Tutorial: How to Orchestrate Databricks Jobs with Airflow
Tutorial: How to Orchestrate Databricks Jobs with Airflow
Databricks is a popular unified data and analytics platform built around Apache Spark that provides users with fully managed Apache Spark clusters and interactive workspaces.
The open source Airflow Databricks provider provides full observability and control from Airflow so you can manage Databricks from one place, including enabling you to orchestrate your Databricks notebooks from Airflow and execute them as Databricks jobs.
Why use Airflow with Databricks
Many data teams leverage Databricks’ optimized Spark engine to run heavy workloads like machine learning models, data transformations, and data analysis. While Databricks offers some orchestration with Databricks Workflows, they are limited in functionality and do not integrate with the rest of your data stack. Using a tool-agnostic orchestrator like Airflow gives you several advantages, like the ability to:
- Use CI/CD to manage your workflow deployment. Airflow Dags are Python code, and can be integrated with a variety of CI/CD tools and tested.
- Use task groups within Databricks jobs, enabling you to collapse and expand parts of larger Databricks jobs visually.
- Leverage Airflow assets to trigger Databricks jobs from tasks in other Dags in your Airflow environment or using the Airflow REST API Create asset event endpoint, allowing for a data-driven architecture.
- Use familiar Airflow code as your interface to orchestrate Databricks notebooks as jobs.
- Inject parameters into your Databricks job at the job-level. These parameters can be dynamic and retrieved at runtime from other Airflow tasks.
- Directly jump from a task in your Airflow Dag to the corresponding Databricks job in the Databricks UI using an operator extra link.
Time to complete
This step-by-step tutorial takes approximately 30 minutes to complete. After completting this tutorial, you will have a working Airflow Dag that orchestrates Databricks notebooks as a Databricks Workflow.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of Databricks. See Getting started with Databricks.
- Airflow fundamentals, such as writing Dags and defining tasks. See Get started with Apache Airflow.
- Airflow operators. See Operators 101.
- Airflow connections. See Managing your Connections in Apache Airflow.
Prerequisites
- The Astro CLI.
- Access to a Databricks workspace. See Databricks’ documentation for instructions. You can use any workspace that has access to the Databricks Workflows feature. You need a user account with permissions to create notebooks and Databricks jobs. You can use any underlying cloud service, and a 14-day free trial is available.
Step 1: Configure your Astro project
-
Create a new Astro project:
-
Add the Airflow Databricks provider package to your requirements.txt file.
Step 2: Create Databricks Notebooks
You can orchestrate any Databricks notebooks in a Databricks job using the Airflow Databricks provider. If you don’t have Databricks notebooks ready, follow these steps to create two notebooks:
-
Create an empty notebook in your Databricks workspace called
notebook1. -
Copy and paste the following code into the first cell of the
notebook1notebook. -
Create a second empty notebook in your Databricks workspace called
notebook2. -
Copy and paste the following code into the first cell of the
notebook2notebook.
Step 3: Configure the Databricks connection
-
Start Airflow by running
astro dev start. -
In the Airflow UI, go to Admin > Connections and click +.
-
Create a new connection named
databricks_conn. Select the connection typeDatabricksand enter the following information:- Connection ID:
databricks_conn. - Connection Type:
Databricks. - Host: Your Databricks host address (format:
https://dbc-1234cb56-d7c8.cloud.databricks.com/). - Password: Your Databricks personal access token.
Alternatively, you can create an OAuth connection to your Databricks workspace by providing the Host, Service Principal Client ID as Login, Service Principal Client Secret as Password and set
service_principal_oauthtoTruein the Extra field. - Connection ID:
Astro customers can use the Astro Environment Manager to create a connection to Databricks, stored in the Astro-managed secrets backend. This connection can be shared across multiple Deployments in a Workspace.
Step 4: Create your Dag
-
In your
dagsfolder, create a file calledmy_simple_databricks_dag.py. -
Copy and paste the following Dag code into the file. Replace
<your-databricks-login-email>variable with your Databricks login email. If you already had Databricks notebooks and did not create new ones in Step 2, adjust thenotebook_pathparameters in the two DatabricksNotebookOperators to point to the existing notebooks. Adjust thejob_cluster_specto match your available cloud resources.This Dag uses the Airflow Databricks provider to create a Databricks job that runs two notebooks. The
databricks_workflowtask group, created using theDatabricksWorkflowTaskGroupclass, automatically creates a Databricks job that executes the Databricks notebooks you specified in the individual DatabricksNotebookOperators. One of the biggest benefits of this setup is the use of a Databricks job cluster, allowing you to significantly reduce your Databricks cost. The task group contains three tasks:- The
launchtask, which the task group automatically generates, provisions a Databricksjob_clusterwith the spec defined asjob_cluster_specand creates the Databricks job from the tasks within the task group. - The
notebook1task runs thenotebook1notebook in this cluster as the first part of the Databricks job. - The
notebook2task runs thenotebook2notebook as the second part of the Databricks job.
