Apache Airflow® Executors
Apache Airflow® Executors
Executors are a configuration property of the Airflow scheduler component. The executor you choose for a task determines where and how a task is run. You can choose from several pre-configured executors that are designed for different use cases, or define your own custom executor.
In this guide you’ll learn about the executors available in Airflow 3 and how to choose the right one for your use case.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Basic Airflow concepts. See Introduction to Apache Airflow.
- Airflow components. See Airflow components.
How to choose your executor
For production Airflow deployments, there are three main recommended executors you can choose from:
The AstroExecutor is a proprietary executor that is exclusively available for Astro users in Airflow 3 Deployments. It uses agents that are managed by the API server component and can be used both for hosted and remote execution mode Deployments.
The KubernetesExecutor is a containerized executor that runs each task instance in an individual Kubernetes Pod. On Astro, it can be used for hosted execution mode Deployments in Airflow 2 and Airflow 3.
The CeleryExecutor is a queued executor that sends tasks to a Celery broker to be picked up by Celery workers. On Astro, it can be used for hosted execution mode Deployments in Airflow 2 and Airflow 3.
AstroExecutor
The AstroExecutor is the default for all Airflow 3.x Deployments. It uses agents (workers) that pull their work from the API server component and run them in subprocesses. The API server manages the agent lifecycle and controls task assignment logic, which is more reliable than the CeleryExecutor, and starts tasks faster than the KubernetesExecutor.
This executor can be used for both hosted and remote execution mode Deployments on Astro. It is the only executor enabling remote execution on Astro; for remote execution capabilities in other Airflow environments, you can use the EdgeExecutor.
Choose the AstroExecutor for:
- All Airflow 3 Deployments on Astro, unless you have specific requirements to use another executor.
- All remote execution mode Deployments on Astro.
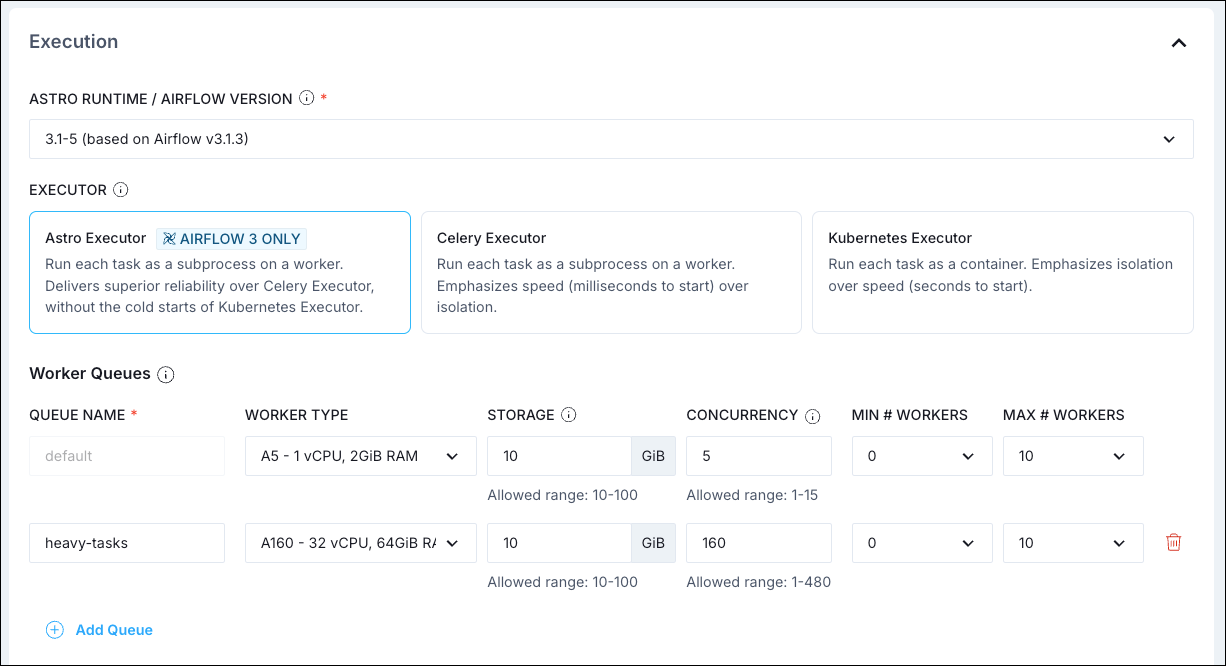
You can use worker queues with the AstroExecutor to run tasks on different worker types with varying resource configurations.
KubernetesExecutor
The KubernetesExecutor is a containerized executor, which means every task instance is run in its own Kubernetes Pod. As such, access to a Kubernetes cluster is required to use this executor. The KubernetesExecutor allows for full task isolation and fine-grained control over the resources allocated to each task, with the trade-off of a slower task startup time.
