Introducing Airflow 2.7
9 min read |
Apache Airflow® is constantly evolving to meet the ever-changing needs of the data ecosystem. Airflow 2.7 was released this week, continuing the streak of minor releases with great new features every couple of months. This release contains more than 35 new features, over 45 improvements, and over 50 bug fixes, highlighted by the much-anticipated new feature: automatic setup/teardown tasks.
Many of the features and improvements in 2.7 center around elevating the experiences of supporting resource management, DAG testing, and monitoring. These are aspects that will be beneficial to nearly everybody working with Airflow. This blog post will walk you through everything you need to know about this release, so you don’t miss any of the exciting additions and changes.
Automatic setup/teardown tasks
The headline feature in Airflow 2.7 is setup/teardown tasks (AIP 52, for those who track the project closely). Many workflows require creating a resource, using that resource to do some work, and then tearing that resource down. While this pattern sounds simple, prior to Airflow 2.7 it needed to be implemented manually, which could be quite difficult. This resulted in many teams leaving resources running constantly, wasting money and energy. Now, setup/teardown tasks support implementing this pattern automatically as a first class feature, making it much easier to run efficient pipelines.
Any Airflow task can become a setup or teardown task, with other tasks being associated with it (or “in scope”). But once a task is designated as a setup or teardown, the task will behave differently from a regular task. Key features of setup/teardown tasks include:
- If you clear a work task, its setup and teardown tasks will also be cleared.
- By default, teardown tasks are ignored when evaluating DAG run state (i.e. if only your teardown task fails, your DAG run will still succeed).
- A teardown task will run if its setup task was successful, even if work tasks failed.
This translates to a “smart” implementation of resource management within your DAGs, reducing resource consumption and cost, and saving time on resource management.
The use cases relevant to setup/teardown tasks are numerous. Many workflows across industries and disciplines need to follow this type of pattern. A couple very common use cases that will be made easier and simpler by setup/teardown tasks include:
- Data quality testing: Set up the compute resources to run data quality tests (or any other type of tests), and then tear down the resources even if the tests fail.
- ML Orchestration: Set up the compute resources to train models or tune hyperparameters, and tear them down regardless of whether training of that model was successful.
- ETL within Airflow: Set up a bucket in your custom XCom backend to store data passed between tasks, and tear it down at the end of the DAG run to avoid excessive storage costs. (ETL is a common example of this pattern, but this could apply to any time you use XComs).
For simple pipelines, these use cases were possible before setup/teardown tasks by using complex trigger rules, extra cleanup DAGs, or other sometimes tricky workarounds. For more complex pipelines they may have been nearly impossible. Now, it doesn’t even require an extra line of code to get the cost and resource saving benefits of this feature.
Implementation of setup/teardown tasks is easy: mark tasks as setup and teardown, and any tasks between them are in their scope.
create_cluster >> run_query1 >> run_query2 >>
delete_cluster.as_teardown(setups=create_cluster)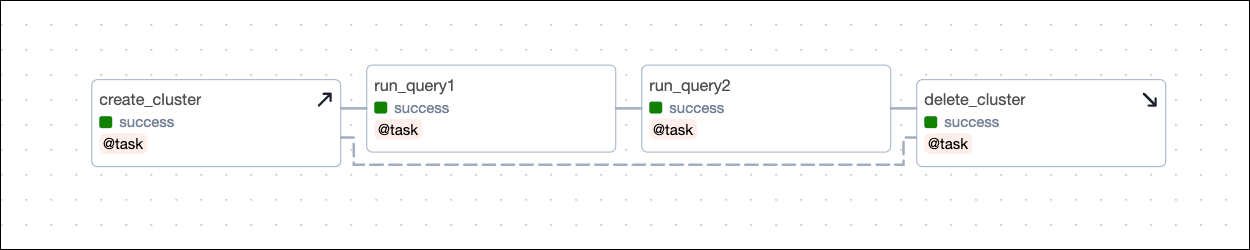
Other cases like having a setup without a teardown, multiple setups with one teardown, nested setup/teardown groupings, etc. are also possible.
