Orchestrating Machine Learning Pipelines with Airflow
4 min read |
In the realm of machine learning, managing workflows efficiently is paramount. One tool that has emerged as a game-changer in this space is Apache Airflow®. Specifically, Airflow's capability to handle large amounts of machine learning (ML) workflows offers a robust Machine Learning Operations (MLOps) solution for managing complex ML pipelines, handling data dependencies, and ensuring fault tolerance. Some of Airflow’s unique advantages in handling MLOps workflows as the center of your modern data stack include:
Dependency Management: ML workflows often consist of multiple stages, from data extraction and preprocessing to model training and deployment. Airflow's DAG structure ensures that tasks are executed in the correct order, respecting dependencies and ensuring data integrity.
Scalability: As data grows, ML tasks can become resource-intensive. Airflow can distribute tasks across a cluster, allowing for parallel execution and efficient resource utilization, making it suitable for handling large datasets and complex computations.
Error Handling and Retries: In the ML lifecycle, tasks might fail due to various reasons, from data inconsistencies to resource constraints. Airflow provides robust error handling mechanisms, allowing for automatic retries, notifications, and even branching logic based on task outcomes.
Extensibility: Airflow has a rich ecosystem of plugins and integrations. Whether you're pulling data from a new source, integrating with a different ML framework, or deploying to a specific environment, there's likely a plugin or a template that can help.
