

The CLI level
Airflow standalone

Airflow standalone runs all parts of an Airflow deployment under one primary process, providing a more manageable entry level than Breeze and a convenient tool for local development.
What can Airflow standalone do?
- Runs all database migrations/db init steps
- Creates an admin user if one is not present (with a randomized password)
- Runs the webserver
- Runs the scheduler
- Runs the triggerer
- Overrides the executor to be
LocalExecutororSequentialExecutordepending on the database in use
airflow db shell
airflow db shell → There are various ways you can inspect data, including — if you have direct access to the database — interacting with it using your own tools (often graphical tools showing the database objects). But if you don't have such tools, you can use the airflow db shell command — this will drop you in the db shell tool for your database, and you will be able to inspect your data.
CLI commands
airflow info → shows information about the current Airflow environment, crucial Airflow details such as version, executor used, connection string, DAGs folder, python version.
tools info → if you want to interact with Git or Postgres from your tasks, you may need to install them. (Notice that Airflow expects that you have those tools installed.)
paths info → especially python_path. If you add a folder with your external functions that you call from your DAGs, you want to make sure that environment is aware of it — otherwise, it won’t work.
providers info → what providers are installed? Which version?
airflow dags test → Executes one single DagRun for a given DAG and execution date using the DebugExecutor.
⚠️ This command generates metadata (DAG runs, task runs etc).
DebugExecutor: meant as a debug tool and can be used from IDE. It is a single process executor that queues TaskInstance and executes it.
airflow tasks test -m → Tests a task instance. Will run a task without checking for dependencies or recording its state in the database.
# easy_dag.py
def _my_func():
my_val = 123
raise ValueError("exception")
return(my_val)⚠️ XCOMs are stored
The UI level

