Apache Airflow® for Data Scientists
13 min read |
What Is the Role of a Data Scientist?
Data scientist (n): a person who is better at statistics than any software engineer and better at software engineering than any statistician. — Josh Wills, 2012
Roles on a data team are often loosely defined, and there can be a lot of overlap among them. But there are also clear distinctions, especially when it comes to data scientists. Although data engineers and data scientists require roughly parallel skills, the former role focuses mainly on designing pipelines that make data available to and useable by other data professionals, while the latter works with data at all stages, constantly helping an organization to harness data in decision making. Both roles involve building data pipelines, but data scientists veer away from the operational aspect of pipelines to focus on data exploration, spotting trends, developing insights, building models, and explaining what they find through statistical inference, storytelling, and visualizations.
At increasing numbers of companies, the Data Scientist title is reserved for “full-stack” data science professionals — folks who can perform the roles of data engineer, data scientist, machine learning engineer, and data infrastructure engineer. — Santona Tuli, Staff Data Scientist at Astronomer
How Has Data Science Evolved Over the Years?
Data science was born from the notion of combining applied statistics and computer science, with the application of statistical methods to the management of business, operational, marketing, and social networking data. In recent years — as organizations have been flooded with massive amounts of data and turned to complex tools designed to make sense of it — the data scientist function has come to occupy a critical place at the crossroads of business, computer science, engineering, and statistics.
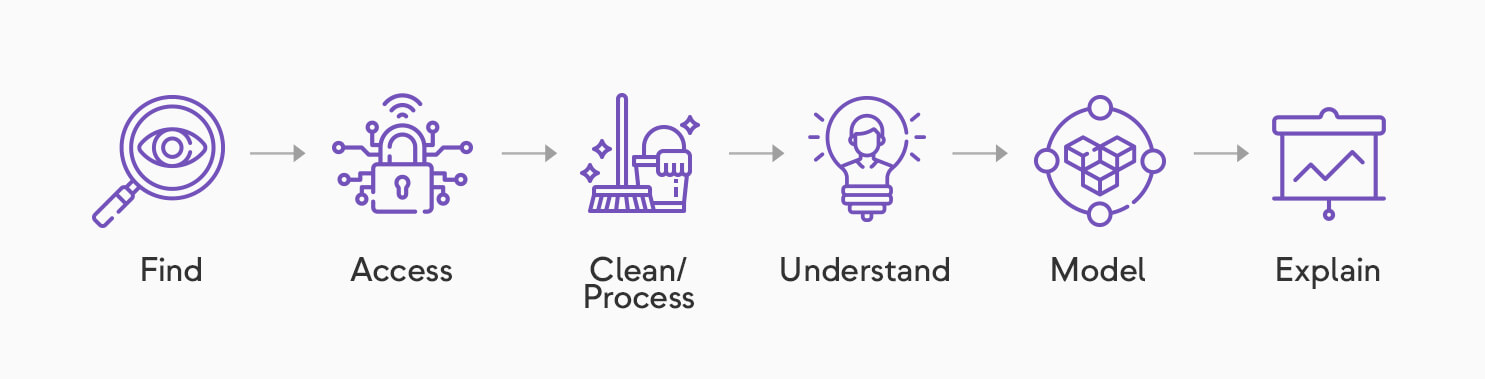
Data scientists add value to organizations in the following ways:
- They identify trends in data, test hypotheses, and recommend direct actions, for themselves and other teams, that help their organizations define business goals and navigate the competitive landscape.
- They reframe business requirements into algorithmic solutions and other analytical approaches.
- They integrate data with proven hypotheses and heuristics from domain experts to capture a more complete and accurate view of behaviors and probabilities.
- They develop and manage data models, and validate results in support of unbiased decision-making.
- Through the socialization of their findings, data scientists steer the business toward focusing on the most urgent needs.
- They establish best practices for the team through the vetted adoption of new tools and workflow changes.
- They equip the marketing and sales teams with tools that help them understand the audience at a very granular level, contributing to the best possible customer experience.
- By applying analytics such as outlier detection, missing value imputation or duplicate removal, they constantly improve the company’s data quality.
Top 4 Common Challenges Data Scientists Face
1. Availability of Data from Multiple Data Sources
As organizations pull increasing amounts of data from multiple applications and technologies, data scientists are there to make meaningful judgments about the data. Without tools to ingest and aggregate data in an automated manner, data scientists have to turn to manually locating and entering data from potentially disparate sources, which, in addition to being time consuming, tends to result in errors, repetitions, and, ultimately, incorrect conclusions.
