Multi-Agent orchestration with Apache Airflow®, Apache Kafka®, Aryn AI, and OpenAI
14 min read |
Or: How I am coping while waiting for the next season of Severance (don’t worry, no spoilers in this post!).
How many AI agents do you have running right now?
In 2022 I started to use Airflow to orchestrate singular queries to LLMs to automate writing first drafts for support ticket responses, and built my first RAG (retrieval augmented generation) pipelines to engineer more context to get actually usable output. Over time, I have moved on to using agents, both to write Airflow Dags (using coding agents like the one available in the Astro IDE and inside of my pipelines replacing plain LLMs.
Everyone who uses AI quickly wants more. AI agents that work together and exchange information, a robust pipeline with retries and alerts, an event-driven schedule…. In short: you want the robots to do as much work for you as they can, while you are focusing on the creative and enjoyable parts of your job and life, like writing your next book.
With recent leaps in AI readiness in Airflow 3.1, the time is finally here to achieve exactly that: creating multi-agent pipelines with human-in-the-loop steps for critical and final reviews, all interconnected with your existing Airflow setup.
You can use Airflow to:
- Automate sales outreach, having agents generate targeted emails and call scripts, validated by a human in the loop.
- Create and localize product copy in bulk.
- Create customer facing data products like personalized app usage reports.
- Process product feedback and generate sophisticated feature suggestions, including prototype mockups.
- Refine macro data and draft new optics and designs.

Figure 1: A screenshot of the multi-agent Dag showing a successful run orchestrating 10 AI agents.
For my test, I decided I did not want to wait until season 3 drops for a new Severance episode, so I created a pipeline that orchestrates agents to write one for me and my outie.
The result was a pipeline combining some of my favorite data tools, including Pydantic AI Agents, Apache Kafka, Aryn AI, and Weaviate with the newest Airflow features like event-driven scheduling and human-in-the-loop.
This blog post constitutes a deep dive of a pipeline that orchestrates 10 specialized AI agents working together, some of which use a custom tool made possible by a RAG pipeline running in the same Airflow environment.
Architecture overview
Each of the agents in the pipeline is provided with a tailored prompt narrowing its scope of work. For example, a series_analyst_agent researches themes and patterns in Severance, while a continuity_callbacks_agent identifies possible easter eggs; the title_generator_agent creates a list of potential titles and finally the script_synthesis_agent pulls it all together. I also gave these agents access to a RAG tool, connecting to a vector database filled with context for them to work with.
Every agent plays but a small part doing important and mysterious work.
Finally, a human is asked for input twice during the Dag run, once to approve or override the output of a specific agent (the title_generator_agent) and once at the end to approve the final asset… or tell the Dag to try again.
Of course you can adapt this structure to create anything you can imagine, for example to brainstorm product ideas. The use case is just a question of changing the prompts and the data ingested into the vector database.
This end-to-end pipeline showcases many of the features Airflow has to offer alongside some of the best tools you can use together with Airflow as a template for your next AI pipeline. It includes:
- Creating a RAG pipeline and tool using dynamic task mapping, Aryn AI, and Weaviate
- Writing a Dag that orchestrates 10 agents with the Airflow AI SDK and includes 2 human-in-the-loop steps created with human-in-the-loop operators
- Scheduling the Dag using event-driven scheduling based on messages in a Kafka message queue
You can find the full pipeline code on GitHub in this repository and further information on how to implement the Airflow features shown in this example pipeline, from human-in-the-loop to using the Airflow AI SDK in our Orchestrate LLMs and Agents with Apache Airflow eBook.
Creating a RAG pipeline and agent tool
The first step of creating any AI application is to orchestrate the context. Without it, you are just writing another LLM-wrapper that can be recreated in a day. I decided that the best way to get more accurate scripts for Severance would be to make sure the agents have access to previous scripts of the series via a tool using RAG.
To fill the vector database needed for RAG, I need to extract information from an input (documents containing the scripts), transform that data, and then load it into a vector database. This is accomplished by the 5-task Dag shown in Figure 2.

Figure 2: The RAG Dag processing files and loading them into the vector database to be accessed by the agent tool.
Aryn for document parsing
Luckily the scripts for Severance, my test series, are freely available online. But between the scripts in .html and .txt format and other documents about the series as PDFs I really needed a quick and easy to implement way to ingest all of them into my vector database.