Choose the KubernetesExecutor for:
- Deployments that require a high degree of task isolation.
- Deployments in which many tasks need to have a specific resource configuration.
There are some additional requirements for using the KubernetesExecutor, which are automatically fulfilled in Astro Deployments configured to run with this executor.
- The Airflow Kubernetes provider needs to be installed.
- The Airflow metadata database cannot be a sqlite database.
You can customize your Kubernetes Pods by setting a base configuration and overriding it at the individual task level using the pod_override parameter. See Configure tasks to run with the KubernetesExecutor for more information on how to configure the KubernetesExecutor on Astro and Kubernetes Executor - Configuration for more information on how to configure the KubernetesExecutor when running it in a self-hosted Airflow environment.
CeleryExecutor
The CeleryExecutor allows you to scale your workload horizontally by running tasks on multiple Celery workers that pick up their tasks from a queue. It can start tasks quickly, since no additional infrastructure needs to be provisioned after the initial setup, and scale horizontally to run many tasks concurrently. Due to these characteristics, the CeleryExecutor is a common default choice for Airflow 2 Deployments on Astro and self-managed Airflow 2 and 3 environments.
Choose the CeleryExecutor for:
- All Airflow 2 Deployments on Astro, unless you have specific requirements to use the
KubernetesExecutor. - Deployments that run consistent workloads with tasks starting frequently.
- Deployments that have high needs for horizontal scaling to run many tasks concurrently.
There are additional requirements for running the CeleryExecutor, which are automatically fulfilled in Astro Deployments configured to run with this executor.
- The Airflow Celery provider needs to be installed.
- A Celery backend like Redis, RabbitMQ, or Redis Sentinel needs to be installed and configured. Astro Deployments use Redis.
On Astro, you can use worker queues with the CeleryExecutor to run tasks on different worker types with varying resource configurations.
To learn more about different configuration options for the CeleryExecutor, see Configure the CeleryExecutor for Astro and Celery Executor for self-managed Airflow environments.
LocalExecutor
The LocalExecutor runs inside the scheduler process and is the simplest option for task execution in Airflow 3, where the SequentialExecutor and DebugExecutor have been removed. Since the LocalExecutor runs in the same process as the scheduler, it does not require any additional infrastructure, but it can have an impact on the scheduler’s performance when running many tasks.
Choose the LocalExecutor for:
- Local development and testing. The Astro CLI uses the LocalExecutor.
- Very light production environments for self-managed Airflow environments
The Airflow configuration variable [core].parallelism determines the maximum number of tasks that can run concurrently with the LocalExecutor per scheduler. The value needs to be at least 1 (default: 32).
Other executors
There are a couple of other executors that are available in self-managed Airflow environments.
- EdgeExecutor: This executor allows you to distribute your tasks to workers in different remote locations via HTTP(s) connections. It is available as part of the Edge3 provider package for Airflow deployments on version 2.10 or later.
- AWS ECS Executor: The
AwsEcsExecutoris a containerized executor that runs each task instance in an individual ECS task. It is available as part of the Amazon provider package. - AWS Batch Executor: The
AwsBatchExecutorruns tasks in separate containers scheduled by AWS Batch. It is available as part of the Amazon provider package. - AWS Lambda Executor (experimental): The
AwsLambdaExecutorsubmits tasks to AWS Lambda to run asynchronously. It is available as part of the Amazon provider package.
The hybrid executors CeleryKubernetesExecutor and LocalKubernetesExecutor have been removed in Airflow 3. In a self-managed Airflow environment, you can configure multiple executors instead, see Configure an executor in self-hosted Airflow.
Configure an executor on Astro
On Astro you can set your executor during the Deployment creation process. The default executor is the AstroExecutor.
If you are creating your Deployment in the Astro UI, you can further configure the AstroExecutor (for example to configure worker queues) or choose a different executor.
- Click the Switch to custom configuration button.
- Select a different executor.
On Astro you can also create Deployments programmatically and set your executor as a configuration option:
- Astro CLI: set the executor using the
--executorflag. The options areAstroExecutor,CeleryExecutor, orKubernetesExecutor. - Astro API: set the executor using the
executorparameter in thePOSTrequest. The options areASTRO,CELERY, orKUBERNETES. - Astro Terraform Provider: set the executor using the
executorparameter in theastro_deploymentresource. The options areASTRO,CELERY, orKUBERNETES.
Configure an executor in self-hosted Airflow
Open-source Airflow allows you to configure multiple executors and assign each task to a different executor using the executor parameter.
In your Airflow configuration file, set the [core].executor variable to the executor(s) you want to use, separated by a comma.
You cannot use two instances of the same executor in the same Airflow environment.
In your task code, assign the executor to the task using the executor parameter. The first executor in the list is the default executor for all tasks where no executor is specified.