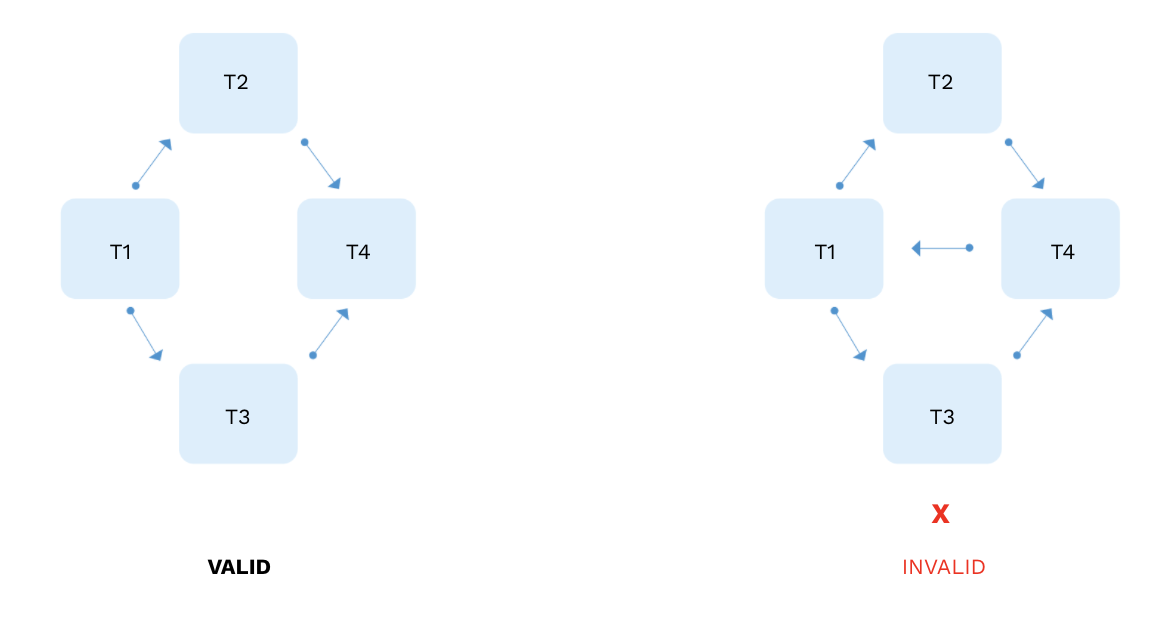
Don’t have infinite loops in your code!
4. Best practices
1. Idempotency
Idempotency is the property whereby an operation can be applied multiple times without changing the result.
This isn’t isn't actually specific to Airflow, but rather applies to all data pipelines. Idempotent DAGs help you recover faster if something breaks and prevent data loss down the road.
2. Use Airflow as an Orchestrator
Airflow was designed to be an orchestrator, not an execution framework.
In practice, this means:
- DO use Airflow Providers to orchestrate jobs with other tools
- DO offload heavy processing to execution frameworks (e.g. Spark)
- DO use an ELT framework wherever possible