For this use case I chose Aryn DocParse, an agentic document parser. It was my first time using the tool and I was very happy to learn that you can parse and partition different file formats in one and the same function shown in the below code snippet.
def parse_files_with_aryn(file: str) -> str:
from aryn_sdk.partition import partition_file
from airflow.sdk import get_current_context
context = get_current_context()
context["file_processed"] = file
print(f"Processing file: {file}")
with open(file, "rb") as f:
data = partition_file(f) # This function parses and partitions html, txt and PDF data in my pipeline and returns a structured JSON
return dataTurning this function into an Airflow task is trivial using the @task decorator. I decided to maximize efficiency and robustness by creating an individual task instance for each file that is being parsed with dynamic task mapping. Each task instance gets 3 retries in case of any fleeting issues and if one file is corrupted it will not stop the pipeline. Additionally, using the map_index_template parameter, I can see which file is being parsed by which dynamic instance at a glance in the Airflow UI (see Figure 3 after the next code snippet).
The code snippet below shows the setup of how to dynamically map document parsing by Aryn with Airflow. The upstream task (list_files) creates a list of all files that need to be parsed and calls the task function with .expand causes Airflow to create one copy of the parse_files_with_aryn task per file that is processed.
@task
def list_files() -> list:
import os
files = [f"{DOCUMENTS_FOLDER}/{f}" for f in os.listdir(DOCUMENTS_FOLDER)]
return files
_list_files = list_files()
@task(
max_active_tis_per_dag=2, retries=3, map_index_template="{{ file_processed }}"
)
def parse_files_with_aryn(file: str) -> str:
from aryn_sdk.partition import partition_file
from airflow.sdk import get_current_context
context = get_current_context()
context["file_processed"] = file
print(f"Processing file: {file}")
with open(file, "rb") as f:
data = partition_file(f)
return data
_parse_files_with_aryn = parse_files_with_aryn.expand(file=_list_files)Clicking on the task in the Airflow grid view, you can see a list of all dynamically mapped task instances. In the Dag run shown in Figure 3, 20 files were parsed.

Figure 3: A screenshot of the Airflow UI showing dynamically mapped task instances of the Aryn task with the Map Index displaying the file they are processing.
The structured JSON returned by Aryn gets formatted by a downstream helper task to make sure data is ready for vector database ingestion.
Weaviate for vector storage
With Weaviate as your vector database, you can use the WeaviateHook from the Airflow Weaviate provider package to instantiate your client based on credentials stored within Airflow as a connection. The last task in the RAG Dag passes the text chunks created by Aryn from all sorts of file inputs to Weaviate which handles the embedding process via OpenAI. I just needed to provide my OpenAI key.
The below code snippet shows the full load task using collection.data.insert_many to bulk insert text chunks into Weaviate.
@task(trigger_rule="all_done")
def load_embeddings_to_vector_db(data: list) -> None:
from airflow.providers.weaviate.hooks.weaviate import WeaviateHook
from weaviate.classes.data import DataObject
from weaviate.util import generate_uuid5
import json
hook = WeaviateHook(CONN_ID)
client = hook.get_conn()
collection = client.collections.get(COLLECTION_NAME)
all_documents = []
for document in data:
if isinstance(document, str):
for chunk in json.loads(document):
all_documents.append(
DataObject(
properties=chunk,
uuid=generate_uuid5(chunk),
)
)
collection.data.insert_many(all_documents)
_load_embeddings_to_vector_db = load_embeddings_to_vector_db(
data=_format_data_for_ingestion,
)The RAG tool
Of course I immediately wanted to test whether my data was stored correctly, so I wrote a small helper dag to directly query for any lines in Severance relating to the term “goat”. I was pleased with the output, shown in the code snippet below (redacted to avoid spoilers).
[2025-10-30 19:48:39] INFO - {'content': '00:36:47 Goat [REDACTED]'} source=task.stdout
[2025-10-30 19:48:39] INFO - {'content': '00:39:37 [REDACTED] goats [REDACTED]'} source=task.stdout
[2025-10-30 19:48:39] INFO - {'content': '00:49:30 Baby Goat: [bleating]'} source=task.stdout
[2025-10-30 19:48:39] INFO - {'content': '00:13:56 [REDACTED] actual goats. [REDACTED]'} source=task.stdout
[2025-10-30 19:48:39] INFO - {'content': '00:17:06 [REDACTED] baby goats?'} source=task.stdoutA human can query the vector database, let’s give this ability to our agents as well! The code block below shows the search_series_scripts tool that I created using the same WeaviateHook and Airflow connection ID to help my agents connect to Weaviate to get lines of real Severance scripts.