- The
-
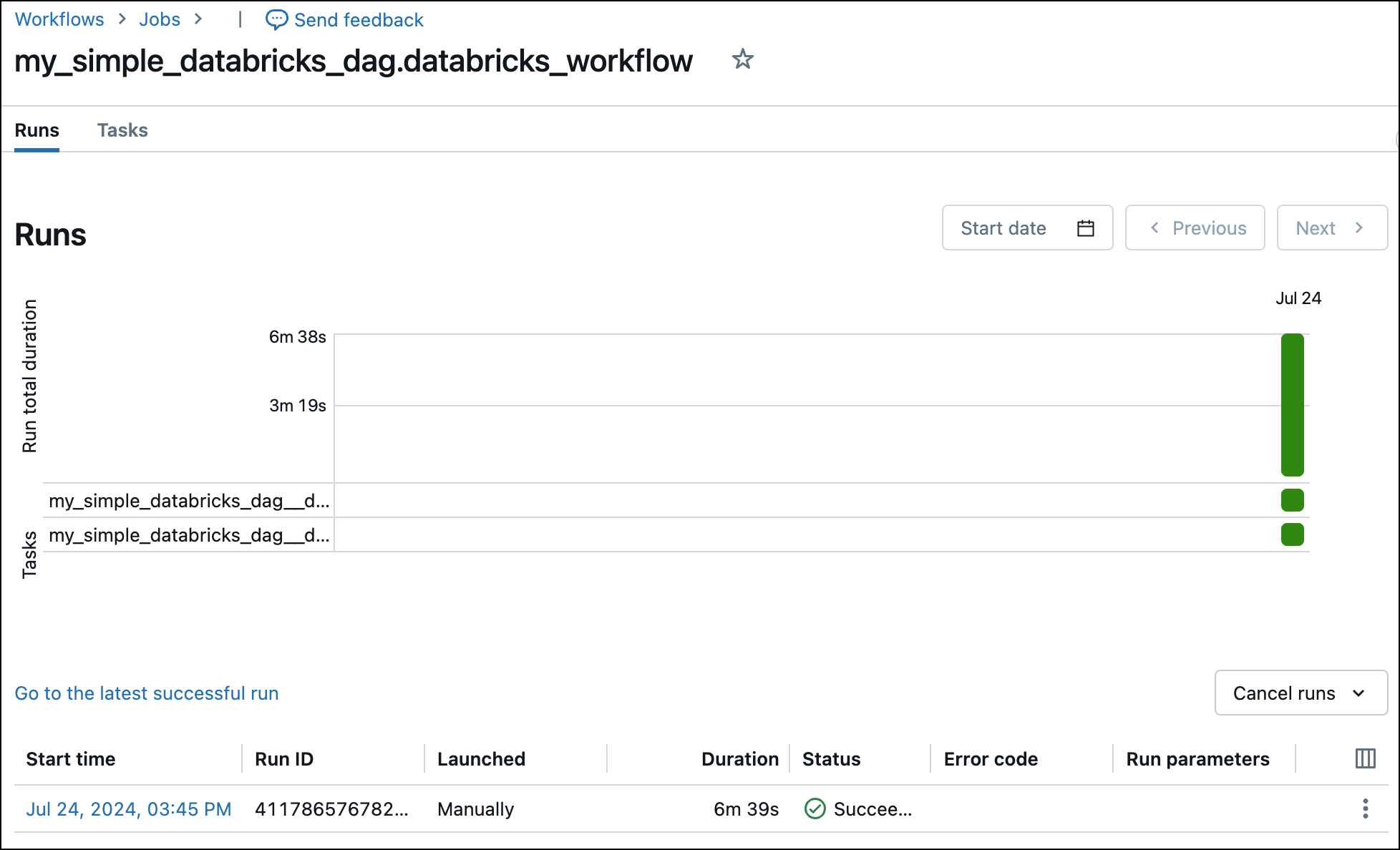
Run the Dag manually by clicking the play button and view the Dag in the graph tab. In case the task group appears collapsed, click it in order to expand and see all tasks.

-
View the completed Databricks job in the Databricks UI.
Step 5 (optional): Add a task to run SQL
You can run any SQL query in Databricks using the DatabricksSqlOperator from the Airflow Databricks provider. In your Dag, outside of the databricks_workflow task group, add the following task. Replace the placeholder values with your own values.
Alternatively, you can also use the DatabricksHook directly in any @task decorated function or PythonOperator in your Dag.
How it works
This section explains Airflow Databricks provider functionality in more depth. You can learn more about the Airflow Databricks provider, including more information about other available operators, in the provider documentation.
Parameters
The DatabricksWorkflowTaskGroup provides configuration options via several parameters:
-
job_clusters: the job clusters parameters for this job to use. You can provide the fulljob_cluster_specas shown in the tutorial Dag. -
notebook_params: a dictionary of parameters to make available to all notebook tasks in a job. This operator is templatable, see below for a code example:To retrieve this parameter inside your Databricks notebook add the following code to a Databricks notebook cell:
-
notebook_packages: a list of dictionaries defining Python packages to install in all notebook tasks in a job. -
extra_job_params: a dictionary with properties to override the default Databricks job definitions.
You also have the ability to specify parameters at the task level in the DatabricksNotebookOperator:
notebook_params: a dictionary of parameters to make available to the notebook.notebook_packages: a list of dictionaries defining Python packages to install in the notebook.
Note that you cannot specify the same packages in both the notebook_packages parameter of a DatabricksWorkflowTaskGroup and the notebook_packages parameter of a task using the DatabricksNotebookOperator in that same task group. Duplicate entries in this parameter cause an error in Databricks.