- DO use intermediary data storage
- DON’T pull large datasets into a task and process with Pandas (it’s tempting, we know)
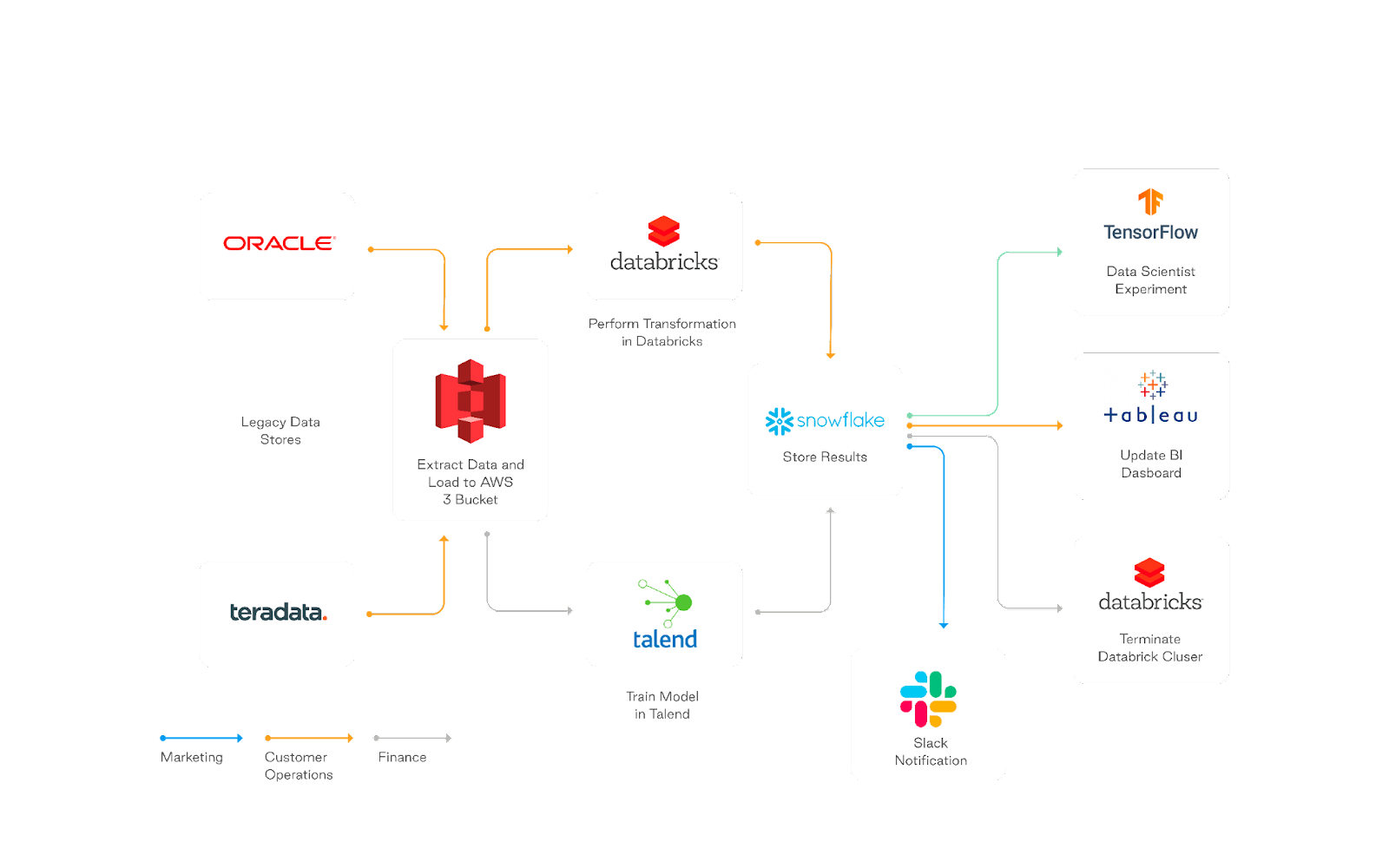
Airflow was designed to play with all these other tools!
Using Provider Packages allows you to orchestrate services with Airflow with very little code. That's one of the biggest benefits of Airflow.
Code example: One that does not implement the best practice of using airflow as an orchestrator and one that does.
3. DAG design: use Template Fields, Variables, and Macros
Making fields templatable, or using built-in Airflow variables and macros allows them to be set dynamically using environment variables with jinja templating.
