Machine Learning Pipeline: Everything You Need to Know
13 min read |
What Is a Machine Learning Pipeline?
Machine Learning pipelines are data pipelines that involve the execution of machine learning algorithms, typically for the training of predictive models. Machine learning (ML) engineers use ML pipelines to build models that learn from data to help answer questions in order to:
1. Provide an insight
The model is inferring patterns that can be used to drive business decisions. For example, the type of customers that buy a certain brand of T-shirt. However, in this case, the model is not part of the organization’s operational systems. These days data science teams place less emphasis on this one-time offline use of statistical models.
2. Provide a usable model that’s part of the company’s operational systems
The model can be used to directly drive business actions, e.g. to create a campaign that runs a prediction for a particular user to determine what gets shown on a company’s website. In this use case, a model is built into the business’s operations, added to the code that runs on the website, or made part of some backend business process.
Benefits of Machine Learning Pipelines
ML pipelines offer a structured and efficient way of building, evaluating, and deploying machine learning models. Here are some key benefits of using them:
Streamlined Data Processing: Machine learning pipelines automate the process of data transformation and preprocessing. This includes tasks like normalization, encoding categorical variables, and handling missing values. By automating these steps, pipelines ensure that data is consistently processed, reducing the risk of errors that can occur when these tasks are performed manually.
Reproducibility and Consistency: Pipelines help in maintaining consistency and reproducibility in machine learning projects. Since each step of the model building process is defined and linked, it becomes easier to reproduce results and track changes over time. This is particularly important in collaborative environments where multiple data scientists are working on the same project.
Efficient Model Evaluation and Selection: Pipelines facilitate the comparison of different models and their parameters through a consistent framework. By using pipelines, data scientists can easily swap out different algorithms and compare their performance on a standardized dataset, leading to more informed and effective model selection.
Time and Resource Efficiency: Automating the workflow with pipelines saves time and resources. It reduces the need for repetitive coding and allows data scientists to focus on more complex aspects of the model development process, such as feature engineering and hyperparameter tuning.
Error Reduction: By standardizing the steps in the machine learning process, pipelines reduce the likelihood of errors. This is particularly important in data preprocessing and feature engineering, where mistakes can significantly impact the performance of the model.
Ease of Deployment: Machine learning pipelines simplify the process of deploying models into production. They allow for the entire process, from data preprocessing to prediction, to be encapsulated in a single, deployable object. This makes it easier to integrate the model with existing production systems.
Scalability: Pipelines are designed to handle large volumes of data and can be scaled up or down depending on the requirements of the project. This scalability is essential in handling real-world data and ensuring that models remain effective as data volumes grow.
Enhanced Collaboration and Communication: Pipelines provide a clear framework for the machine learning process, which enhances communication among team members. They offer a common language that both technical and non-technical stakeholders can understand, facilitating better collaboration and decision-making.
What Are the Steps of a Machine Learning Pipeline?
Generally, when talking about creating a machine learning pipeline, engineers mention six steps:
- Data sourcing - Getting raw data through ETL processes from the source: a warehouse , website logs, financial transactional systems, IoT system, etc.
- Cleaning - Preparing data for model training.
- Feature generation - Creating features, for example an average number of transactions in the last year, gender of customers, etc.
- Model training - Building a model using the created features.
- Model testing - Testing to make sure that the accuracy meets some sort of threshold. For example, if the accuracy is 80%, or 95%, or—if you already have a model in production—if the new one is better.
- Model deployment - Saving a model as a file or pushing it directly into production.
Often, data science teams use feature stores. A feature store is a centralized location where data engineers deliver the features to and where ML models pick up the features from. Data scientists and engineers might use a first pipeline for sourcing, cleansing, and creating features, and then data scientists together with machine learning engineers use a second pipeline for training, testing, and deployment. Technically, you’re working on the same end-to-end pipeline, but you’re splitting your workflow into two areas of concern.
What to Consider When Building a Machine Learning Pipeline?