Airflow allows you to customize the DAG home page header and the page title. It can help distinguish between various installations of Airflow, or simply be used to amend the page text.
Note: the custom title will be applied to both the page header and the page title.
To make this kind of change, simply:
# in .env
AIRFLOW__WEBSERVER__INSTANCE_NAME=DEV
astro dev stop && astro dev start
Extra alert messages can be shown on the UI dashboard, which is particularly useful for warning about setup issues or announcing changes to end-users.
- Create a config folder (make sure it exists in the PYTHONPATH)
- Create a file airflow_local_settings.py
- Add the following content
from airflow.www.utils import UIAlert
#"info", "warning", "error"
DASHBOARD_UIALERTS = [
UIAlert("Update!", category="info", roles=["User", "Admin"]),
UIAlert("Check user permissions", category="warning", roles=["Admin"]),
]
astro dev stop && astro dev startThe DAG level
Taskflow API
- Decorators
- XComArgs (inference)
# taskflow.py
from airflow import DAG
from airflow.decorators import task
from datetime import datetime
with DAG('taskflow',
start_date=datetime(2022, 1 ,1),
schedule_interval='@daily',
catchup=False) as dag:
@task
def setup(my_data):
print(f"setup dataset {my_data}")
return my_data + 2
@task
def load(my_modified_data):
print(f"load dataset {my_modified_data}")
load(setup(42))💡 As with any operator, you can pass parameters to task() like trigger_rule, task_id etc.
💡 You can mention the other decorators — docker, branch, virtualenv — and you can create custom decorators, too.
Taskgroup
# taskflow.py
from airflow import DAG
from airflow.decorators import task, **task_group**
from datetime import datetime
with DAG('taskflow',
start_date=datetime(2022, 1 ,1),
schedule_interval='@daily',
catchup=False) as dag:
@task
def setup(my_data):
print(f"setup dataset {my_data}")
return my_data + 2
**@task_group(group_id='ml_tasks')
def ml_tasks(value):
@task
def ml_1(value):
return value + 42
@task
def ml_2(value):
return value - 42
return [ml_1(value), ml_2(value)]**
@task
def load(my_modified_data):
print(f"load dataset {my_modified_data}")
load(**ml_tasks(**setup(42)**)**)💡 You can use default_args in taskgroup to apply default arguments to tasks present only within that group. Especially useful for pools!
Edgemodifier
You can label the dependency edges between different tasks in the Graph view — this can be especially useful for branching areas of your DAG, allowing you to label the conditions under which certain branches might run.
from airflow import DAG
from airflow.decorators import task, task_group
**from airflow.utils.edgemodifier import Label**
from datetime import datetime
with DAG('taskflow',
start_date=datetime(2022, 1 ,1),
schedule_interval='@daily',
catchup=False) as dag:
@task
def setup(my_data):
print(f"setup dataset {my_data}")
return my_data + 2
@task_group(group_id='ml_tasks')
def ml_tasks(value):
@task
def ml_1(value):
return value + 42
@task
def ml_2(value):
return value - 42
**return [value >> Label("decision tree") >> ml_1(value),
value >> Label("random forest") >> ml_2(value)]**
@task
def load(my_modified_data):
print(f"load dataset {my_modified_data}")
load(ml_tasks(setup(42)))Airflow Exceptions
from airflow import DAG
from airflow.decorators import task, task_group
from airflow.utils.edgemodifier import Label
**from airflow.exceptions import AirflowFailException, AirflowException, AirflowSkipException**
from datetime import datetime
with DAG('taskflow',
start_date=datetime(2022, 1 ,1),
schedule_interval='@daily',
catchup=False) as dag:
**@task(retrie=3)**
def setup(my_data):
**raise AirflowFailException # Doesn't respect retries, AirflowException does**
print(f"setup dataset {my_data}")
return my_data + 2
@task_group(group_id='ml_tasks')
def ml_tasks(value):
@task
def ml_1(value):
return value + 42
@task
def ml_2(value):
return value - 42
return [value >> Label("decision tree") >> ml_1(value),
value >> Label("random forest") >> ml_2(value)]
@task
def load(my_modified_data):
print(f"load dataset {my_modified_data}")
load(ml_tasks(setup(42)))Dynamic DAGs with Jinja
Jinja is a template engine that takes a template file with special placeholders and replaces them with data from a source. Apache Airflow® uses Jinja to build its webpages as well as to render values in DAG files at run time.
There are various methods of generating DAGs dynamically:
→ Single file method with globals → Multiple files method with JSON → Multiple files method with Jinja
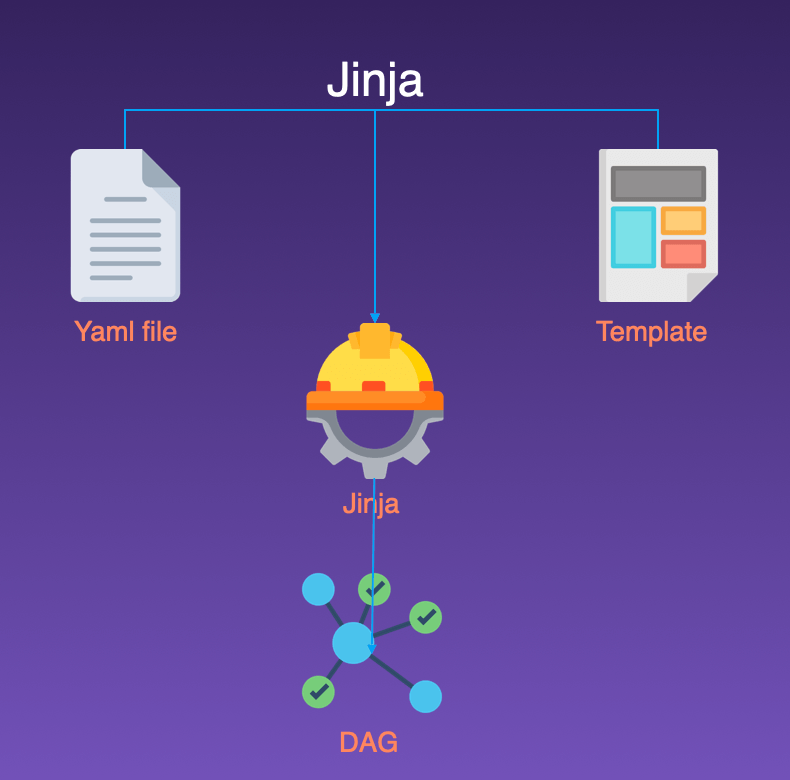
- show template_dag.jinja2 under include/dynamic_dag_jinja
- show config yaml files
- show the script
- execute the script to generate dags
python include/dynamic_dag_jinja/generate_dag.py
Deferrable Operators
Sensors take worker slots, waste resources, time, and possibly cause deadlocks.
Deferrable operators suspend themselves and release worker slots: they reduce resource consumption, lower infra cost, and are more resilient.
Two components:
Trigger: An asynchronous Python function that quickly and continuously evaluates a given condition. An Operator must have its own Trigger code to be async
Triggerer: Responsible for running Triggers and signaling tasks to resume when their conditions have been met. Like the Scheduler, it is designed to be highly available.
💡 In addition to the deferrable operators that are published by the Apache Airflow® open source project, Astronomer maintains astronomer-providers, an open-source collection of deferrable operators bundled as provider packages.
How to stay up to date?
Changelog → https://airflow.apache.org/docs/apache-airflow/stable/changelog.html
Apache Airflow® Slack → #airflow-releases and #announcements
Astronomer Academy → https://academy.astronomer.io/
Marc’s little trick → go to https://github.com/apache/airflow/milestones

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.