This is one of the great advantages of standardizing on Airflow: you can reuse connections and code across your data engineering (RAG) and AI engineering (agentic) pipelines!
import random
import time
def search_series_scripts(query: str, limit: int = 10) -> dict:
"""
... docstring ...
"""
from airflow.providers.weaviate.hooks.weaviate import WeaviateHook
COLLECTION_NAME = "SERIES_DB"
CONN_ID = "weaviate_default"
if limit > 10: # let's limit the robots a bit
limit = 10
print(f"Using search_series_scripts tool with query: {query} and limit: {limit}")
try:
hook = WeaviateHook(CONN_ID)
client = hook.get_conn()
collection = client.collections.get(COLLECTION_NAME)
print("Weaviate search running")
results = collection.query.near_text(
query=query,
limit=limit,
)
client.close()
print(f"Weaviate search results: {results}")
search_results = {
"query": query,
"num_results": len(results.objects),
"results": [],
}
for idx, result in enumerate(results.objects, 1):
search_results["results"].append(
{
"rank": idx,
"content": result.properties.get("content", ""),
"relevance_note": f"Result {idx} of {len(results.objects)}",
}
)
return str(search_results)
except Exception as e:
return {
"query": query,
"error": f"Failed to search database: {str(e)}",
"num_results": 0,
"results": [],
}
Work, robots, work! The agentic Dag
The tool is ready, let’s orchestrate some agents!
The easiest way to do so is by using the @task.agent decorator from the Airflow AI SDK, an open-source package developed by Astronomer. This package is built on top of Pydantic AI, which means it is compatible with many Pydantic agents and features such as defining structured output classes. You can instantiate your agent with a model (I am using gpt-4o-mini) and system prompt alongside a list of tools that the agent has access to.
The code snippet below shows one of my 10 agents, focused on writing character dialogue in the generated episode. This agent has access to the tool search_series_scripts created by the RAG pipelines explained previously and a prebuilt tool, Pydantic’s duckduckgo search. The full system prompt can be found in the companion GitHub repository.
# from pydantic_ai import Agent
# from pydantic_ai.common_tools.duckduckgo import duckduckgo_search_tool
character_writer_agent = Agent(
"gpt-4o-mini",
system_prompt=tv_prompts.TV_CHARACTER_WRITER_PROMPT,
tools=[
tv_tools.search_series_scripts,
duckduckgo_search_tool(),
],
)Running this Agent as an Airflow task is just a question of using the @task.agent decorator from the Airflow AI SDK on a regular Python function and providing the character_writer_agent to the agent parameter. The return value of the decorated function is passed to the agent as the user prompt.
In the task shown in the code snippet below, the character_writer_agent is given context based on the output of previous agents, including an analysis of the series created by a research agent and the preliminary structure of the episode’s story created by a writer agent.
from airflow.sdk import dag, task
# ...
@dag(...)
def tv_episode_script_generator():
# ...
@task.agent(agent=agents.character_writer_agent)
def develop_character_moments(
series_analysis: str,
story_structure: str,
series_context: str,
) -> str:
context_data = json.loads(series_context)
return (
f"Series: {context_data['series_name']}\n\n"
f"Series Analysis:\n{series_analysis}\n\n"
f"Story Structure:\n{story_structure}"
)The dependencies between the tasks orchestrating the agents are largely inferred from the outputs passed between the functions. Any additional dependencies between tasks can be defined using the chain function.
# from airflow.sdk import chain
# implicit depdenceny setting by passing the output of tasks to the next task
character_moments_result = develop_character_moments(
series_analysis_result,
story_structure_result,
_process_input,
)
# explicit dependency setting with chain()
chain(_generate_episode_title, _human_title_review, final_script_result)Zooming in on our 10 agentic tasks you can see how they depend on each-others output (Figure 4).