Monitoring and Logging: Transparency is crucial in ML workflows to trace issues, understand model performance, and ensure data quality. Airflow provides detailed logs for each task, along with a visual interface to monitor the progress and status of your workflows.
The Producer/Consumer Relationship in Machine Learning
In many organizations, ML pipelines are managed by two distinct teams: the producers and the consumers. The producer team is responsible for curating and cleaning the data, while the consumer team utilizes this data to train and refine their ML models. This bifurcation can sometimes lead to friction, especially when there isn't a streamlined mechanism for the producer team to deliver clean data reliably.
Airflow introduces a solution to this challenge. By leveraging Airflow datasets and data-driven scheduling, it's possible to schedule a consumer DAG to run only after its corresponding producer DAG has completed. This ensures that the consumer team always has access to the most recent and relevant data, eliminating potential inconsistencies or delays.
A Practical Implementation
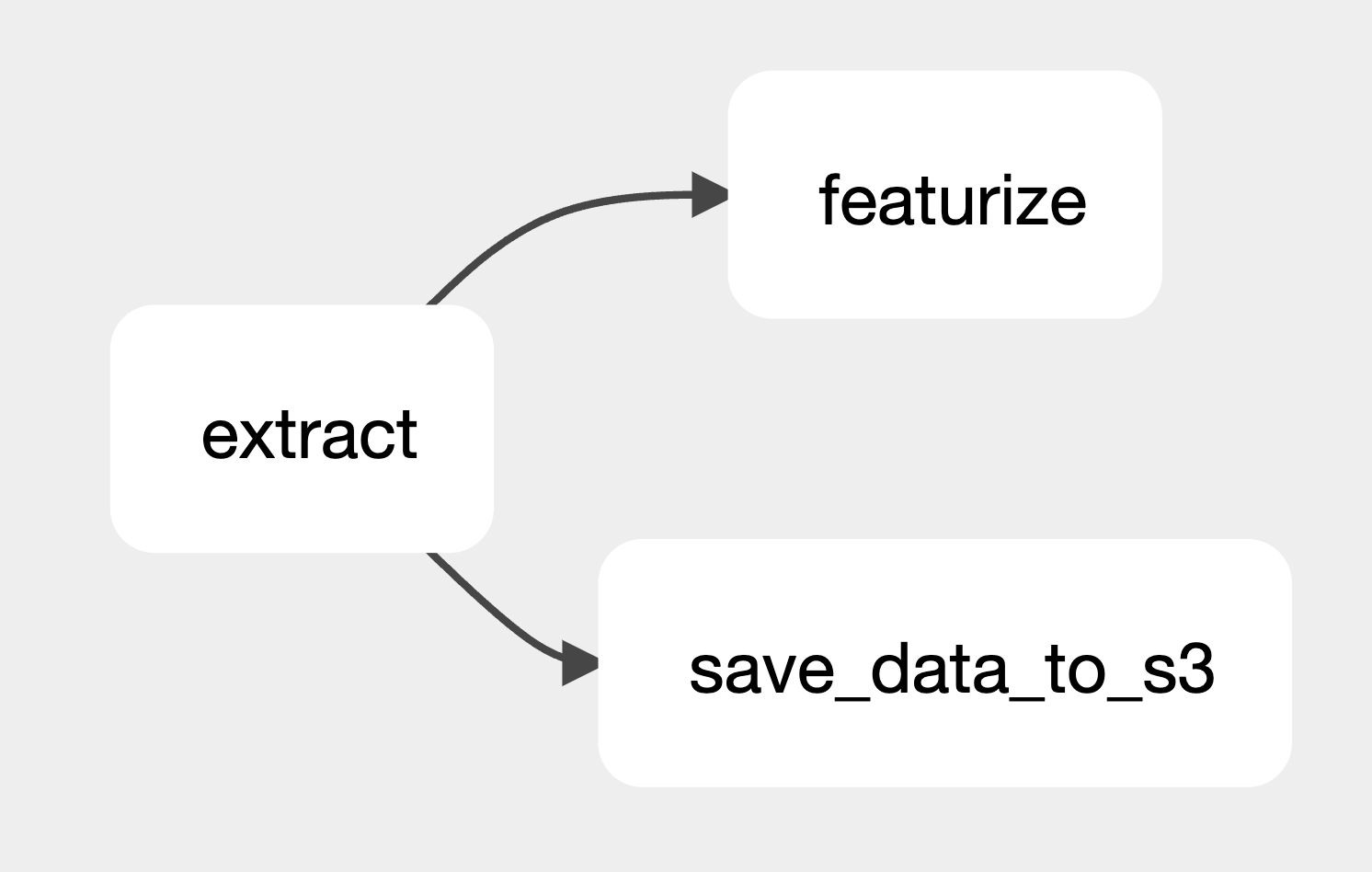
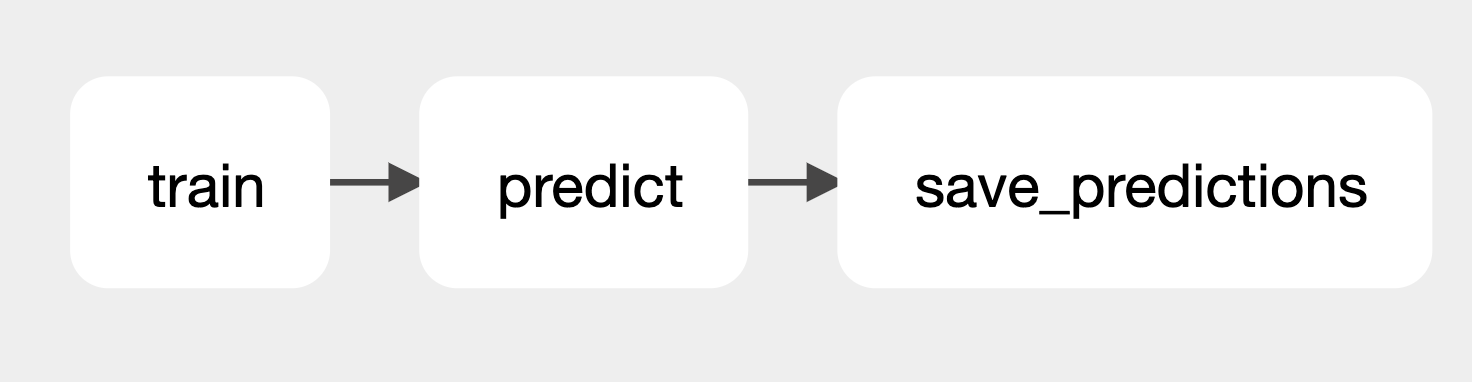
A practical example of this can be seen in a project where one DAG extracts and loads housing data into a shared file system. Once this data is loaded, it triggers a second consumer DAG. This consumer DAG then uses the data from the producer DAG to train and run a predictive model.
