Machine Learning Pipeline Orchestration
19 min read |
Production machine learning (ML) pipelines are built to serve ML models that enrich the product and/or user journey to a business’ end users. Machine learning orchestration (MLO) helps implement and manage such pipelines as smoothly running workflows from start to finish, affecting not only real users but also the business bottom line.
To set the stage for MLO, let’s first walk through the steps of a typical ML pipeline. ML pipelines comprise task-based components that work together to deliver the overall value proposition.
- Data featurization - We begin with retrieving raw data from a database (or an API) and perform a set of transformations on them to create features for our ML model. For a production pipeline, it’s best practice to implement feature stores, which help with reproducibility and avoid repeated featurization of the same data.
- ML model training - We train our ML model on the featurized data. In many cases, the model needs to be retrained with a regular cadence. For example, an ML model may need to be retrained once a day, incorporating the most recently generated data, to be relevant to the product the following day. In this case, we retrieve and featurize new data, join them with the relevant previously featurized data from the feature store, and retrain the model on the combined data daily.
- Model evaluation - After training, we evaluate the performance of the trained model instance in order to decide if the new model is ready to be served in production. For ML pipelines where the model is re-deployed on a regular basis, we need to ensure a newly trained instance performs better, or at least as well as, the established model. This process holds for models that are trained afresh as well as ones which evolve through transfer learning.
- Model saving - Once the new model instance is validated, we want to save it in an adequate location and in the appropriate format for it to be picked up and served to users (for example by a microservice).
- Model monitoring - Now that the model is saved and being served, we must monitor it in production. The continuous monitoring of model attributes, including but not limited to performance, enables us to observe and track how a model in production changes over time. In addition to alerting us to any performance degradation, monitoring helps us identify changes in the underlying data, which could signal the need for updates to our pipeline.
Because the steps above are ordered, each depending on its predecessor, the directed flow of data between them is central to ML pipeline architecture and production workflows. The sending and receiving endpoints of components must agree on what, when, and how data will be transferred. Therefore, in order for our ML pipeline to work well in production, its components must be orchestrated: the dependencies and data flow between them coordinated reliably, regularly, and observably. This practice is known as machine learning orchestration.
Let’s dive deeper!
Machine Learning Orchestration in Business
Workflow orchestration in the data and machine learning space today has decidedly increased the productivity of data teams across industries at companies large and small. A one-stop-shop orchestration platform such as Apache Airflow® removes overhead, consolidates tools and techniques, streamlines cross-functional handoffs, and helps businesses scale horizontally as well as vertically.
At Wise, for example, ML engineers utilize many ML frameworks and libraries, such as Tensorflow, PyTorch, XGBoost, H2O, and scikit-learn. When it comes to workflow orchestration, the team leverages Apache Airflow® for retraining their models in Amazon SageMaker.
The BBC, on the other hand, uses Airflow to create templates of workflows, which make delivering new variants of machine learning models easy for the data teams. The Airflow platform helps them achieve a standardized approach to workflow development and reuse code for different use cases.
A common pain point experienced by businesses that serve machine learning in production is the cold start problem. The need for deploying a new ML model instance can be triggered by many events including the launching of a new product, the discovery of a new use case, or the onboarding of a new client. When first booted up, ML pipelines perform poorly relative to when they have reached a steady state. With an orchestrator, especially one that supports a high degree of modularity like Airflow, it’s easier to avoid cold-starting a model. One can simply reuse relevant assets and artifacts from a pipeline already in production which is solving a similar problem.
In the rest of the article, we’ll delve into processes needed and pain points experienced by ML teams impacting the business bottom line, and how orchestration and reusability can help.
Production Machine Learning: Operationalization and Orchestration
As we see in the diagram, production machine learning relies on both the operationalization and orchestration of components. Moreover, the process is iterative and continuous.