Machine learning is a complicated process that traditionally has been done as part of one continuous effort by data science teams. However, feature stores provide a convenient abstraction that helps standardize and optimize the variables used by analysts and data scientists. So data engineers can focus on creating a data warehouse from the raw data; data engineers and scientists can work together to create the feature store; data scientists and ML engineers can build the models, and MLOps engineers can focus on testing, monitoring, and deploying of models. You allow for a clearer overview of the entire ML pipeline, greater re-use and standards, improved quality, and a simplified process for everyone.
Secondly, if you’re a data scientist or a data engineer, remember to think about how the ML model is going to be deployed. Instead of keeping the process of building and training models offsite in the data science “lab,” it’s better to make sure the model is an integral part of the business environment. Often, operational business environments don’t have access to the same data that data scientists have when they’re training the model. This is why it’s important for data science projects to start with a clear understanding of how a model will be deployed and the business requirements. Instead of thinking “how can we build the best possible model?”, it’s better to ask “how can we have the biggest impact on the business?”.
For example, let’s say you’re working on a predictive maintenance model for a car to inform drivers if something is not working, giving them recommendations on what to do (e.g. “possible tire problems: contact the workshop”). For your company to be able to make real-time recommendations, the model needs to run inside the car but that means it probably won’t have access to prior service records or data from other vehicles. So there’s no point including those in the model, as useful as they might be in improving accuracy.
Automated Machine Learning Pipelines
The data science process is almost artistic; data scientists need to think about what type of model to implement, what features should go into it, what are the parameters...They have to think of all the different aspects in order to get the right answers to business questions. This is why a huge amount of their work surrounding training or building ML models is done manually or semi-manually.
Once they get to the ModelOps part (model operationalization), when the model is ready for production and needs to be converted into a machine learning pipeline— the work gets fully automated.
By using ML pipelines, you don’t have to create models over and over again from scratch— you can simply retrain your models in an automated way and reuse them in production. Retraining your models — with suitable monitoring of model drift, and other performance metrics — allows you to keep them up to date and keep up with the growing number of data sets and data changes.
You can improve and speed up machine learning modeling by automating the “extract, clean, process” workflow. Automation doesn’t only apply to creating new models, but also to retraining your models, which usually involves aggregating new and old data together and passing it through the pipeline again.
However, automating both the process of training and building ML models, as well as ModelOps, requires the right tool.
How Does Apache Airflow® Improve Machine Learning Pipelines?
Apache Airflow® is an open-source tool to programmatically author, schedule, and monitor your data pipelines. It’s a super-flexible task scheduler and data orchestrator suitable for most everyday tasks: running ETL/ELT jobs, training machine learning models, tracking systems, notifying, completing database backups, powering functions within multiple APIs, and more.
Airflow can help both in the experimentation (semi-manual) and the production (fully automated) phases.
When building a machine learning pipeline with Airflow, you gain:
- Flexibility - You can connect Airflow to any tool. Additionally, Airflow automatically triggers a retry if an error occurs, and won’t pull data until the issue is solved.
- Reproducibility of pipelines - Reuse the same code for different machine learning models and datasets, solving the problem of complexity.
- Productionized ML pipelines - Airflow gives you the ability to build production-ready pipelines for ML models.
- Improved CI/CD - Once you’ve built a model, you can just kick off the pipeline, as Airflow handles independent pieces for you automatically in a CI/CD fashion.
- Easier experimentation stage - Some datasets take hours to pull, but with Airflow, you don’t have to do it manually. Just come back when the initial analytics is done.
Learn more about how Airflow can help with machine learning.
How to Build a Machine Learning Pipeline With Apache Airflow® and Astronomer
In Airflow each pipeline is constructed as a DAG (Directed Acyclic Graph). This allows for a predictable flow for task execution and their resulting data outputs.
Additionally Airflow DAGs are written in Python which as this example demonstrates, opens the opportunity for easy integration with ML pipeline code. This is from both a dependency perspective as well as authoring reusable blocks of code that are grouped into tasks as functions.
