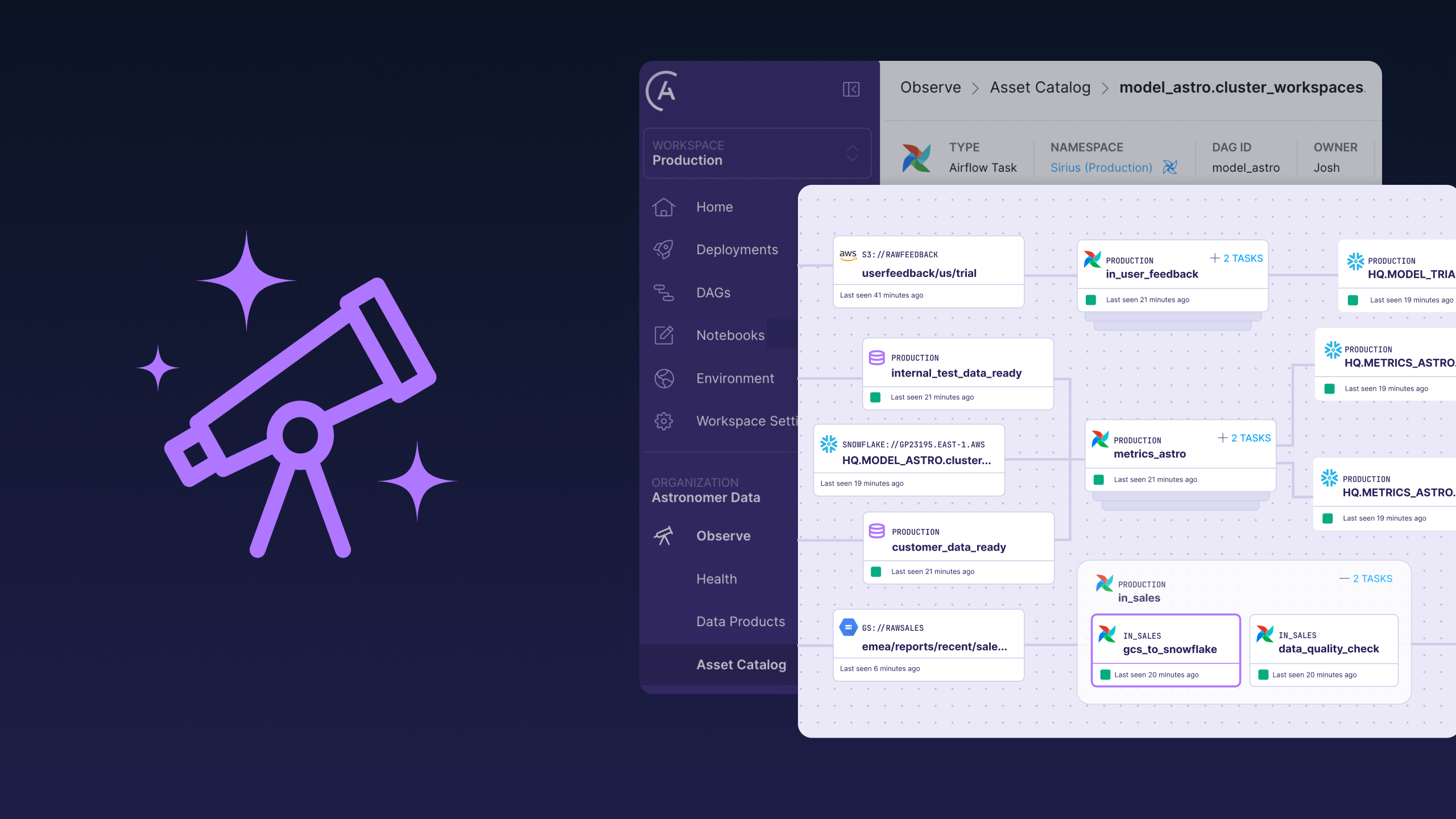
In an AI world, it’s the workflow that allows you to build your moat
While LM Arena leaderboards grab headlines, an infrastructure battle is happening in the orchestration systems that transform AI from lab experiments into production solutions that solve real-world problems.