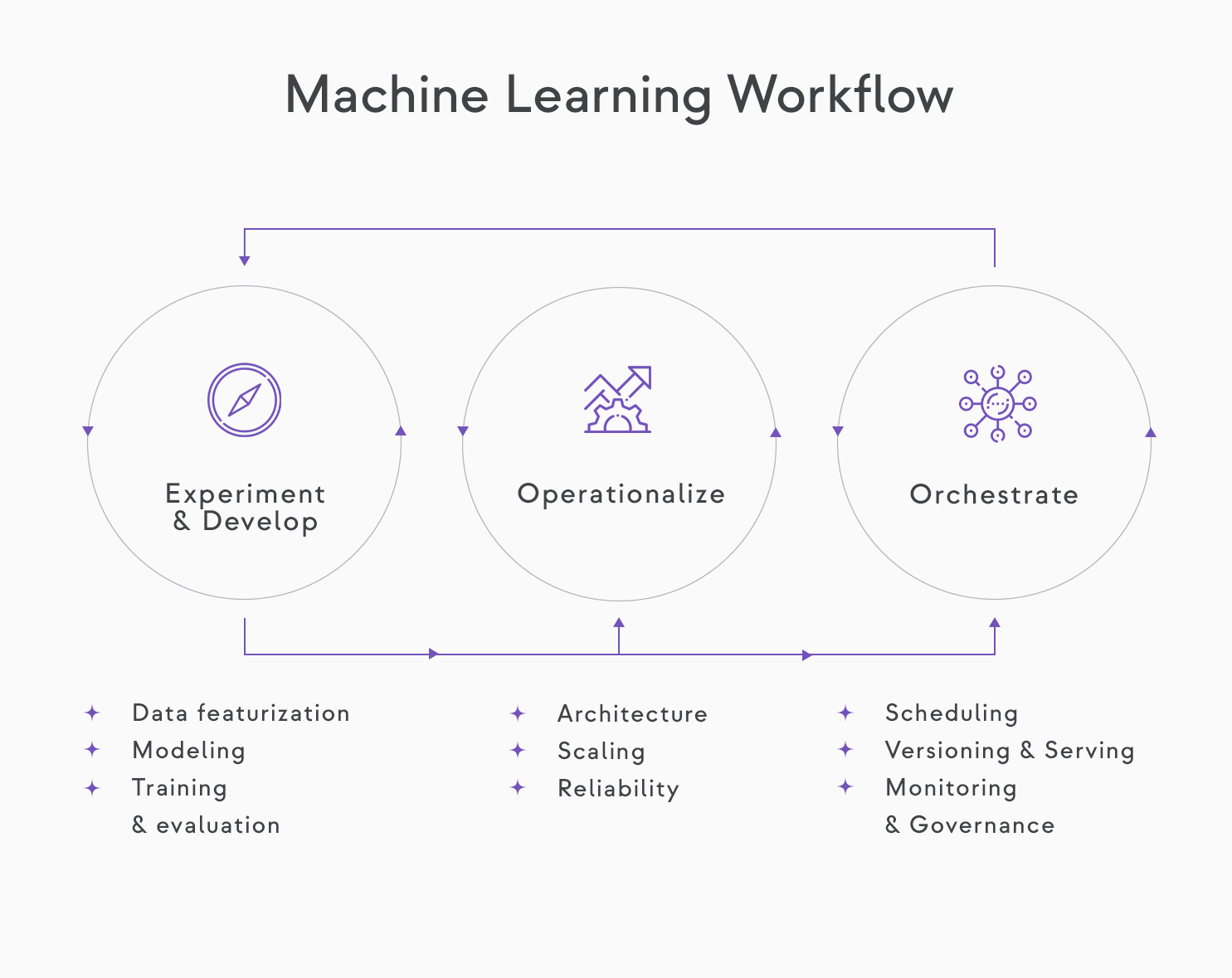 The continuous nature of machine learning workflows.
The continuous nature of machine learning workflows.
While we focus on orchestration in this article, let’s take a high-level look at considerations when operationalizing an ML model first.
Machine learning operationalization and system design
Let’s say we have just built a use-case-driven, performant ML application that hasn’t been pushed to production yet. To get it to production, we need to answer the following questions:
- Architecture & data flow - What does the pipeline look like: what are the steps, how do they relate to each other, how does the data flow, what are the transaction agreements and schema? How does the ML pipeline fit into our other production services/systems? How does the training environment compare to the environment in which the model will be deployed?
- Scaling & scalability - Will our model still work well when we go from thousands of data records to hundreds of thousands?
- Availability & uptime - How available is the service to the end-user: how often does it fail, drop requests, or need downtime (e.g. when new updates are released)?
- Security - What can go wrong with the ML model in its production environment? What vulnerabilities does the ML service or platform introduce to the overall architecture?
