Three ways to use Airflow with MotherDuck and DuckDB
8 min read |
With MotherDuck’s highly anticipated launch of a serverless, easy to use data analytics platform based on DuckDB, Data Engineers are eager to learn how to best integrate this robust and fast OLAP database into their Airflow environments. In this blog post, we will cover three key ways you can use DuckDB with Apache Airflow®, whether you are working locally or in the cloud. The code in this blog post can be found on the Astronomer Registry and in this GitHub repository.
Calling to MotherDuck from Airflow
Before we dive into best practice patterns on how DuckDB can be used with Airflow we want to answer the burning question for users flocking to MotherDuck: How do I switch from using local DuckDB instances in my Airflow tasks to go serverless?
Great news: connecting from Airflow to MotherDuck is as easy as connecting to a local DuckDB instance.
When using duckdb.connect() directly, just adjust your connection URI to point to MotherDuck and you are ready to go:
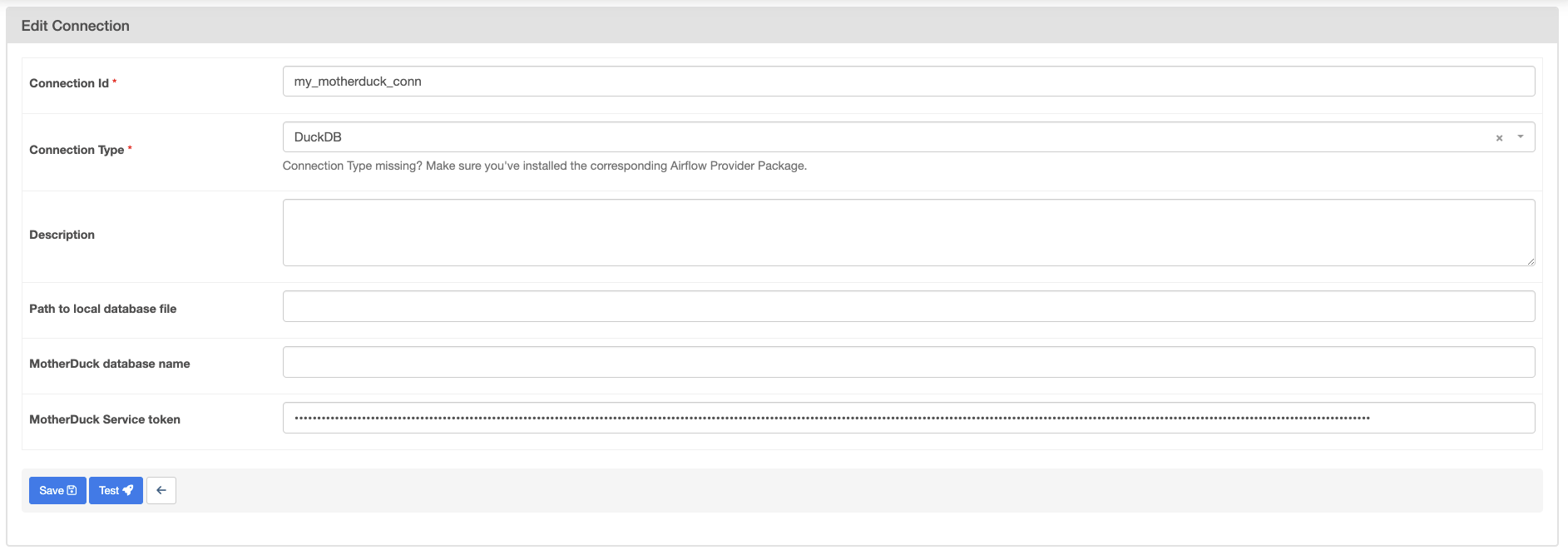
motherduck:{MY_MOTHERDUCK_DB}?token={MOTHERDUCK_TOKEN}If you are using an Airflow connection, simply add your MotherDuck token to the MotherDuck Service token field in the Airflow UI:
When to use DuckDB with Airflow
Much has been written on the benefits of DuckDB and why you should use it. But where does it fit into your Airflow pipelines? Generally, DuckDB can be a helpful addition to your DAGs if:
- You have data that you want to run complex, in-memory queries on.