2. Reproducibility
Reproducibility is the ability to produce the same results each time a process is run using the same tools and the same input data; it is particularly important in environments where the volume of data is large. Certain elements of a data science project can be developed with an eye to reproducibility — generally called “idempotency” in this context — which can help not just with the current project's productivity but also with future models and analyses.
According to a Nature survey (2016), more than 70% of researchers have failed to reproduce another scientist's experiments, and over half of respondents couldn’t manage to reproduce their own work. When it comes to data science, common contributors to a reproducibility crisis include limited data or model availability, varying infrastructure, and time pressure. It’s both technically difficult and time-consuming to manually run a repeatable and reliable data pipeline process.
3. Defining KPIs and Metrics
A good KPI provides an answer to “What does success look like for this project?” in a measurable way. But identifying the right KPIs is always difficult. Metrics and indicators need to both speak to a company's long-term strategy and objectives as well as provide a clear map for action in the short term. And the rapid rise in data availability and organizational data literacy means there are more potential indicators to consider as KPIs, and more people with opinions about those options, than ever before.
4. Coordinating across teams
And then there’s the challenge of coordination across teams. One reason that only 20% of data science models are successfully implemented is almost certainly the fact that data teams, IT, and operations teams all tend to use different tools. When it’s difficult or impossible to swiftly test model assumptions and push them from experimentation to production, or to iterate modifications of models in production, data scientists can find themselves held back from testing hypotheses and defining the best KPIs for a business in a productionized and sustainable manner.
How Does Apache Airflow® Help Data Scientists
Apache Airflow® is a lightweight workflow solution that provides a stable pipeline platform designed to interact with various interfaces and systems. Its workflows are defined, scheduled, and executed as Python scripts — making Airflow extremely flexible, since Python scripts can wrap SQL, Bash, and anything Python can run.
Airflow can make life easier for the data science team at every stage of a project, from exploration and development through to deployment, production, and maintenance. It can reliably and repeatably run complex processes that include monitoring, alerts, data quality checks, restarts, etc., and it enables complicated workflows to be mapped quickly and efficiently. All of which makes it a favorite solution for data leaders.

The Specific Benefits of Airflow in Data Science
Reproducibility
One of the core Airflow principles is idempotency. A task is considered idempotent when the same input will always produce the same result, regardless of the execution time, the number of runs, or the user running it. Idempotency guarantees consistency and resilience in the face of failure.
It’s particularly important for data scientists, who often point to non-reproducible pipelines as one of their daily challenges. With Airflow, it’s possible to develop reproducible data pipelines by using commits (instead of modifying the entire job's code and logic). Airflow’s ability to reproduce tasks and operate on isolated branches is also beneficial for backfilling, manipulating data, and running end-to-end tests on a dedicated branch.
Reusability
Since Airflow is based on modular tasks and customizable DAGs, individual tasks can be shared across projects, common DAG structures can be fully reused, and development can be done iteratively by using predefined interfaces. These properties of Airflow help data scientists, who often use multiple approaches to test ingested data in their efforts to solve ill-defined problems, deliver results ranging from summary statistics to complex ML-enabled analyses with expediency and minimum overhead.
With Airflow, a generic, simple pipeline for early model exploration might look like this:

Each execution of this DAG in Apache Airflow® is logged in a metadatabase, improving traceability and accountability. And the foundation for this (or any) DAG can be predefined to include whatever pre-implemented logic an organization needs — additional security protocols, default access setups, built-in repositories — which will always be available by default for any given project. Data scientists can focus on preprocessing, training, and testing activities across a collection of static data by simply replacing a LOAD task with a local variant — only a single module will need to be replaced when live data becomes available. This module doesn't even have to be written in Python, because Apache Airflow® permits multiple types of Operators in tasks. Finally, an Airflow pipeline can also be a space for collaboration between data scientists and engineers since the pipeline author and the task author need not be the same person or role.
Connecting data sources to Apache Airflow®
Airflow comes with a set of provider packages, which include operators, hooks, and sensors. They make it possible to connect with a variety of external systems. For example, sensors can be used to link data sources to Apache Airflow® from within, while inbound connections may be made via Apache Airflow®'s REST API, which comes with access control and by default provides both information about and control over DAG executions. What makes Airflow really flexible is the possibility to develop customized providers addressing specific needs, so there is virtually no limit to the number and type of data sources connected to an environment. The Astronomer registry offers a spectacular set of provider packages, modules, example DAGs, and free guides on how to implement it all.