Machine Learning Orchestration
Now that we have designed the system in which our ML pipeline is going to live, we’re ready to deploy it so our users can benefit from it!
Machine learning pipelines are dynamic and ever-learning; therefore healthy orchestration of the workflow is fundamental to their success. This is where the fun begins, and where we truly benefit from powerful orchestration solutions like Airflow.
Here are eight components to orchestrating a machine learning model in production:
- Scheduling
Typically, we want to run our pipeline with some regular cadence. After all, if our ML model doesn’t learn and update frequently, it will become stale and worse at addressing the problem it’s designed to solve. We may even want different parts of our pipeline to run on out-of-step schedules. A great orchestration framework enables us to schedule different parts of the pipeline individually, while still defining dependencies holistically. - Syncing
With upstream/downstream dependencies set, we need to make sure that the components of the pipeline talk to each other properly. Specifying the schema for data flow between components—i.e. telling an upstream task what to send and the downstream task what to expect—is only half of it. It’s also important to indicate when and how the component is supposed to transfer data. For example, does a component need to wait until it receives some data, as in a sensor? Is the transaction scheduled or trigger-based? - CI/CD and testing
While integration, testing, and deployment of data and ML pipelines look different than CI/CD and testing in software engineering, they are nonetheless an essential part of a successful productionized ML workflow. Frequent data quality checks make the model dependable. Proper exception and error handling ensure the deployed pipeline and its corresponding service is highly available.
With production data science and machine learning workflows, one expects the business to thrive on—not in spite of—constant experimentation and updates. Our deployed model should always be at its best possible iteration, and should never stagnate. Supporting experimentation on our production workflows allows us as data scientists to keep moving the business forward by testing new hypotheses. As we experiment with the data and ML model, or simply train a model on new data, we must constantly test the pipeline to make sure it continues to function well, both on its own and with the overall system or platform.
Along with the ML pipeline, tests must also be orchestrated and automated as part of the production workflow.
4. Saving & versioning
In order for our model to be ready to be served in production, it needs to be saved and versioned in an efficient way. We provision a feature store and a model store that are accessible to the workflow orchestrator while also being secure. Best practices include turning featurized data and models into storage efficient formats (for example, binary) and allowing storage to be appropriately sized and scalable for the business use case we’re solving.
Versions of the data and model should have clear lineage to versions of the code. This helps us associate our model performance and business value-add at a specific moment in time to the state of the codebase at that time, an essential step in understanding the evolution of our ML service’s business impact, especially when we’re updating it regularly.
5. Retention and cleanup schedule
Our feature and model stores would grow indefinitely if we don’t perform maintenance on them. A retention and cleanup strategy, especially one that is orchestrated in tandem with the pipeline, will help free up space and ensure that the most relevant assets always have a place to inhabit.
6. Monitoring
In addition to helping prevent models from deteriorating and stagnating, monitoring our ML pipeline also helps us understand our data, our users, and the evolving landscape of our business. For example, suppose the launch of a new feature influences user activity. The metric we use to track and predict user activity gets skewed, causing our predictive ML model to falter. Because we have set up monitoring, we notice this change reflected in the behavior of one of the model KPIs, trace it back to the feature release, and recognize the need for a pipeline update to keep up with the changes in the business.
Since monitoring is so crucial to the success of ML in production, let’s take a deeper look at specific monitoring components we want to orchestrate.
- Data drift - All machine learning applications are built on a foundation of assumptions and hypotheses about the core data. For example, our ML model may rely on the normality of a certain feature in the data. In the event that the feature distribution is not in fact normal, the predictions made by the ML model may become unreliable. While validating the normality of the feature when initially developing the pipeline is a necessary step, it’s not a sufficient one. We need to continually validate this assumption using the data, including most recent additions. Thus, this quality check on the data becomes part of the pipeline.
Data validation and governance as a component of ML pipeline orchestration not only guards against the garbage-in-garbage-out problem but also allows us to identify when the underlying data evolves and necessitates introspection of the business assumptions and model architecture.