- You are using the Astro Python SDK and want to store temporary tables in-memory.
- You are dealing with normal-sized data, specifically gigabytes, rather than petabytes, and you are conscious of costs.
- You want to leverage Hybrid Query Execution to efficiently JOIN data from local Python structures with your organization’s data in the cloud.
How to use DuckDB with Airflow
There are three main ways you can use DuckDB with Airflow:
- Use the duckdb Python package directly in @task decorated tasks. This method is useful if you want to do ad-hoc analysis in-memory or combine information stored in various DuckDB files.
- Connect to DuckDB via the DuckDB Airflow provider. The DuckDB Airflow provider is ideal if you connect to the same DuckDB database from many tasks in your Airflow environment and want to standardize this connection in a central place. You can also use the DuckDBHook to create custom operators to modularize your DuckDB interactions from within Airflow.
- Use DuckDB with the Astro Python SDK. The Astro Python SDK is an open-source package created by Astronomer to make interactions with relational data simple and tool-agnostic. The Astro Python SDK is the ideal tool if you want to easily connect to several database tools without changing any underlying code.
Use DuckDB with @task decorators
With the @task decorator, you can turn any Python function into an Airflow task, including functions that use the duckdb package to connect to a local or remote DuckDB database. To use this method you will need to install the DuckDB package in your Airflow environment. If you are using the Astro CLI you can do that by adding it to your requirements.txt file.
A common pattern when using the DuckDB package is to load data into an impromptu in-memory DuckDB instance, run a query, and pass the results of the query to your Airflow instance by returning it. This pattern allows you to run complex queries on a temporary database within a singular Airflow worker.
@task
def create_table_in_memory_db_1():
in_memory_duck_table_1 = duckdb.sql(
f"SELECT * FROM read_csv_auto('{CSV_PATH}', header=True);"
)
duck_species_count = duckdb.sql(
"SELECT count(*) FROM in_memory_duck_table_1;"
).fetchone()[0]
return duck_species_countOf course, you can also create a persistent local DuckDB database in a location accessible to Airflow, which can be useful when testing complex pipelines locally.
conn = duckdb.connect(local_duckdb_storage_path)To connect to MotherDuck, simply change the connection string and include your MotherDuck token:
conn = duckdb.connect(f"motherduck:{MY_MD_DB}?token={MOTHERDUCK_TOKEN}")Note: If you are using the Astro CLI to run Airflow and want to connect to MotherDuck, make sure that you are using the amd64 image to prevent package conflicts. You can force usage of the amd64 image by fetching: FROM --platform=linux/amd64 quay.io/astronomer/astro-runtime:8.4.0
By using the Python package directly in your @task decorated tasks, you can utilize the full capabilities of DuckDB.
In ML pipelines, DuckDB is often used to create a table from a pandas DataFrame returned by an upstream task. With pandas DataFrame serialization added in Airflow 2.6, passing data in this manner has been made possible with built-in XCom.
