Understanding the Airflow metadata database
This page hasn’t yet been updated for Airflow 3. The concepts shown are relevant, but some code may need to be updated. If you run any examples, take care to update import statements and watch for any other breaking changes.
The metadata database is a core component of Airflow. It stores crucial information such as the configuration of your Airflow environment’s roles and permissions, as well as all metadata for past and present DAG and task runs.
A healthy metadata database is critical for your Airflow environment. Losing data stored in the metadata database can both interfere with running DAGs and prevent you from accessing data for past DAG runs. As with any core Airflow component, having a backup and disaster recovery plan in place for the metadata database is essential.
In this guide, you’ll learn everything you need to know about the Airflow metadata database to ensure a healthy Airflow environment, including:
- Database specifications.
- Important content stored in the database.
- Best practices for using the metadata database.
- How to use the Airflow REST API to access the metadata database.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Basic Airflow concepts. See Introduction to Apache Airflow.
- Airflow core components. See Airflow’s components.
Database specifications
Airflow uses SQLAlchemy and Object Relational Mapping (ORM) in Python to connect with the metadata database from the application layer. Any database supported by SQLAlchemy can theoretically be configured to host Airflow’s metadata. The most common databases used are:
- Postgres
- MySQL
- SQLite
While SQLite is the default on Apache Airflow, Postgres is by far the most common choice and is recommended for most use cases by the Airflow community. Astronomer uses Postgres for all of its Airflow environments, including local environments running with the Astro CLI and deployed environments on the cloud.
You should also consider the size of your metadata database when setting up your Airflow environment. Production environments typically use a managed database service, which includes features like autoscaling and automatic backups. The size you need will depend heavily on the workloads running in your Airflow instance. For reference, Apache Airflow uses a 2 GB SQLite database by default, but this is intended for development purposes only. The Astro CLI starts Airflow environments with a 1 GB Postgres database.
Changes to the Airflow metadata database configuration and its schema are very common and happen with almost every minor update. To downgrade your Airflow environment, use the db downgrade command.
Metadata database content
There are several types of metadata stored in the metadata database.
- User login information and permissions.
- Information used in DAGs, like variables, connections and XComs.
- Data about DAG and task runs which are generated by the scheduler.
- Other minor tables, such as tables which store DAG code in different formats or information about import errors.
For many use cases you can access content from the metadata database in the Airflow UI or the stable REST API. These points of access always beat querying the metadata database directly!
User information (security)
A set of tables store information about Airflow users, including their permissions to various Airflow features. As an admin user, you can access some of the content of these tables in the Airflow UI under the Security tab.
DAG configurations and variables (Admin)
DAGs can retrieve and use a variety of information from the metadata database such as:
The information in these tables can be viewed and modified under the Admin tab in the Airflow UI.
DAG and task runs (browse)
The scheduler depends on the Airflow metadata database to keep track of past and current events. The majority of this data can be found under the Browse tab in the Airflow UI.
- DAG Runs stores information on all past and current DAG runs including whether they were successful, whether they were scheduled or manually triggered, and detailed timing information.
- Jobs contains data used by the scheduler to store information about past and current jobs of different types (
SchedulerJob,TriggererJob,LocalTaskJob). - Audit logs shows events of various types that were logged to the metadata database (for example, DAGs being paused or tasks being run).
- Task Instances contains a record of every task run with a variety of attributes such as the priority weight, duration, or the URL to the task log.
- Task Reschedule lists tasks that have been rescheduled.
- Triggers shows all currently running triggers.
- SLA Misses keeps track of tasks that missed their SLA.
Other tables
There are additional tables in the metadata database storing data ranging from DAG tags over serialized DAG code, import errors to current states of sensors. Some of the information in these tables will be visible in the Airflow UI in various places:
- The source code of DAGs can be found by clicking on a DAG name from the main view and then going to the Code view.
- Import errors appear at the top of the DAGs view in the UI.
- DAG tags will appear underneath their respective DAG with a cyan background.
Airflow metadata database best practices
-
When upgrading or downgrading Airflow, always follow the recommended steps for changing Airflow versions: back up the metadata database, check for deprecated features, pause all DAGs, and make sure no tasks are running.
-
Use caution when pruning old records from your database with
db clean. For example, pruning records could affect future runs for tasks that use thedepends_on_pastargument. Thedb cleancommand allows you to delete records older than--clean-before-timestampfrom all metadata database tables or a list of tables specified. -
Memory in the Airflow metadata database can be limited depending on your setup, and running low on memory in your metadata database can cause performance issues in Airflow. This is one of the many reasons why Astronomer advises against moving large amounts of data with XCom, and recommends using a cleanup and archiving mechanism in any production deployments.
-
Since the metadata database is critical for the scalability and resiliency of your Airflow deployment, it is best practice to use a managed database service for production environments, for example AWS RDS or Google Cloud SQL. Alternatively, you can use a managed Airflow service like Astro with a built-in scalable and resilient metadata database.
-
When configuring a database backend, make sure your version is fully supported by checking the Airflow documentation.
Use the Airflow REST API to access the metadata database
The best method for retrieving data from the metadata database is using the Airflow UI or making a GET request to the Airflow REST API.
Between the UI and API, much of the metadata database can be viewed without the risk inherent in direct querying. In rare cases where neither the Airflow UI nor the REST API can provide sufficient data, it is possible to use SQLAlchemy with Airflow models to access data from the metadata database. Direct querying of the metadata database isn’t recommended since direct manipulation can result in corruption of your Airflow instance.
This section shows three examples of how to use the Airflow REST API to interact with the Airflow metadata database.
Retrieve the number of successfully completed tasks
A common reason users may want to access the metadata database is to get metrics like the total count of successfully completed tasks.