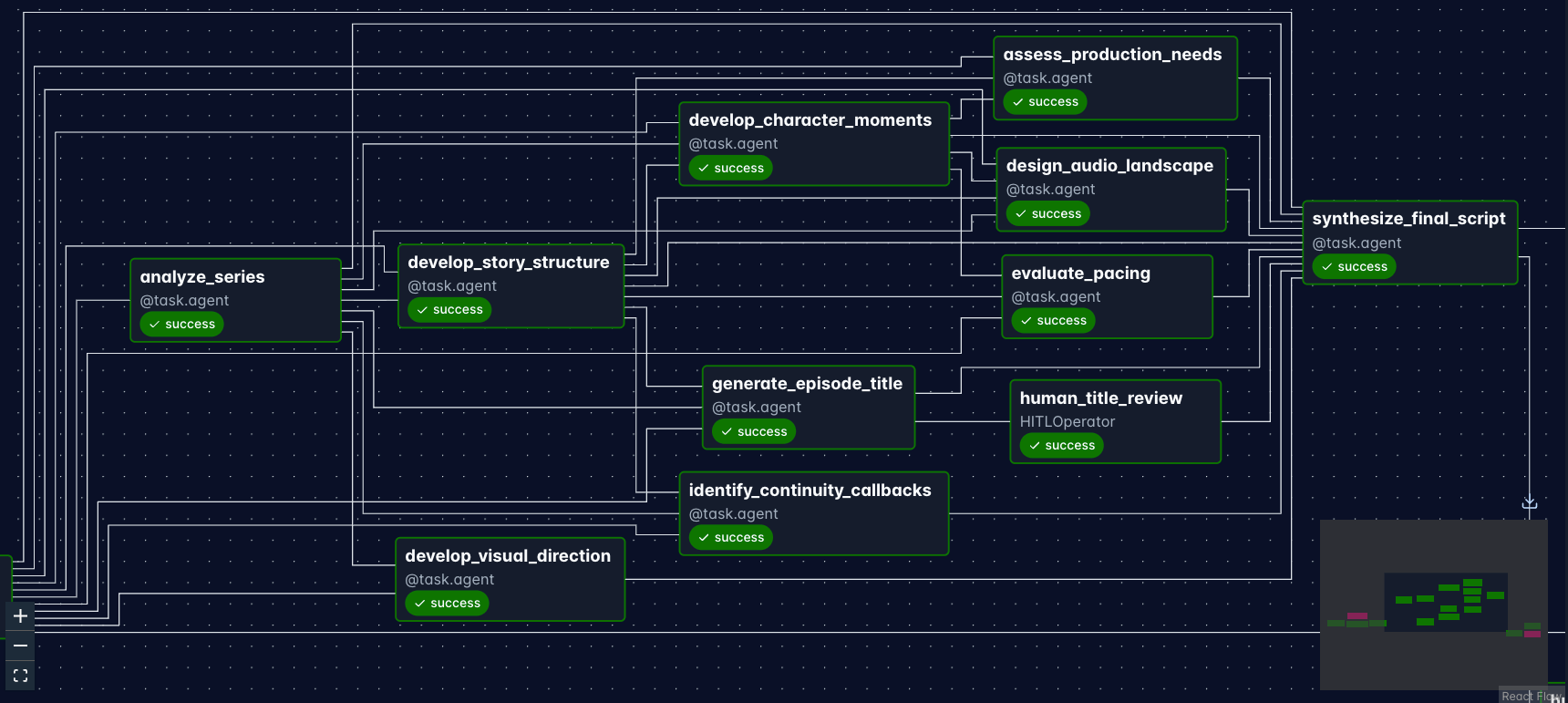
Figure 4: Part of the multi-agent Dag that includes the 10 tasks created with @task.agent.
Another great benefit of using Airflow for AI pipelines is that agents can run in parallel as soon as all upstream tasks have completed successfully, as shown in the Gantt chart of one run of this pipeline (Figure 5).

Figure 5: Gantt chart of one run of the multi-agent Dag showing how long each task was taking and several tasks running in parallel.
Human-in-the-loop verification
AI is amazing, but sometimes it does not know everything (yet); humans are still needed to double check outputs and provide additional information. For this reason, Airflow 3.1 introduced human-in-the-loop operators, a straightforward way to add human decision and input steps into your Airflow Dags.
In this pipeline I added two human-in-the-loop steps:
- After the
title_generator_agenthas come up with a list of potential episode titles, I want a human to either approve that list or provide an alternative title manually. - After the final episode script is ready, a human should decide if it is good enough or if the Dag should run again.
The second human-in-the-loop step is a branching decision in the Dag based on human input, exactly what the HITLBranchOperator was made for!
The code snippet below shows how the human decision step is defined: the full script is pulled from the output of the synthesizer agent (via XCom). And the human has 5 minutes to decide whether to Approve the script or tell the Dag to try again. If no decision is made within the allotted execution_timeout the defaults are executed.