@task
def create_pandas_df():
ducks_in_my_garden_df = pd.DataFrame(
{"colors": ["blue", "red", "yellow"], "numbers": [2, 3, 4]}
)
return ducks_in_my_garden_df
@task
def create_table_from_pandas_df(ducks_in_my_garden_df):
conn = duckdb.connect(f"md:?token={MOTHERDUCK_TOKEN}")
conn.sql(
f"""CREATE TABLE IF NOT EXISTS ducks_garden AS
SELECT * FROM ducks_in_my_garden_df;"""
)
create_table_from_pandas_df(create_pandas_df())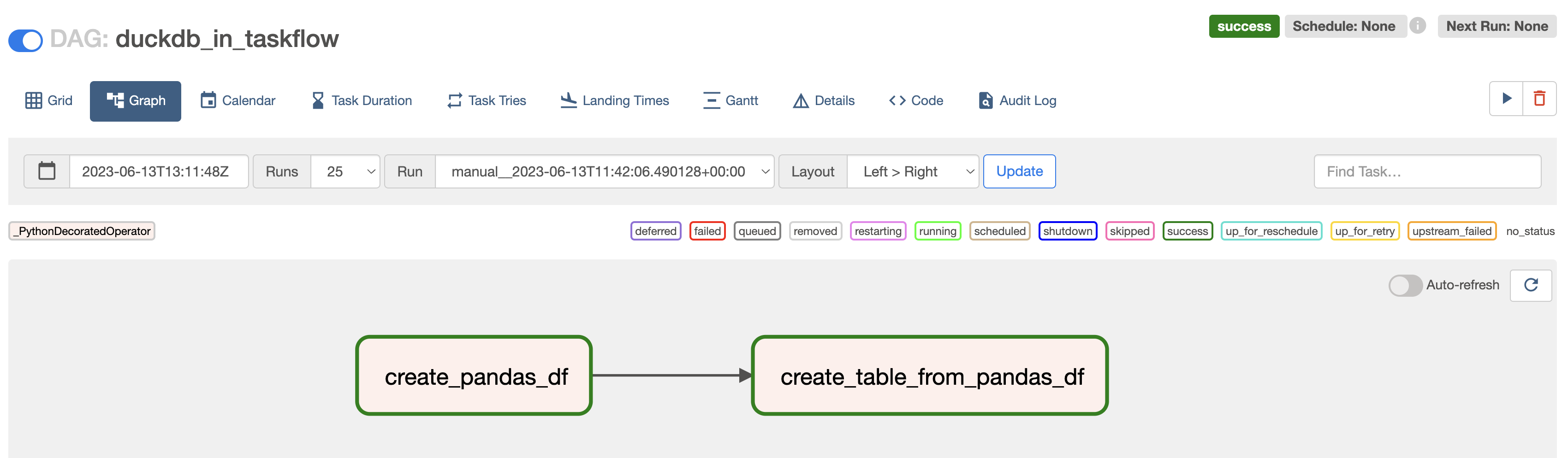
Figure 1: Graph view of a simple DAG creating a DuckDB table from a pandas DataFrame passed via XCom by an upstream task.
Of course, using the DuckDB Python package directly in your Airflow tasks allows you to leverage all popular DuckDB extensions such as:
- Reading data directly from S3 via HTTPFS.
- Directly parse JSON and transform the output to other file formats like parquet.
- Support for geospatial data processing.
- For a full list of extensions supported by MotherDuck see the MotherDuck documentation.
The DuckDBHook of the DuckDB Airflow provider
The Airflow provider for DuckDB allows you to use an Airflow connection to interact with DuckDB and even create your own operators using the DuckDBHook.
This pattern is especially useful when you are connecting to the same database from many Airflow tasks or if you want to provide your team with convenient ways to handle common tasks using DuckDB in a defined and standardized fashion.
To use the provider, you’ll need to install it in your Airflow environment.
pip install airflow-provider-duckdbSet a connection to DuckDB from the Airflow UI or via an environment variable.
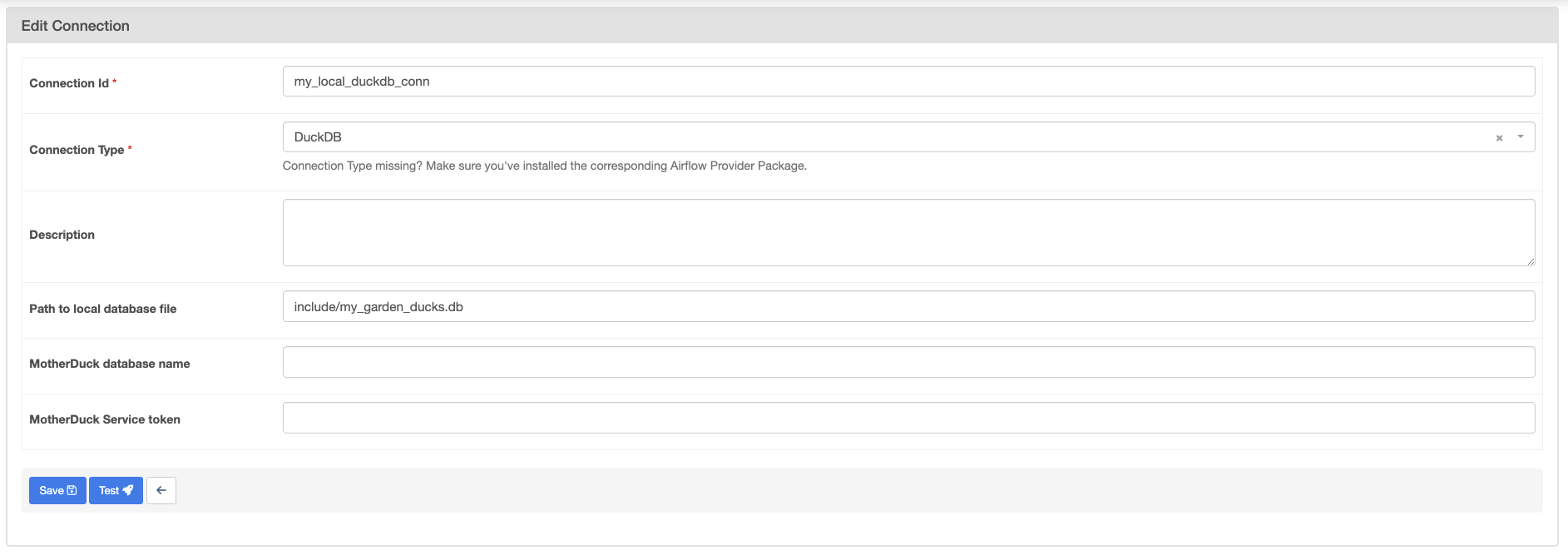
Figure 2: A DuckDB connection to a local database set in the Airflow UI.