For more, see our guide.
Built-in OpenLineage Support
OpenLineage provides a spec standardizing operational lineage collection and distribution across the data ecosystem that projects – open source or proprietary – implement. Publishing operational lineage via an OpenLineage integration has been a core Airflow capability for troubleshooting and governance use cases. Prior to 2.7, OpenLineage metadata emission was only possible via a plugin implementation maintained in the OpenLineage project that depended on Airflow and operators’ internals, making it brittle.
Now, built-in OpenLineage support in Airflow makes publishing operational lineage through the OpenLineage ecosystem easier and more reliable. It has been implemented by moving the openlineage-airflow package from the OpenLineage project to an airflow-openlineage provider in the base Airflow Docker image, where it can be easily enabled by configuration. Also, lineage extraction logic that was included in Extractors in that package has been moved into each corresponding provider package along with unit tests, eliminating the need for Extractors in most cases.
For this purpose, a new optional API for Operators (get_openlineage_facets_on_{start(), complete(ti), failure(ti)}, documented here) can be used. Having the extraction logic in each provider ensures the stability of the lineage contract in each operator and makes adding lineage coverage to custom operators easier.
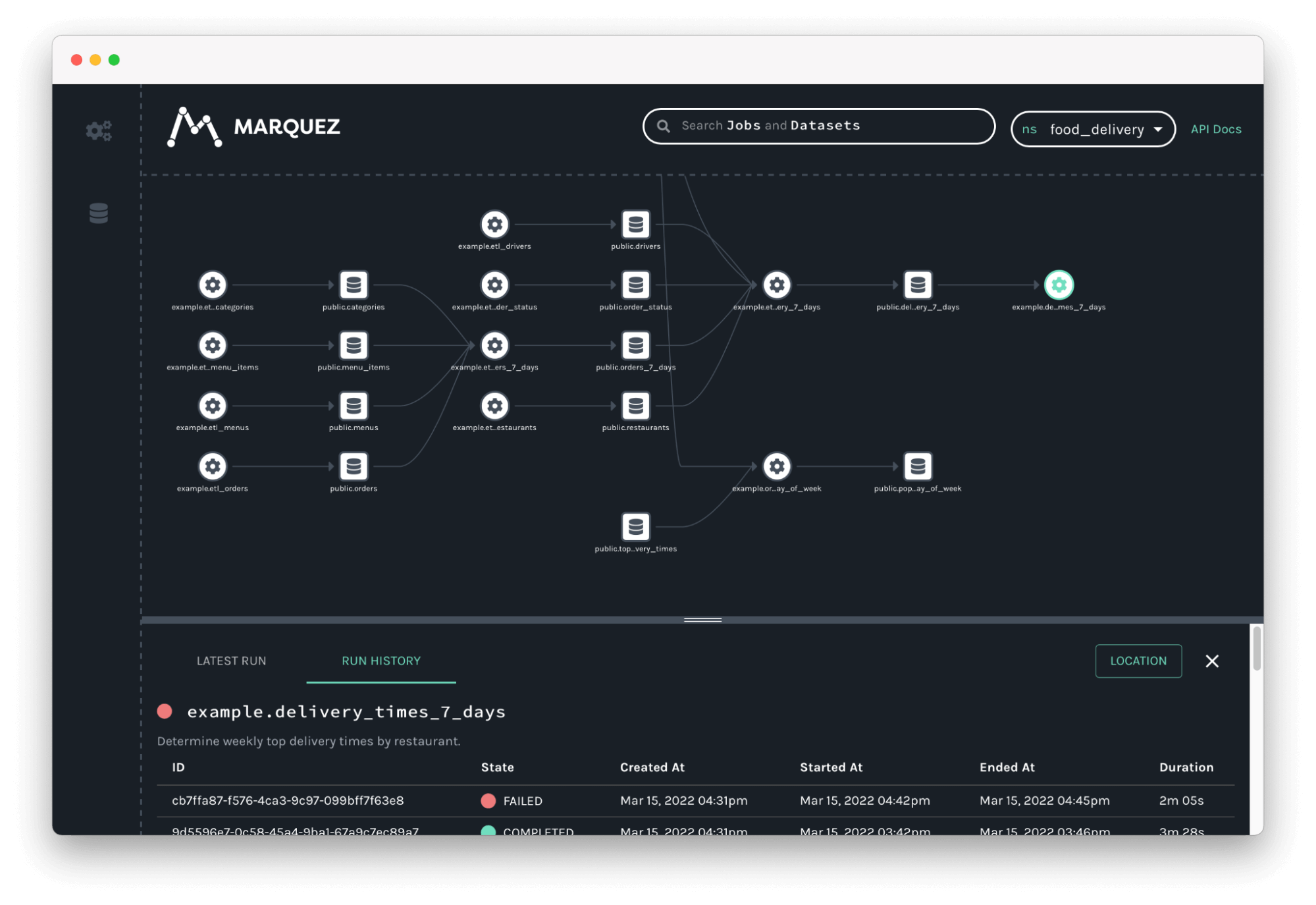
Lineage on view in Marquez, an OpenLineage consumer:
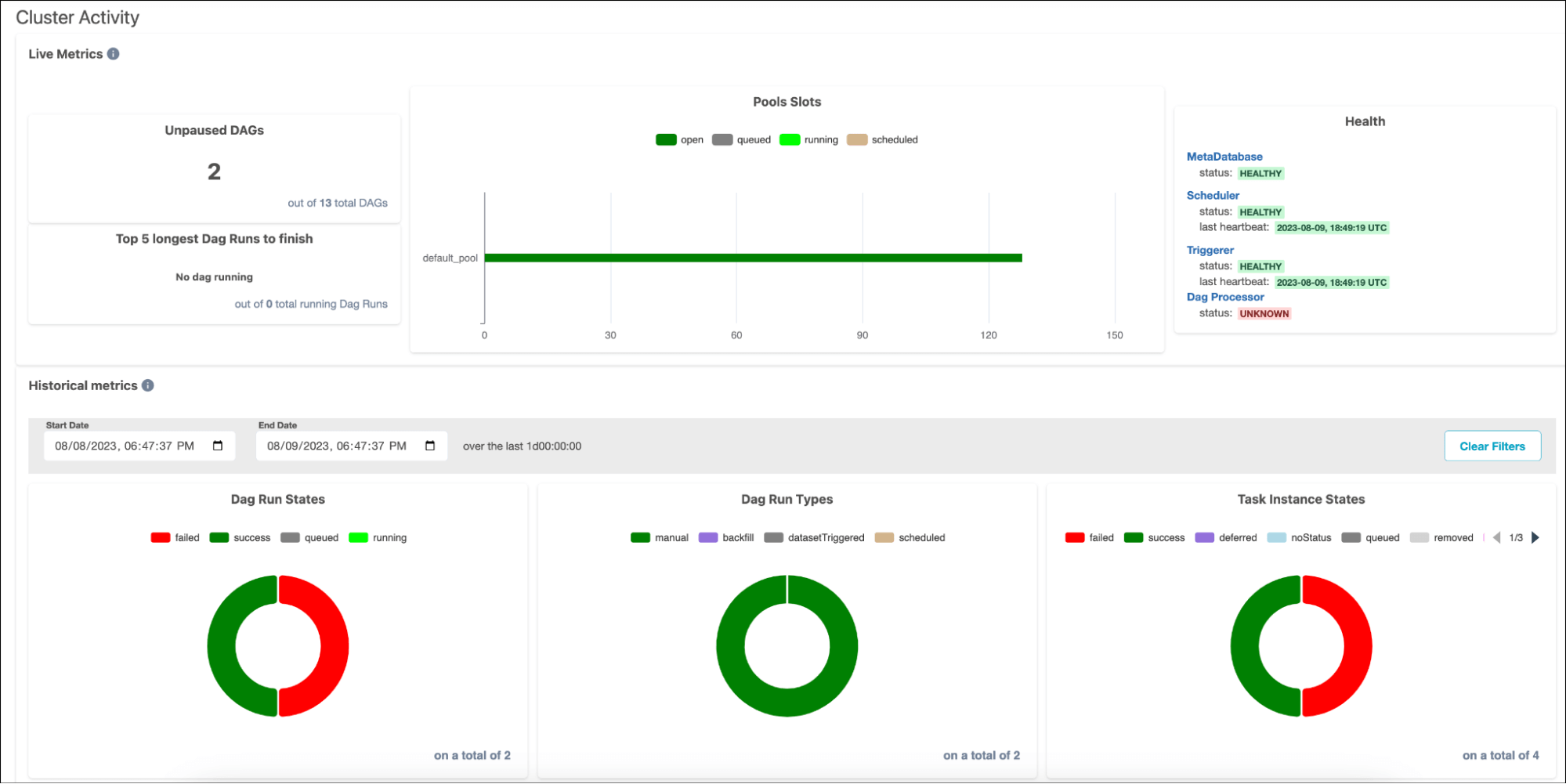
New cluster activity view, and other UI updates
Nearly every Airflow release brings awesome updates to the UI like new views, new functionality, and quality of life improvements, and 2.7 is no exception. One of the most exciting UI changes in this release is the addition of a cluster activity view, which provides useful metrics for monitoring your Airflow cluster. It’s a great one-stop-shop to see everything that’s going on with your DAG runs and task instances (how many are running, failed, scheduled, etc.), as well as the health of your Airflow infrastructure (scheduler status, metadata database status, DAG run times, etc.)
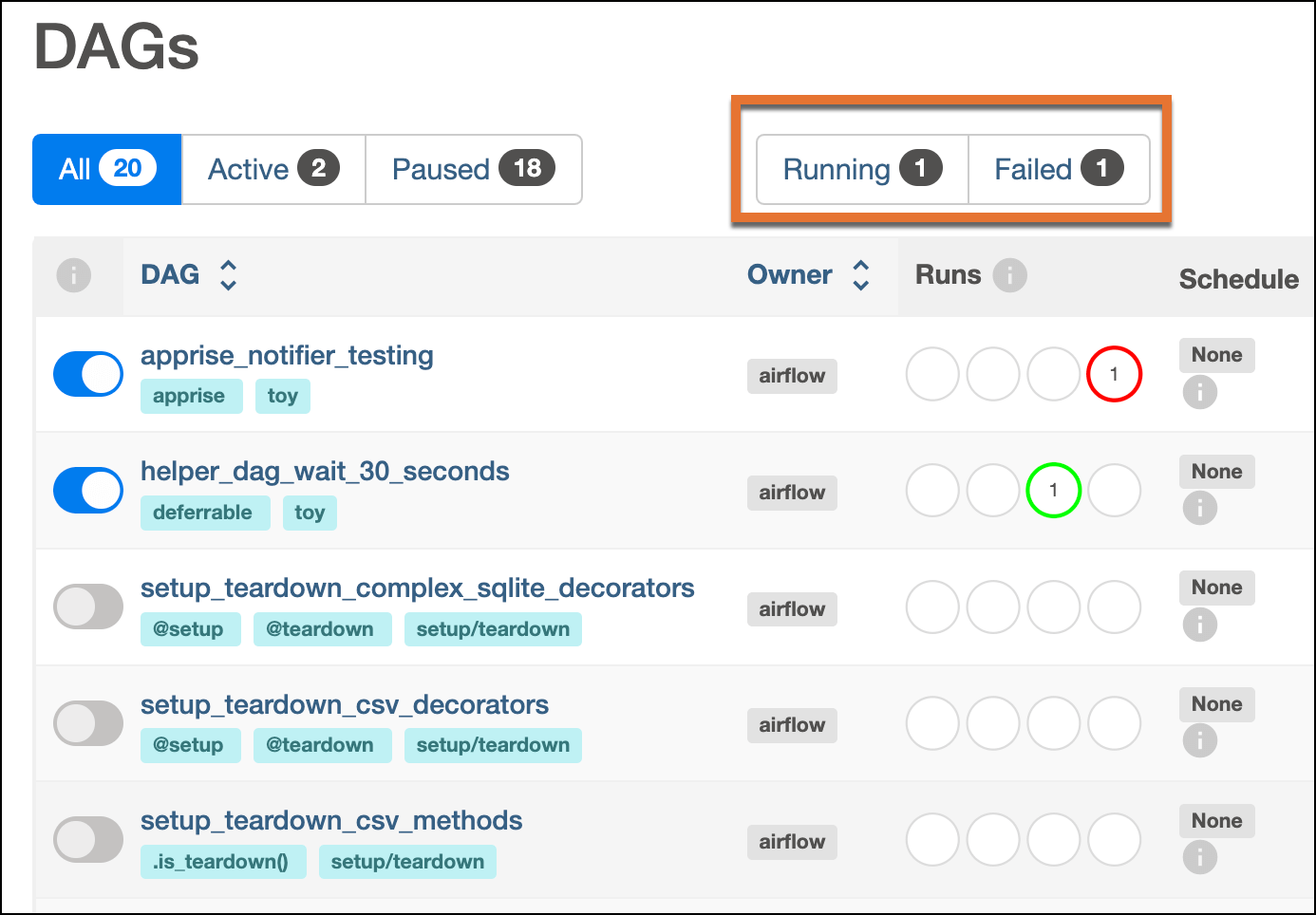