Using the stable REST API to query the metadata database is the recommended way to programmatically retrieve this information. Make sure you have correctly authorized API use in your Airflow instance and set the ENDPOINT_URL to the correct location (for local development: http://localhost:8080/).
The Python script below uses the requests library to make a GET request to the Airflow API for all successful (state=success) Task Instances of all (shorthand: ~) DAG runs of all (~) DAGs in the Airflow instance. A user name and password stored as environment variables are used for authentication. By printing the total_entries property of the API response JSON, one can get a count of all successfully completed tasks.
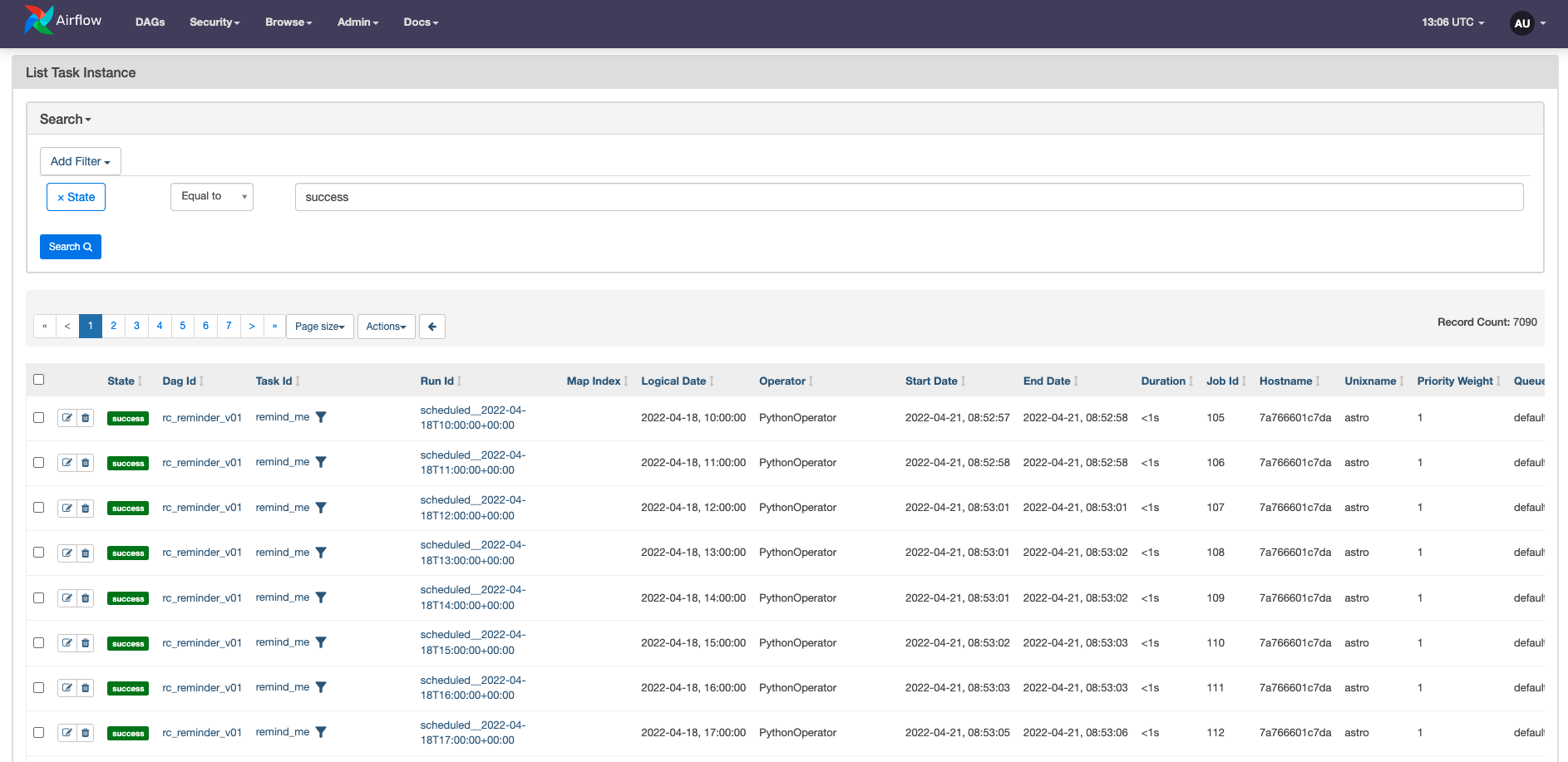
It is also possible to navigate to Browse -> Task Instances in the Airflow UI and filter the task instances for all with a state of success. The Record Count will be on the right side of your screen.
Pause and unpause a DAG
Pausing and unpausing DAGs is a common action when running Airflow and while you can achieve this by manually toggling DAGs in the Airflow UI, depending on your use case and the number of DAGs you want to toggle this might be tedious. The Airflow REST API offers a simple way to pause and unpause DAGs by sending a PATCH request.
The Python script below sends a PATCH request to the Airflow API to update the entry for the DAG with a specific ID (here example_dag_basic), which is paused (update_mask=is_paused) with a JSON that will set the is_paused property to True therefore unpausing the DAG.
Delete a DAG
Deleting the metadata of a DAG can be accomplished either by clicking the trashcan icon in the Airflow UI or sending a DELETE request with the Airflow REST API. This isn’t possible while the DAG is still running, and won’t delete the Python file in which the DAG is defined, meaning the DAG will appear again in your UI with no history at the next parsing of the /dags folder from the scheduler.
The Python script below sends a DELETE request to a DAG with a specific ID (here: dag_to_delete).