For a connection to MotherDuck leave the Path to local database file field blank and provider your MotherDuck Service token and optionally a MotherDuck database name.
Now you can use this connection in any of your Airflow tasks by instantiating the DuckDBHook with it.
@task
def query_local_duckdb():
my_duck_hook = DuckDBHook.get_hook("my_duckdb_conn")
conn = my_duck_hook.get_conn()
r = conn.execute(f"SELECT * FROM persistent_duck_table;").fetchall()
return rNote: It is important to note that you cannot write to the same DuckDB database from two tasks at the same time. You can limit task concurrency by creating an Airflow pool and assigning all tasks interacting with a specific DuckDB database to this pool.
The DuckDBHook can also be used to create custom operators tailored to your team’s use cases. For example, if your team commonly needs to create new tables based on existing Excel sheets, you could create an ExcelToDuckDBOperator that can be instantiated with a few parameters in each DAG:
ExcelToDuckDBOperator(
task_id="excel_to_duckdb",
table_name="ducks_in_the_pond",
excel_path="include/ducks_in_the_pond.xlsx",
sheet_name="Sheet 1",
duckdb_conn_id="my_motherduck_conn",
)DuckDB and the Astro Python SDK
The Astro Python SDK is a next generation DAG authoring tool that allows you to write database agnostic code for any of its supported databases, including DuckDB!
The DAG below shows how you can use the Astro Python SDK to load a CSV file into a temporary table within DuckDB using an Airflow connection provided to the conn_id parameter. The DAG uses both the @aql.transform and @aql.dataframe operator of the Astro Python SDK to run transformations on the data, with the latter task storing its result in a new table called three_random_ducks. You can find the full DAG code here.