_human_approve_script = HITLBranchOperator(
task_id="human_approve_script",
subject="Script Approval Required",
body="{{ ti.xcom_pull(task_ids='synthesize_final_script') }}",
options=["Approve Script", "Try Again!"],
defaults=["Approve Script"],
options_mapping={
"Approve Script": "finalize_script_output",
"Try Again!": "try_again",
},
multiple=False,
execution_timeout=timedelta(minutes=5),
)Whenever a human-in-the-loop operator is used, the Dag defers the task and waits for human input via the Airflow UI or the Airflow REST API. Figure 6 shows the UI interface where the human can add additional info using parameters and select any of the predefined options.
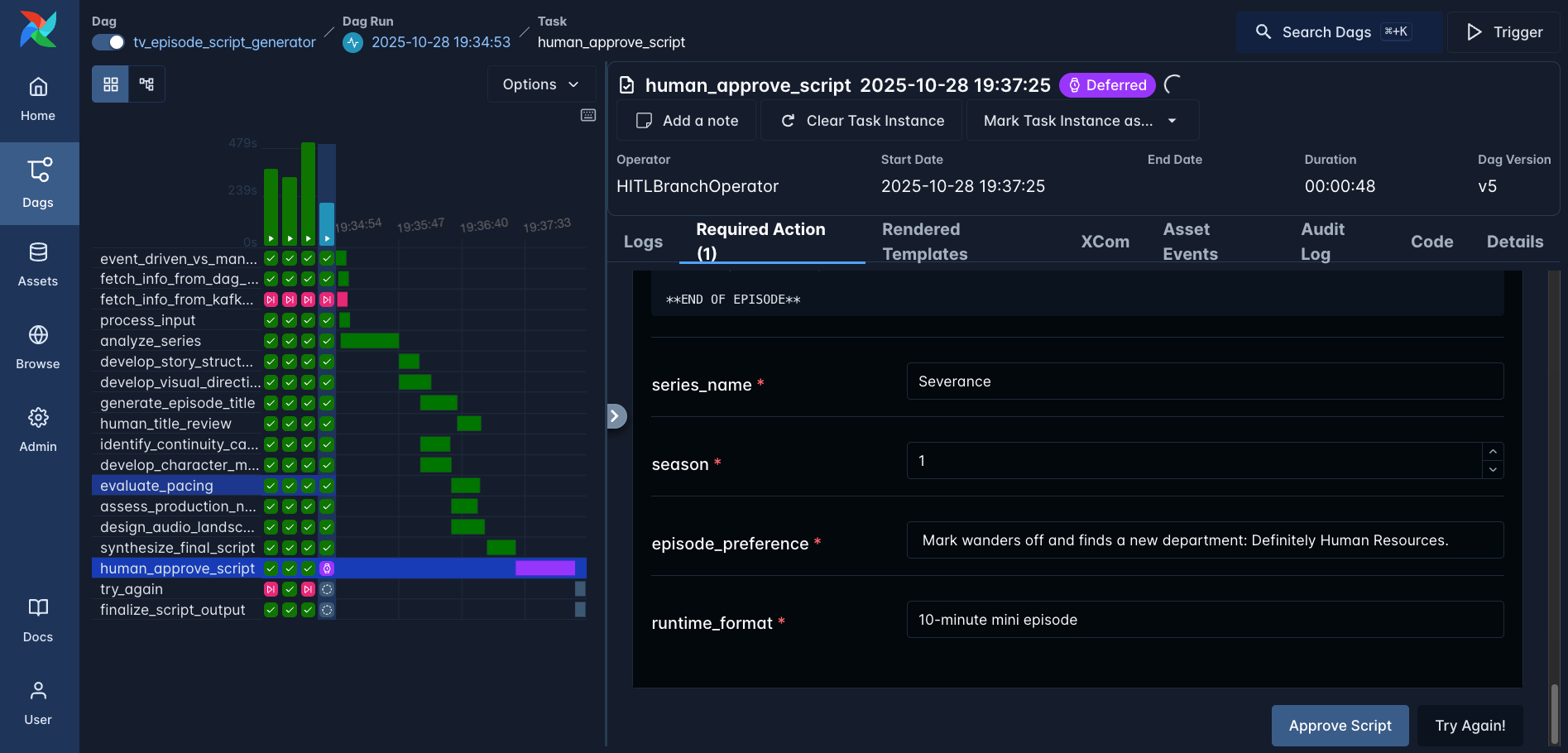
Figure 6: The Dag run waiting for human approval - or rejection of the new Severance script.