- Concept drift - Concept drift can be thought of as natural data drift on the aggregate - i.e. rather than monitoring the drift of individual features in data, we are interested in monitoring how the overall representation of the world evolves in the data. Monitoring concept drift comes in especially handy in domains like Natural Language Processing (NLP), where the business use case may depend on understanding topics of discourse amongst groups of users. Because conversations are live and unscripted, the fundamental concepts they encapsulate are likely to evolve over time. The ML model addressing the business use case is likely to rely on assumptions on the concepts—so when concepts drift, we must be able to identify, adapt to and change with the drift.
- Model performance - Finally, and most obviously, we want to monitor how well our ML model performs at its core function - modeling trends in the data by learning from them. Individual ML pipelines’ performance metrics will be guided by their specific requirements and can range from accuracy and average precision to net revenue functions that associate model predictions directly to their effect on business revenue.
An ML model showing stellar performance during its proof-of-concept phase isn’t guaranteed to continue delivering such performance in perpetuity. We need to pay keen attention to, and be prepared to react to, significant drops in the model’s performance at all times. Because of the nascency of machine learning operations (MLOps) as a discipline, surprisingly few production pipelines have correct model monitoring apparatus in place. As the field is coming to realize, however, the relatively small lift of building good monitoring infrastructure ultimately provides immense value. With a powerful orchestration platform like Airflow, the infrastructure is already present—all that remains is to orchestrate monitoring as part of the workflow.
7. System health and reliability tracking
In addition to tracking model health and performance, we want to observe how the ML system and/or service performs at reliably delivering its proposed value to users. While adjacent to the ML model pipeline itself, ensuring high uptime and efficient functioning of the system is fundamental to good production engineering. Machine learning applications do not and cannot live in isolation from their business value proposition. They are part of the product, and increasingly the entirety of the product. Therefore, meeting service level agreements and objectives is part of the pipeline’s charter and best achieved when treated as part of the ML workflow.
The strength of Airflow or a similar platform is that one doesn’t have to switch contexts to go from checking the health of the data and machine learning portion of an ML-based application to the overall system and service health. All of it can be done within the same platform.
8. Governance and Observability
So far we’ve discussed how a production ML pipeline works, but not how to know or what to do when it doesn’t. Machine learning orchestration includes implementing strategies and protocols for robust workflow operation, enabling visibility into the going-ons of the pipeline, and developing tools to govern and intervene in the workflow when needed. Below are a few common techniques used for governance and observability and how they can be achieved through orchestration.
- Checkpoints - As our ML pipeline runs in production, we need to encode reactions to unexpected or undesirable incidents as much as possible. These protocols rely on checkpointing featurized data and trained model instances. Thankfully, we have implemented feature and model stores that help increase the robustness of our pipeline. Additionally, we need to orchestrate these protocols as part of the workflow.
- Challenger vs champion strategy - In this framework, we choose the model deemed most adept at solving the business problem to upgrade to production. This could be the model architecture that outperforms others during the initial proof-of-concept according to relevant metrics. We call this model the champion. We additionally operationalize contender models—the challengers—so that any one of them can replace the champion model if needed.
Operationalizing isn’t enough however, since, unless trained and validated on the latest data, the challengers will not be ready to replace the champion in production and presume its efficacy. Therefore, we need to treat the challenger models exactly as the champion model, orchestrating all the steps we’ve discussed above and keeping them completely in sync with the production pipeline. This way, all the models are part of the same orchestrated workflow and can be interchanged without compromising pipeline quality.
- Fallback protocol - When a model is largely uncontested, we treat it as its own competition. Suppose our newly trained model today performs worse than yesterday’s model against a curated truth data set. Our pipeline must be fully equipped to follow the protocol to fall back to yesterday’s model version without any intervention. Fallback protocols rely on the checkpointed data and trained model instances, and we also need to orchestrate these protocols as part of the workflow.
- Visibility, alerting and intervention - Most end-to-end ML pipelines include observability. Monitoring is incomplete without displaying trends and surfacing alerts when incidents not handled by our automated governance strategies occur so we can intervene directly. This can be set up as dashboards or simply email alerts, both of which can be straightforwardly implemented in Airflow. Moreover, in Airflow, approval workflows can link back into the original pipeline, avoiding repetition and redundancy in compute (and code). Finally, the access controls and environment switching needed for developer involvement can be systematically set up in Airflow.
- Model interpretability metrics - To build ethical and conscientious ML pipelines, we need to keep ourselves and our models accountable. We should extract metrics and attributes from our pipeline that help explain why a model makes the predictions or decisions it makes. This is yet another process that should be orchestrated as part of the workflow.