@aql.transform(pool="duckdb_pool")
def count_ducks(in_table):
return "SELECT count(*) FROM {{ in_table }}"
@aql.dataframe(pool="duckdb_pool")
def select_ducks(df: pd.DataFrame):
three_random_ducks = df.sample(n=3, replace=False)
print(three_random_ducks)
return three_random_ducks
@dag(start_date=datetime(2023, 6, 1), schedule=None, catchup=False)
def duckdb_and_astro_sdk_example():
load_ducks = aql.load_file(
File(CSV_PATH), output_table=Table(conn_id=DUCKDB_CONN_ID)
)
create_duckdb_pool >> load_ducks
count_ducks(load_ducks)
select_ducks(
load_ducks,
output_table=Table(
conn_id=DUCKDB_CONN_ID,
name="three_random_ducks"
),
)
duckdb_and_astro_sdk_example()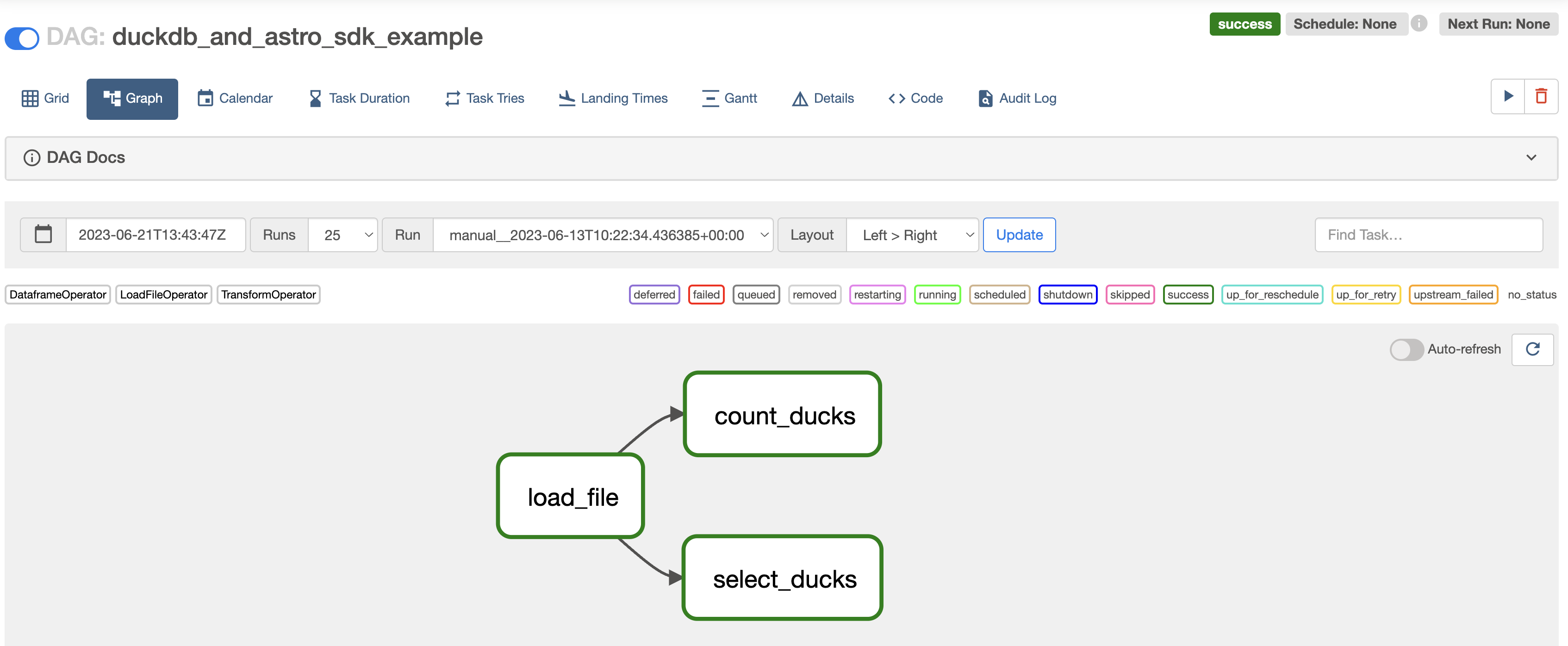
Figure 3: A simple DAG created with the Astro Python SDK using DuckDB.
The big advantage of the Astro SDK is that you could use the exact same code with a different conn_id in other parts of your Airflow application connecting to a different database; switching over to DuckDB becomes as easy as replacing one variable!
Conclusion
Airflow users have multiple options for integrating DuckDB into their DAGs for a variety of different use cases. If you’re new to either tool and want to play around with the integration which can be run in GitHub Codespaces with no local installations. The DAGs shown there use the Astro Python SDK method of using DuckDB with Airflow, but you can also modify the pipelines to try the other methods.
To get access to the MotherDuck Beta, head over to motherduck.com.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.