Investigate Every Pipeline Failure Automatically With Otto
8 min read |
Pipeline failures are a fact of life for data teams. Every team deals with them, and every team knows the cost: a missed SLA, a delayed report, a cascading failure that starts small and spreads fast. The question is never whether a failure will happen, it's how quickly you can find the cause and get pipelines back to green.
Last month we introduced Otto, Astronomer’s data engineering agent, built to accelerate the work data engineers actually do: writing Dags, helping with Airflow upgrades, investigating pipeline failures, and more.
Today, Otto's investigation capability extends to automatic, event-driven investigations. When a critical Dag fails, Otto investigates before anyone on your team takes action. By the time your team looks at the alert, Otto has already traced the failure, assessed the impact, and surfaced a fix; you can start the day reviewing a diagnosis, not building one. That's the difference between MTTR measured in hours and MTTR measured in minutes.
Orchestration is where investigations start
Every data issue has an origin. A stale dashboard, a missing report, an alert from a downstream system — these are all symptoms, but the failure itself happened upstream, in the pipelines that feed them. Airflow always sees it first.
This isn't just a matter of timing. The orchestration layer is uniquely positioned to explain what happened, in ways no other tool in your stack can match.
Airflow already has everything needed to investigate a failure as a byproduct of scheduling: task logs, task durations, connection metadata, run history, and execution context. There's no additional agent to install, no per-tool observability setup required. When a Dag fails, the evidence is already there.
Beyond that, a single Dag often touches multiple systems: a warehouse, an API, a transformation tool, a file store. The orchestration layer is the only place where the full execution path is represented in one place. That's what makes it possible to determine whether a failure is a data issue, an infrastructure issue, or a code issue, without stitching together logs from multiple systems.
The orchestrator also knows what's downstream: which SLAs are at risk, which consumers are blocked. That turns diagnosis from "what broke" into "what broke and who cares," which is what on-call teams actually need. And because run history lives at the orchestration layer, a failing run can be compared against the last N successful runs at the same layer, same task, same schedule, same connections, without bouncing between tools.
That's the position Otto operates from. An agent that lives at the orchestration layer doesn't have to piece together what happened from external APIs or secondary logs. It already has access to the environment where the failure occurred, and that's what makes the diagnosis trustworthy rather than speculative.
The context no other agent has
Every on-call engineer starts with the same question: is this my code, or is it the platform? Answering it requires context most agents can't reach.
Otto has access to those signals. But access alone isn't the differentiator. What makes Otto's investigations trustworthy is the combination of infrastructure context and operational expertise: eight years of Astronomer running Airflow at scale across hundreds of enterprise deployments, encoded into the agent. Otto knows what healthy task execution looks like and recognizes how common failure modes present across the orchestration layer.
Take infrastructure failures as an example. A worker that lost its heartbeat or a pod that crashed on the Kubernetes side won't produce a clean error in the Airflow UI. Diagnosing it means getting into scheduler and worker component logs that aren't accessible through any external API. For most teams, that means a support ticket and a one to two day wait. Otto surfaces that context automatically, without the ticket.
The result is a structured diagnosis that covers not just what failed, but what didn't, including Dag and task-level checks tracking the pipeline's full execution path. No homegrown monitoring solution or general-purpose agent carries that operational depth. For teams spread across time zones, that shared diagnostic record means less time gathering signals and a measurable reduction in MTTR.
Otto as your team's first line of defense
For data teams, by the time someone opens their laptop, the damage from an overnight failure has often already spread. SLAs are missed, downstream consumers are blocked, and reports that were supposed to be ready at market open, aren't. For these failures, ad-hoc investigation, triggered after someone notices something is wrong, isn't enough.
Automatic investigation changes that. Otto now triggers an investigation the moment a critical Dag fails, before anyone is paged. Results can be programmatically routed to your Slack channel, email, or used to kick off additional agents downstream. The diagnosis is waiting by the time the on-call engineer looks at their screen. 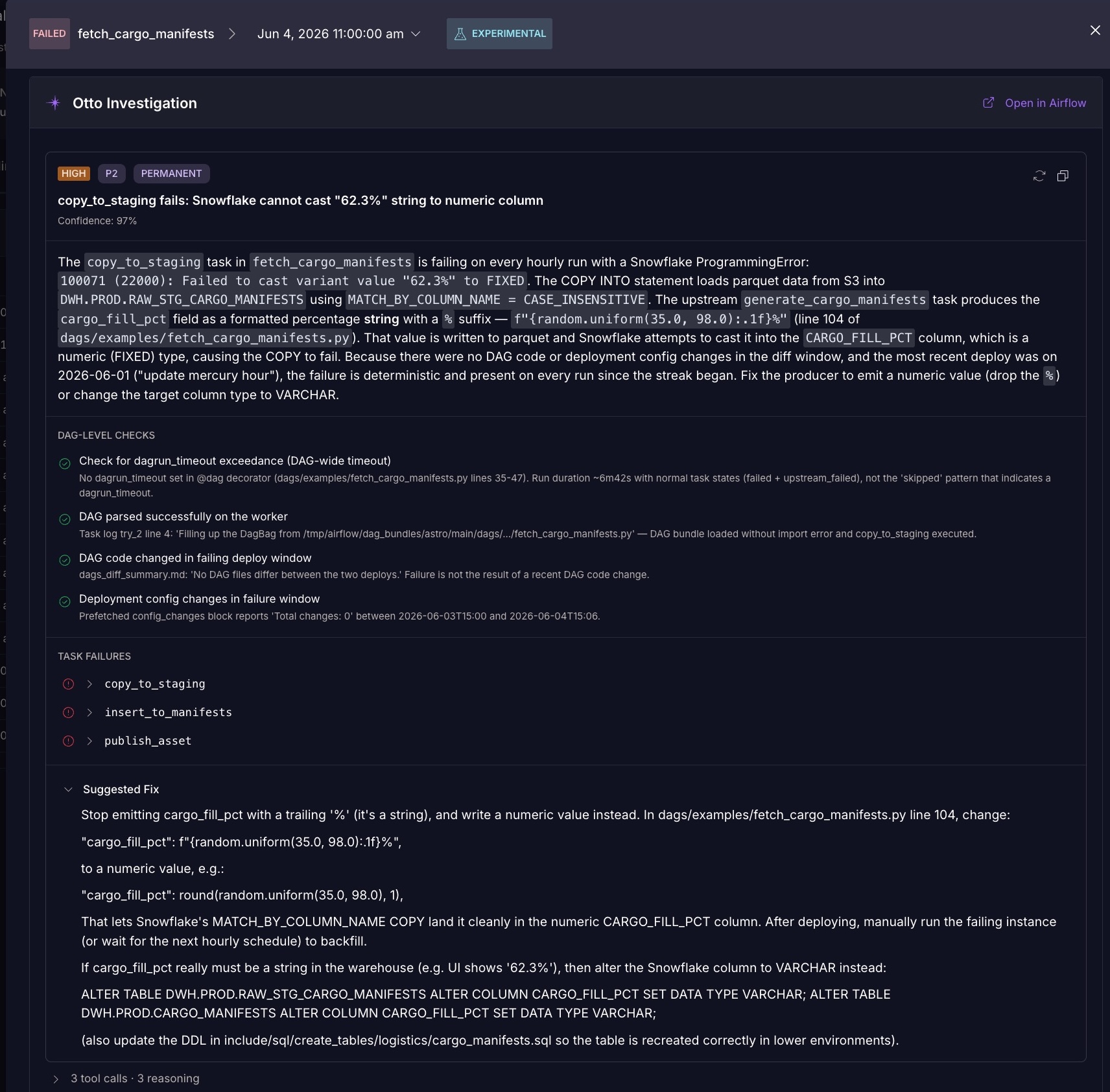