This helps with:
- Idempotency
- Situations where you have to re-run portions of your DAG
- Maintainability
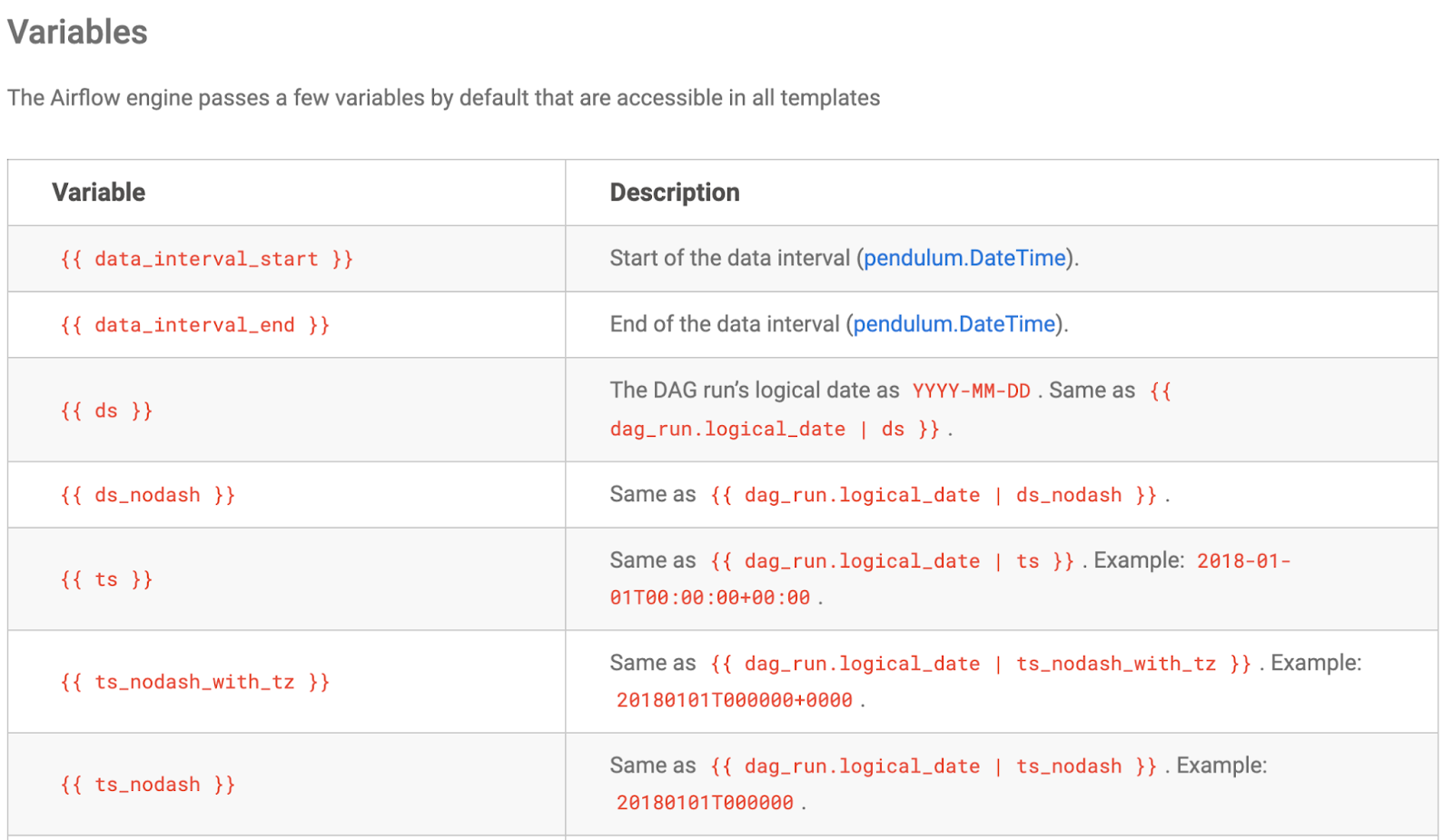
A great benefit of Airflow is that many commonly used variables are already built in.
Example of variables straight out of Astronomer registry, you can just reference them in your codes, not really any extra lift for you:
3. DAG design: keep your DAG files clean
Focus on readability and performance when creating your DAG files:
- Use a consistent project structure (Astronomer has one that we like to use internally that ships with our CLI, which is open source. You're always welcome to download that and take a look at that project structure, or you can create your own, but again, just using the same one is going to help everybody within your team and across teams within your organization know what's going on within an enterprise).
- Define one DAG per Python file (except for dynamic DAGs)
- Avoid top level code (anything that isn't part of your operator instantiations or DAG configuration that is actually going to get executed) in your DAG files. All code in your DAG file is going to get parsed by Airflow every time it runs. If you have code that takes a really long time to run within your DAG file, you can cause performance issues.
In general, remember all DAG code is parsed every min_file_process_interval.