When pairing these with the ability to pass large data sets between tasks when XComs are configured to use scalable storage backends, you have all the building blocks for an ML pipeline.
Overview of Example Machine Learning Pipeline
This pipeline pulls Census data from BigQuery and builds a binary classification model with LightGBM to predict whether an individual has ever been married or not.
This simplified example includes the following steps as individual tasks:
- Extract and Load data
- Preprocessing
- Feature Engineering
- Train and Validate
- Fit final model
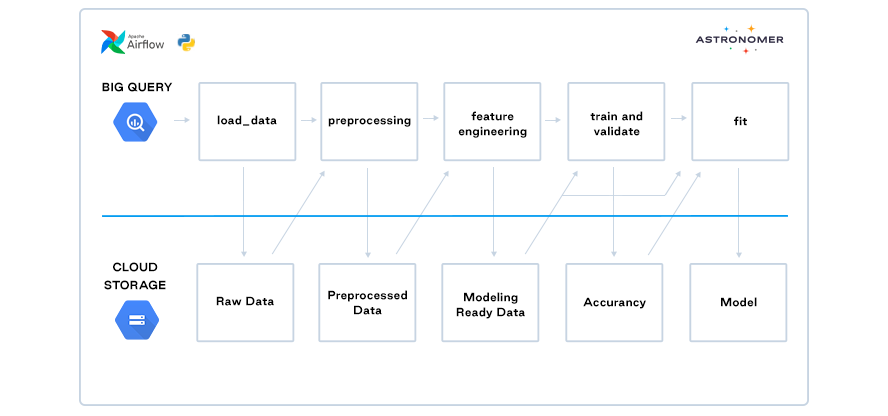
Each of these steps produces an intermediary data set that is saved to Google Cloud Storage (GCS) and gets passed to the subsequent task using XComs. This has the added benefit of creating trackable and reusable data sets as artifacts for each stage of the pipeline that can be analyzed and audited at any time for data quality, data lineage, and model maintenance or monitoring.
Each Airflow task executes code to do the following:

- load_dataa. Extracts Census data from BigQuery as a pandas dataframe.b. Writes to data GCS as a CSV.
- preprocessinga. Cleans extracted data and prepares for feature extraction.b. Then outputs the resulting pandas dataframe as a CSV to GCS.
- feature_engineeringa. Extracts features from preprocessed data.b. Then saves the resulting features and target to GCS.
- cross_validationa. Performs cross validation with Scikit-Learn and LightGBM from the extracted features and target.b. Then outputs the average accuracy to GCS.
- fita. Takes the average accuracy and output of feature_engineering as input and fits the LightGBM model on the entire dataset if the average accuracy from the validation step is .8 or higher.b. Otherwise if the accuracy is too low then it will skip building the final model.c. The final model is saved to GCS which can then be picked up by other pipelines, tools, or applications.
DAG Example
Git repo: https://github.com/astronomer/ds-ml-example-dags
from airflow.decorators import task, dag
from airflow.providers.google.cloud.hooks.bigquery import BigQueryHook
from datetime import datetime
import pandas as pd
import numpy as np
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
from lightgbm import LGBMClassifier
docs = """
By default, Airflow stores all return values in XCom. However, this can introduce complexity, as users then have to consider the size of data they are returning. Futhermore, since XComs are stored in the Airflow database by default, intermediary data is not easily accessible by external systems.
By using an external XCom backend, users can easily push and pull all intermediary data generated in their DAG in GCS.
"""
@dag(
start_date=datetime(2021, 1, 1),
schedule_interval=None,
catchup=False,
doc_md=docs
)
def using_gcs_for_xcom_ds():
@task
def load_data():
"""Pull Census data from Public BigQuery and save as Pandas dataframe in GCS bucket with XCom"""
bq = BigQueryHook()
sql = """
SELECT * FROM `bigquery-public-data.ml_datasets.census_adult_income`
"""
return bq.get_pandas_df(sql=sql, dialect='standard')
@task
def preprocessing(df: pd.DataFrame):
"""Clean Data and prepare for feature engineering
Returns pandas dataframe via Xcom to GCS bucket.