Safe testing environment
In Apache Airflow®, the testing environment can be incorporated as a separate workflow, enabling tests to be run and recorded at an early stage. This allows the tests to be equivalent to development-phase solutions, without requiring exploratory code to be reused in the final version. And it means there is no bottleneck when testing multiple hypotheses and pushing them to production.
Smooth workflow
Automated workflow solutions enable more iterative development and testing, with faster coding and testing cycles. Even though exploratory code should not be used in the final version of a product, the segmented, modular nature of Airflow makes it easier to implement and replace individual code sections as they are created. Other previously built modules, executors such as Kubernetes, and activities can also be readily incorporated into a process, reducing both re-implementation and time lost on merging alternative code solutions.
Failures and alerts handling
If the KPI target for a workflow is not achieved, Airflow can identify the failure and perform automated redeployments and reruns. Without this sort of technology, users must repeat onerous manual operations from prior phases, resulting in a slower and less cost-effective recovery.
Retrospection
Apache Airflow® handles logging, traceability, and historical data without requiring any additional implementation or development costs. Logged data may also be accessible straight from the metadatabase, from the UI, or through REST APIs.
The Benefits of Data Orchestration in Data Science
Data orchestration is one of the factors that has made the data scientist role “the sexiest job of the 21st century,” as Harvard Business Review put it a decade ago. Before data orchestration was introduced, data teams relied solely on cron when scheduling data jobs, making the work of a data scientist slower and more mundane. But as the number of cron tasks grew, the increasing volume and complexity became virtually impossible to manage. Meanwhile, digging through logs by hand to measure how a specific job performed became an enormous time sink. And yet another problem involved alerts and failure management, which required on-call engineers with around-the-clock availability to fix upstream failures and manually reset feeds. Each of these issues was, and continues to be, exacerbated by the ever-increasing volume of data and data sources.
Data orchestration solutions arose, in large part, to address these difficulties. It became apparent that orchestration can tackle time-consuming tasks such as failure handling, and improve managing dependencies at scale, allowing data scientists (and others) to focus on vital issues. And the demand for data workflow orchestration has rocketed as more team members have required access to task management and scheduling. The business world has realized that a holistic, comprehensive strategy requires a multidisciplinary team, with data scientists focused on solving business problems at the center and specialized engineers enabling them at every stage.
Today, data teams are arguably best served by implementing a single data management platform to aggregate, integrate, and transform various data sources into valuable, reliable insights. A workflow manager such as Apache Airflow® speeds up every step of the data pipeline process, makes shared data resources available to all, and reduces the chances of conflicting results, all adding up to increased productivity.
Will the Job of a Data Scientist Ever Be Fully Automated?
Even as data science has grown in popularity and become better defined, some are speculating that the entire function can be automated away. While this may be true of certain aspects of what data scientists do — model comparison and visualization generation, for example — these processes are not where data scientists add the most value. The real power of data science lies in how its practitioners turn questions and surprises into exploration and experiments that lead to insights — and how well they relate those insights to business, organizational, and societal needs.
To do their jobs well, data scientists need a comprehensive grasp of business requirements; a deep, collaborative, empathetic engagement with many stakeholders; the ability to communicate with and about data; and the ability to convince business decision-makers to listen and to act on the information offered. A great deal of the manual work data scientists have had to do in the past can be radically streamlined with a tool like Airflow. But there’s no technology on the horizon that will replace human perspective and intuition.
How Does Astronomer Make Airflow Better?
Astro, Astronomer’s fully managed Airflow service, allows data teams to build, run, and manage data pipelines as code at enterprise scale. It enables data scientists and other experts to focus on writing pipelines and accelerating the flow of trusted data across the organizations. Instead of serving as ad hoc DevOps engineers — configuring and troubleshooting issues with an Airflow environment — these experts can devote their energy to value-creating work: identifying new business use cases for ML, AI, and advanced analytics; acquiring and transforming data to feed their statistical models (or train their ML models); testing, perfecting, and productizing these models for production.
Astro also exposes a single control plane you can use to customize, deploy, and manage multiple, distributed Airflow environments. This makes it possible to customize Airflow to suit the specific requirements of your organization’s decentralized teams — data scientists, ML/AI engineers, data analysts, and others. And Astro automatically keeps your Airflow environments up to date with the latest features, bug fixes, and security updates, which makes life easier for your DevOps engineers, too. Last but not least, Astro gives you access to case-by-case problem resolution.
If you and your team are considering (or struggling with) Airflow adoption, sign up for Astronomer Office Hours to speak with one of our experts.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.