Another useful update for monitoring your DAGs is the addition of running and failed status filters on the DAGs home page. This feature has been requested by many community members who work with large Airflow instances with lots of DAGs. It can be overwhelming to scroll through hundreds or sometimes even thousands of DAGs to find any failures that need addressing, but now you don’t have to. Simply filter to any DAGs that have a currently running DAG run, or where the most recent DAG run has failed.
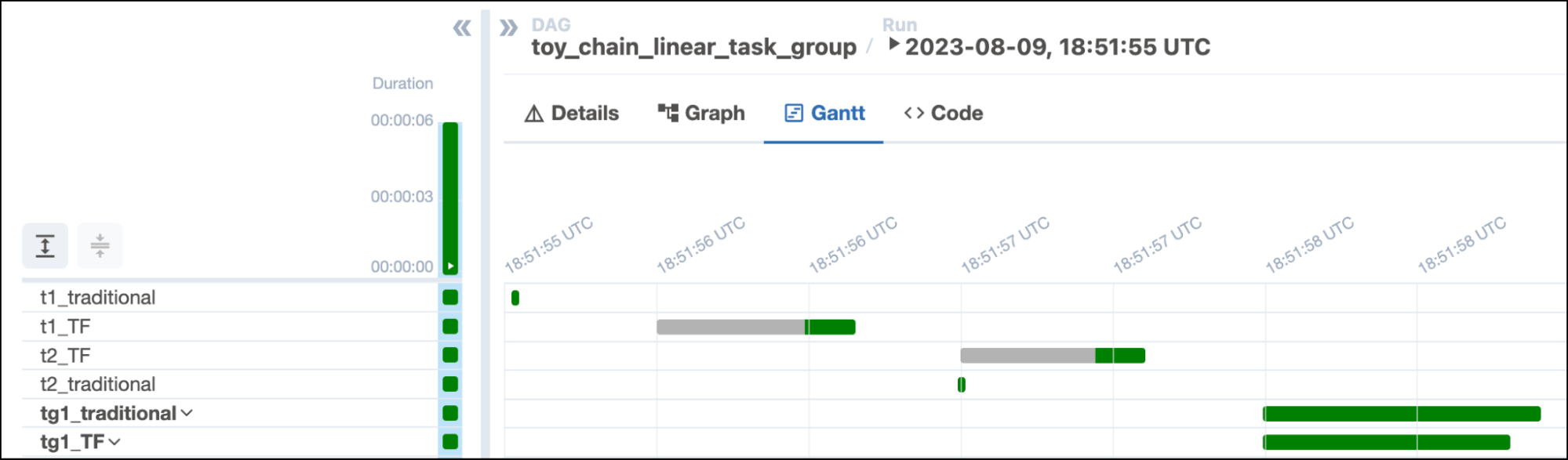
Other cool UI updates include more views getting moved into the Grid View: the Code View and Gantt Views can now be found alongside your DAG grid, giving you more insight in one place and reducing how much you have to click around.