Of course our agents did a tremendous job and we can happily approve the script. Based on that decision, the downstream finalize_script_output task is executed and try_again is skipped.
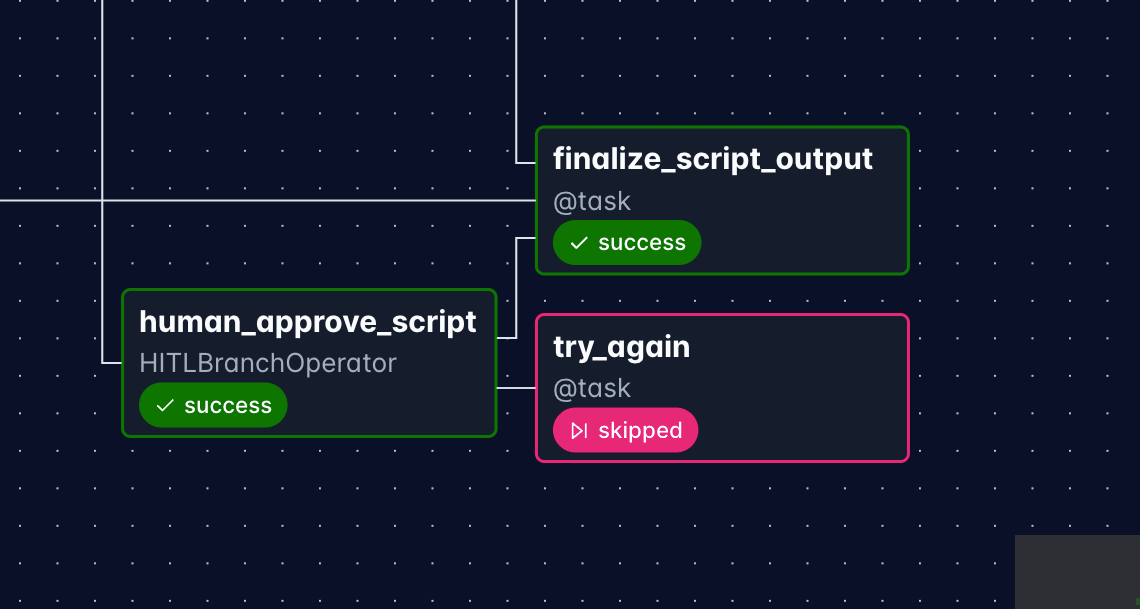
Event-driven scheduling with Apache Kafka
Last but not least, running this Dag manually or on a time-based schedule is ok, but what would be really neat if it was on-demand. You can’t schedule the need for more Severance content.
Airflow has an answer to this as well: event-driven scheduling based on messages in a message queue. The code below shows the implementation in the companion repo that runs the Dag as soon as a message is posted to a topic in Apache Kafka. Not only that, but the message itself turns into the input to the first AI agent of the pipeline, meaning you can implement this Dag as the backend of a real AI application with any frontend.
KAFKA_URI = "kafka://localhost:9092/tv_episode_request_topic"
APPLY_FUNCTION = "dags.tv_episode_script_dag.apply_function"
def apply_function(*args, **kwargs):
message = args[-1]
val = json.loads(message.value())
print(f"Value in message is {val}")
return val
trigger = MessageQueueTrigger(
queue=KAFKA_URI,
apply_function=APPLY_FUNCTION,
)
kafka_topic_asset = Asset(
"kafka_topic_asset",
watchers=[AssetWatcher(name="kafka_watcher", trigger=trigger)],
)
@dag(
schedule=[kafka_topic_asset, Asset("start_over_asset")],
# ...
)Next steps
Congratulations! You now know why Apache Airflow is the perfect orchestration tool for complex multi-agent pipelines. Not just to generate scripts for a TV series, but for any workflow that includes one or more agents (and the occasional human). You equally enjoyed learning about:
- Creating a custom tool for your agents with a RAG pipeline.
- Orchestrating complex interaction between 10 specialized agents.
- Adding human-in-the-loop steps to check your agent’s work.
- Scheduling a Dag to run based on messages in a message queue.
As a reminder the full code is available in this GitHub repository. It spins up with a local Weaviate instance, you only need to add your OpenAI API Key and Aryn AI API key. Go ahead and build something awesome!
Additional resources:

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.