Keyword arguments:
df -- Raw data pulled from BigQuery to be processed.
"""
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)
# Clean Categorical Variables (strings)
cols = df.columns
for col in cols:
if df.dtypes[col]=='object':
df[col] =df[col].apply(lambda x: x.rstrip().lstrip())
# Rename up '?' values as 'Unknown'
df['workclass'] = df['workclass'].apply(lambda x: 'Unknown' if x == '?' else x)
df['occupation'] = df['occupation'].apply(lambda x: 'Unknown' if x == '?' else x)
df['native_country'] = df['native_country'].apply(lambda x: 'Unknown' if x == '?' else x)
# Drop Extra/Unused Columns
df.drop(columns=['education_num', 'relationship', 'functional_weight'], inplace=True)
return df
@task
def feature_engineering(df: pd.DataFrame):
"""Feature engineering step
Returns pandas dataframe via XCom to GCS bucket.
Keyword arguments:
df -- data from previous step pulled from BigQuery to be processed.
"""
# Onehot encoding
df = pd.get_dummies(df, prefix='workclass', columns=['workclass'])
df = pd.get_dummies(df, prefix='education', columns=['education'])
df = pd.get_dummies(df, prefix='occupation', columns=['occupation'])
df = pd.get_dummies(df, prefix='race', columns=['race'])
df = pd.get_dummies(df, prefix='sex', columns=['sex'])
df = pd.get_dummies(df, prefix='income_bracket', columns=['income_bracket'])
df = pd.get_dummies(df, prefix='native_country', columns=['native_country'])
# Bin Ages
df['age_bins'] = pd.cut(x=df['age'], bins=[16,29,39,49,59,100], labels=[1, 2, 3, 4, 5])
# Dependent Variable
df['never_married'] = df['marital_status'].apply(lambda x: 1 if x == 'Never-married' else 0)
# Drop redundant colulmn
df.drop(columns=['income_bracket_<=50K', 'marital_status', 'age'], inplace=True)
return df
@task
def cross_validation(df: pd.DataFrame):
"""Train and validate model
Returns accuracy score via XCom to GCS bucket.
Keyword arguments:
df -- data from previous step pulled from BigQuery to be processed.
"""
y = df['never_married'].values
X = df.drop(columns=['never_married']).values
model = LGBMClassifier()
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
print('Accuracy: %.3f (%.3f)' % (np.mean(n_scores), np.std(n_scores)))
return np.mean(n_scores)
@task
def fit(accuracy: float, ti=None):
"""Fit the final model
Determines if accuracy meets predefined threshold to go ahead and fit model on full data set.
Returns lightgbm model as json via XCom to GCS bucket.
Keyword arguments:
accuracy -- average accuracy score as determined by CV.
"""
if accuracy >= .8:
# Reuse data produced by the feauture_engineering task by pulling from GCS bucket via XCom
df = ti.xcom_pull(task_ids='feature_engineering')
print(f'Training accuracy is {accuracy}. Building Model!')
y = df['never_married'].values
X = df.drop(columns=['never_married']).values
model = LGBMClassifier()
model.fit(X, y)
return model.booster_.dump_model()
else:
return 'Training accuracy ({accuracy}) too low.'
df = load_data()
clean_data = preprocessing(df)
features = feature_engineering(clean_data)
accuracy = cross_validation(features)
fit(accuracy)
# Alternate method to set up task dependencies
# fit(train(feature_engineering(preprocessing(load_data()))))
dag = using_gcs_for_xcom_ds()To learn more about how Airflow and Astronomer can help your machine learning pipelines and processes, get in touch with our experts and or try Astro for free.
----
The article was created with the help of Steven Hillion, Head of Data at Astronomer.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.