Apprise provider for sending notifications
Speaking of monitoring DAGs, another great addition in 2.7 is the new Apprise provider, which allows you to send notifications to multiple services using the Apprise notifier. Apprise can be used for many different services, including Teams, Twitter, Reddit, and more. So if you need to send notifications to a service that doesn’t already have a specific notifier, this is a great option.
{% raw %}from airflow.decorators import dag, task
from airflow.operators.bash import BashOperator
from airflow.providers.apprise.notifications.apprise import send_apprise_notification
from apprise import NotifyType
from pendulum import datetime
@dag(
dag_id="apprise_notifier_testing",
schedule_interval=None,
start_date=datetime(2023, 8, 1),
catchup=False,
on_failure_callback=[
send_apprise_notification(
apprise_conn_id="apprise_default",
body="The dag {{ dag.dag_id }} failed",
notify_type=NotifyType.FAILURE,
)
],
tags=["apprise", "toy"],
)
def toy_apprise_provider_example():
BashOperator(
task_id="bash_fail",
on_failure_callback=[
send_apprise_notification(
apprise_conn_id="apprise_default",
body="Hi",
notify_type=NotifyType.FAILURE,
)
],
bash_command="fail",
)
BashOperator(
task_id="bash_success",
on_success_callback=[
send_apprise_notification(
apprise_conn_id="apprise_default",
body="Hi",
notify_type=NotifyType.FAILURE,
)
],
bash_command="echo hello",
){% endraw %}To use the Apprise provider, you can simply import the notifier and use it as a callback function. The service you send notifications to is defined by the connection you pass to apprise_conn_id.
Fail-stop feature
A key part of any production-ready orchestration tool is a set of features to help with quickly and easily developing workflows and making them more efficient in production. Effective development features lessen the time to production, and greater efficiency will save time and money once the pipelines are in production. Airflow has a suite of features that help with both of these points that was expanded even further in 2.7 with the addition of a fast-stop option.
The new fail_stop parameter is set at the DAG level. If set to true, when a task fails, any other currently running tasks will also fail. This speeds up DAG development and testing, especially for long-running DAGs, because you can address any failures without waiting for other tasks in the DAG to finish running unnecessarily. It also makes DAGs in production more efficient; if you know a failure will result in rerunning the entire DAG, there’s no need to keep running other tasks after one failure occurs.
Turning the feature on and off is as simple as setting the parameter in your DAG:
@dag(
start_date=datetime(2023, 8, 1),
schedule=None,
catchup=False,
fail_stop=True,
)Note that when using this param, all tasks in the DAG must use the all_success trigger rule.
Other awesome updates
There are lots more notable updates in 2.7 that you should be aware of, including:
- A new
chain_linearfunction for implementing complex dependencies. The ability to mark task groups as success or failure. - A new
default_deferrableconfig for easier implementation of deferrable operators. - The option to disable testing of connections in the UI, API, and CLI (for security, disabled will be the default).
- The removal of some executors from core Airflow into their relevant provider packages.
And even these updates barely scratch the surface. Regardless of how you use Airflow, there’s something for you in 2.7.
Learn more and get started
Airflow 2.7 has way more features and improvements than we can cover in a single blog post. To learn more, check out the full release notes, and join us for a webinar on August 24th that will cover the new release in more detail.
To try Airflow 2.7 and see all the great features for yourself, get started with a free 14-day trial of Astro. We offer same-day support for all new Airflow releases, so you don’t have to wait to take advantage of the latest and greatest features.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.