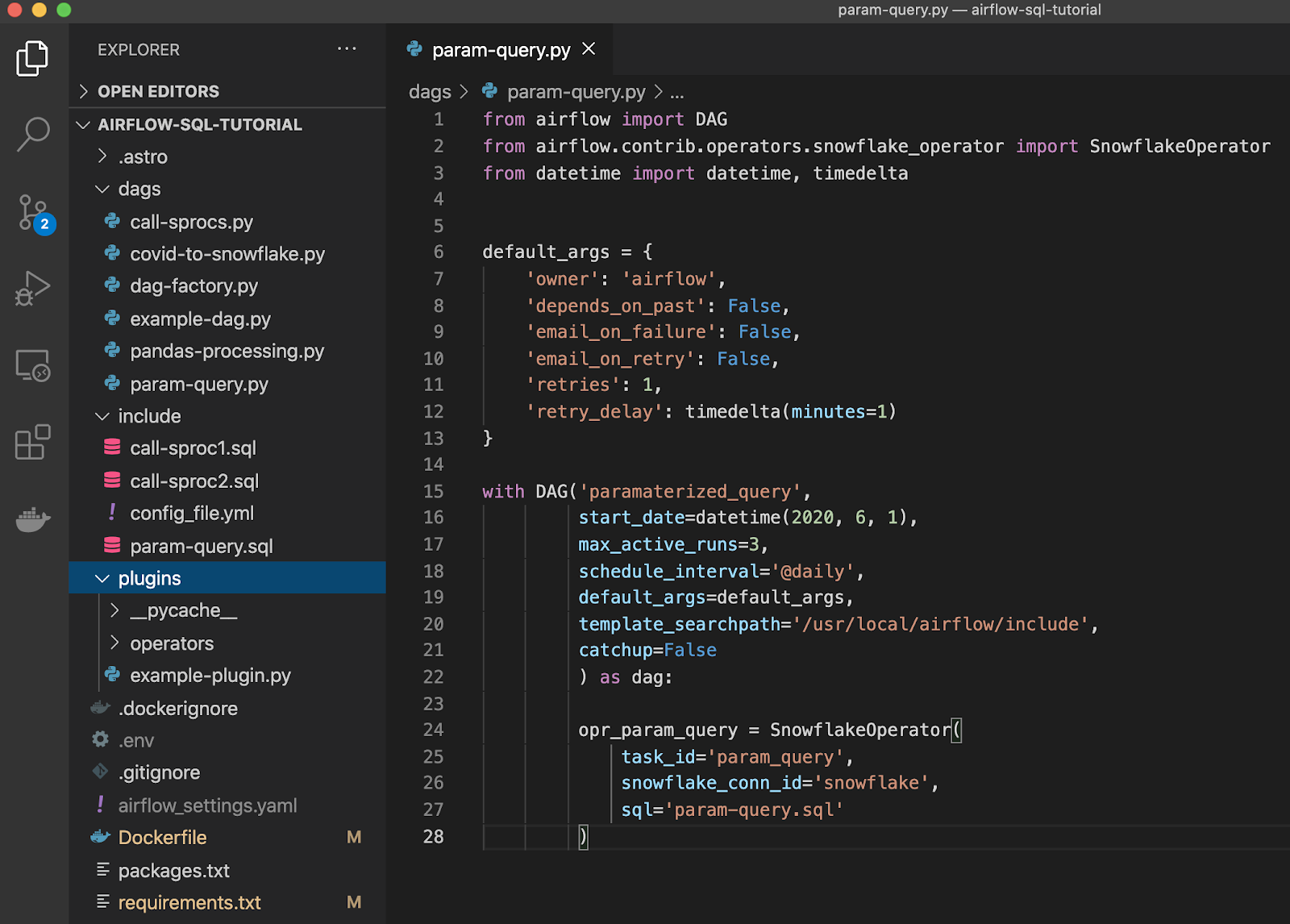
Code example: A couple of different queries for a set of States that get data for today's date. These are pulling COVID cases from a database, and I'm going to define and say, I wanted to do it for some certain number of States. Once all of the queries are completed successfully, we're going to send it.
5. Make Use of Airflow 2 Features
Airflow 2.0+ has many new features that help improve the DAG authoring experience

6. Other Best Practices
- Keep tasks atomic = make sure that kind of each task has one thing that it's designed to do.
- Use incremental record filtering
- Use a static start date
- Change the name of your DAG when you change the start date
- Choose a consistent method when setting task dependencies
Code example: a great example of where task groups come in handy.
For more check out this DAG Best practices written guide and watch the webinar to get some Q&A magic!

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.