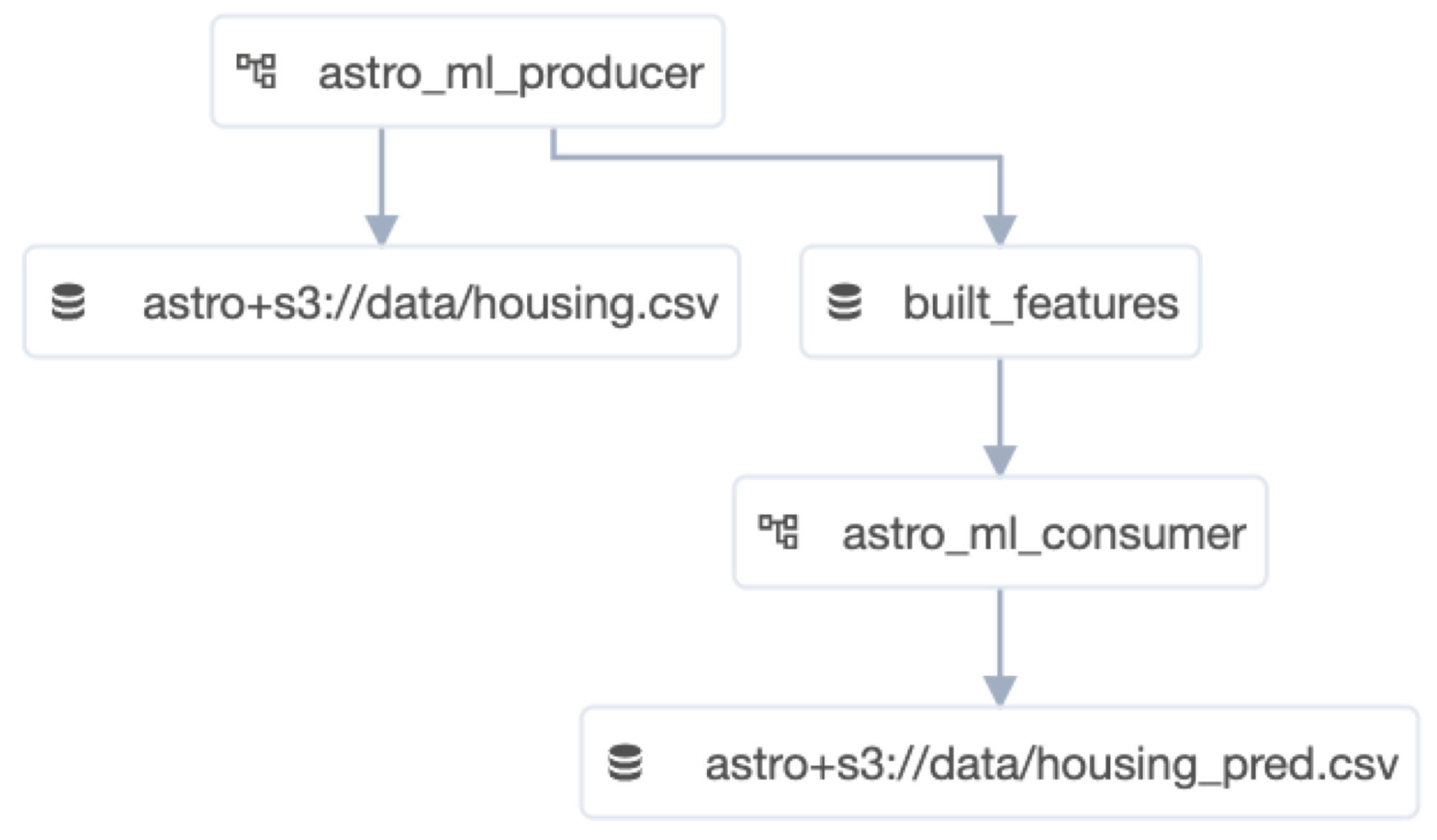
There are two primary benefits of this set up. The first being that both teams can operate independently after the initial setup, eliminating the need for constant coordination. The second is that the consumer DAG is only triggered after the data is ready, preventing scenarios where the producer DAG might take longer than expected to produce a dataset, causing the Consumer DAG to run with either empty or out-of-date data.
If you’re interested in seeing this in action or trying it yourself, come on over to our Learn page to get started with a step-by-step guide on how it all works! You can use the Astro CLIto get started with a local Airflow environment, and if you want to spin up Airflow in less than 5 minutes to start orchestrating your MLOps, start a free trial of Astro!
In Conclusion
The Producer/Consumer use case in Airflow, as described in the Astronomer Learn article, underscores the importance of a robust MLOps platform to manage your workflows as your organization scales. By ensuring that data is consistently and reliably delivered to the right teams at the right time, organizations can optimize their ML operations, reduce friction between teams, and ultimately drive better outcomes from their ML models.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.