As we've seen, in order to go from building a machine learning model to having it work for us in production, we need to operationalize and orchestrate its pipeline. The different components such as scheduling, syncing, testing, versioning, and monitoring must all be orchestrated together to create a smoothly functioning and reliable workflow. Additionally, we can orchestrate the required maintenance and governance, both of the model and its infrastructure, in order to ensure the application’s sustainability.
Airflow and Machine Learning Orchestration
The leading tool for orchestration in the data and machine learning space is Apache Airflow®, the go-to platform for programmatically authoring, scheduling, and monitoring data pipelines. We’ve just seen how Airflow can be leveraged for various aspects of ML workflow orchestration—here are some of Airflow’s strengths that make it particularly effective at its job:
- Dependable scheduling - Airflow enables us to reliably schedule different parts of the pipeline, together or separately. It also offers flexibility to switch between real-time, batch, and on-demand processing of data, which adds versatility and reusability to our workflows.
- Complete dependency and flow support - Each task's relationship to the rest can be specified and the transactions between them precisely defined in Airflow—whether it be explicit data transfer using XComs or implicit transfer through the TaskFlow API, decision-based bifurcations of the flow-path, or modularization of groups of tasks. Downstream tasks can wait for upstream tasks to execute properly, ensuring that a task runs only when appropriate and not too soon or too late. In addition to retries and custom error handling, sensors and the recently released deferrable operators, let us define dependencies to the T. Moreover, the DAG graph view allows us to see these relationships mapped out and update to changes as we make them.
- Python-native - Most data science practitioners are familiar with Python, and with Airflow, one can remain within the Python ecosystem for the entirety of their project, from exploration to production. Additionally, this means that Airflow is as extensible as Python itself—the power lies with the community. For example, operators, which are used to define tasks in Airflow, are simply Python classes, making the writing of new operators as simple as subclassing.
- SQL-Python marriage - Transitioning between SQL and Python in ETL pipelines has been made exceptionally easy by the recently released Astro SDK, which enables the loading, transforming, updating and storing of data irrespective of format and in either language, through the use of built-in decorators like @dataframe, @transform and @run_raw_sql.
- Easy integrations - In Airflow, it’s easy to set up and programmatically modify connections to integrate with the rest of the stack. With as many connections as needed available in one place, we can leverage different connections for different components of the workflow based on specific tradeoffs such as latency, availability, and compute needs.
- Containerization - Containerization is core to Airflow’s executor, so we don’t have to implement containerization separately. Specifically, the ability to isolate task dependencies, resource handling, and code execution environments all come baked into our Airflow deployment. The KubernetesExecutor dynamically delegates work and resource pods on a per-task basis and even allows us to configure and modify these pods.
- Custom scalable XComs backend - If we want to allow larger data artifacts to be transferred between tasks, we can scale up XComs with cloud services such as GCS and S3. This feature is great for upgrading from development to production.
A few other attributes stand out particularly for machine learning orchestration:
- Modularity - Airflow makes it particularly easy to implement governance protocols, including hot swapping ML models in production. As long as the endpoints of our components communicate well, what happens inside a task does not disrupt the overall DAG. We can therefore bake governance and approval flows directly into our pipelines.
- End-to-end workflow orchestration - Most MLOps tools only focus on the ML part of the pipeline, which is on one end. Airflow allows us to remain within the same framework for orchestrating the entire pipeline, including the data preparation piece.
- Dynamic task mapping - While not unique to machine learning, the ability to create tasks dynamically during the execution of a pipeline is a powerful tool for flexibility and experimentation in workflows. Yet another recent feature addition in Airflow which makes the data science developer experience enjoyable.
Finally, thanks to the vibrant and dedicated OSS community and the team at Astronomer, there are always more features to look forward to!
In Airflow’s upcoming 2.4 release, the Data Dependency Management and Data Driven Scheduling proposal will come to life. This feature will enable data dependency setting across DAGs, the triggering of DAGs based on dataset updates, and the visualization of inter-DAG data dependencies.
The team is also actively working on improved and native CI/CD tooling, and support for GPU compute which will be a boon for certain ML pipelines.
Best of luck orchestrating your machine learning pipelines with Airflow and reach out to us with any questions!

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.