Here's what that looks like in practice. A pipeline fails at 3 AM. The on-call engineer gets paged, but Otto's diagnosis is already in Slack. By the time they open their laptop, the root cause is identified, the blast radius is mapped, and a suggested fix is ready. Instead of spending the next hour reading logs and tracing dependencies, they spend 20 minutes reviewing Otto's findings, applying the fix, and going back to sleep. MTTR drops from hours to minutes, without adding headcount or on-call burden.
Otto in the terminal remains available for live debugging and real-time iteration: run astro otto, describe the failure, and Otto walks you through the diagnosis conversationally, with the ability to apply fixes to your code in the same session. Automatic and conversational investigation work together and Otto now covers both.
Otto’s investigation API makes this composable. Teams can trigger investigations programmatically against any Dag failure, integrate the output into existing incident management workflows, and build automated remediation pipelines on top of structured, machine-readable results. What comes back is structured: a categorized root cause type (code error, connection failure, resource limit, timeout, and more), a severity and priority rating, a confidence score with supporting evidence, a blast radius showing affected Dags, tasks, and downstream consumers, and a suggested fix with actionable remediation steps.
Teams are already building on it: routing failures to specialized handlers based on root cause type, auto-creating ServiceNow incidents pre-populated with diagnosis and severity, auto-closing those incidents when a Dag retries successfully. For teams managing hundreds of failures per day, you don't click into every failure. You route, prioritize, and act on structured signal. Teams can also customize how Otto investigates at the workspace or deployment level, encoding operational context like maintenance windows, known flaky upstreams, or escalation paths directly into the agent's reasoning.
Expertise that's available regardless of who's on call
Pipeline expertise tends to concentrate; there's usually one engineer who knows why a specific integration fails in a specific way, which deployment events correlate with which failure patterns, and what to check first when something goes wrong at 3 AM. When that person is unavailable, everyone else starts from scratch — escalating, waiting for a handoff, or spending hours retracing steps the senior engineer would have resolved in minutes.
Otto surfaces the same evidence a senior engineer would pull, traces the same dependency chains, and produces the same structured handoff they'd write before escalating, regardless of who's on call. The investigation output, along with intermediate evidence gathered, is stored in Astro for other teammates to reference, or for the team to revisit when they see the same failure in the future.
"Our pipeline expertise is concentrated in a small team, so when the primary on-call engineer isn't available, handoffs used to mean a lot of back-and-forth to get someone up to speed. Otto's investigation feature changes that. It runs the triage and hands off a comprehensive picture of what went wrong and why, so whoever is covering has access to the best information to discern what to do next. It saves a lot of time in the investigation and means the right context is always there, regardless of who's on call." — Christopher Russell, Data Reliability Specialist, Descartes Systems Group
Where this is going
Automatic investigation is the foundation. The structured output Otto produces (root cause type, severity, blast radius, suggested fix) is designed to be acted on, not just read. Teams are already wiring it into remediation workflows: root cause routes to a handler, the handler proposes a fix, a human reviews, the fix deploys.
This is where orchestration-native intelligence leads: self-healing pipelines. When Otto automatically classifies every failure, scores its severity, and pairs it with a suggested fix, the remediation path becomes programmable. MTTR drops from hours to minutes — not because engineers work faster, but because they start from a diagnosis instead of a blank screen consistently, regardless of the hour or who's on call.
The same infrastructure-depth context that makes Otto's diagnosis trustworthy makes automated remediation possible. You can start building self-healing pipelines today — call the Investigation API, route on structured output, and close the loop with your own automation.
Automatic investigations are available as a part of Otto for all Astro customers. Get started here →
To see it in action or talk through deployment for your team, book a demo →

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.