From Reactive to Proactive: How Astro Observe Helps Airflow Teams Prevent Alert Fatigue and Catch Failures at the Source
You discover the executive dashboard is broken at 9 AM, during the quarterly review. The pipeline failed hours ago. No one knew.
This is the reality for most data teams. Traditional monitoring only tells you after something breaks. By then, reports are delayed, engineers are scrambling, and business users have lost trust in your data.
Most data observability tools bolt on at the warehouse layer. They can flag stale tables or schema drift, but by the time an alert fires, the pipeline failure that caused it has already happened upstream. Even native Airflow alerts aren't enough. They trigger the moment a task fails, but they don't understand which failures actually matter or what's downstream at risk.
The result is alert fatigue without real insight, and a flood of notifications that tell you something went wrong but never show you why or how big the impact is.
## **The Shift from Reactive to Proactive Monitoring with Astro Observe**
Reactive alerts only tell you what already went wrong. Proactive monitoring helps you see what's about to go wrong and stop it before it cascades downstream. When observability is built directly into your orchestration layer, you're not just notified that a table is stale or a task failed; you understand the full context of that failure — what caused it, what's affected, and who needs to act.
This is the power of orchestration-native observability. Instead of catching symptoms in the warehouse, you catch causes in the pipeline. Instead of treating every task failure the same, you focus on the ones that threaten business-critical data products.
With [Astro Observe](/product/observe/), Airflow teams can finally move from reactive alerts to proactive prevention, detecting issues at the source before they break dashboards or delay critical SLAs.
### **Why This Matters for Your Team**
Shifting monitoring upstream to the orchestration layer transforms how data teams operate, helping to:
* **Reduce downtime:** Catch failures early in the pipeline before they cascade to critical downstream assets.
* **Accelerate resolution:** Get full execution context, AI-powered log summaries, and lineage-based impact analysis in one view.
* **Pinpoint root causes:** Move beyond guesswork with instant insights into what broke, why it happened, and what else is affected.
* **Build data trust:** Address issues before end users notice them so your data products maintain their reliability reputation.
* **Eliminate alert fatigue:** Focus on meaningful, data product-level alerts instead of noisy task-level notifications.
This isn't just faster incident response. It is a fundamental shift from firefighting to prevention.
## **Introducing Proactive Failure Monitors**
[Proactive Failure Monitors](https://www.astronomer.io/docs/astro/observe-monitors#data-product-monitors) in Astro Observe continuously monitor your data products and all of their upstream dependencies to detect issues in real-time, even if your pipeline changes. When an upstream Dag fails, Astro Observe immediately alerts you with:
* **The root cause:** which specific task failed and why
* **The blast radius:** every downstream data product at risk
* **Direct lineage view:** one click to see the full impact and start troubleshooting
Unlike standard Airflow alerts, Proactive Failure Monitors understand your entire data product lineage and only notify you when the furthest upstream failure occurs. The result is fewer alerts, richer context, and faster resolution when it matters most.
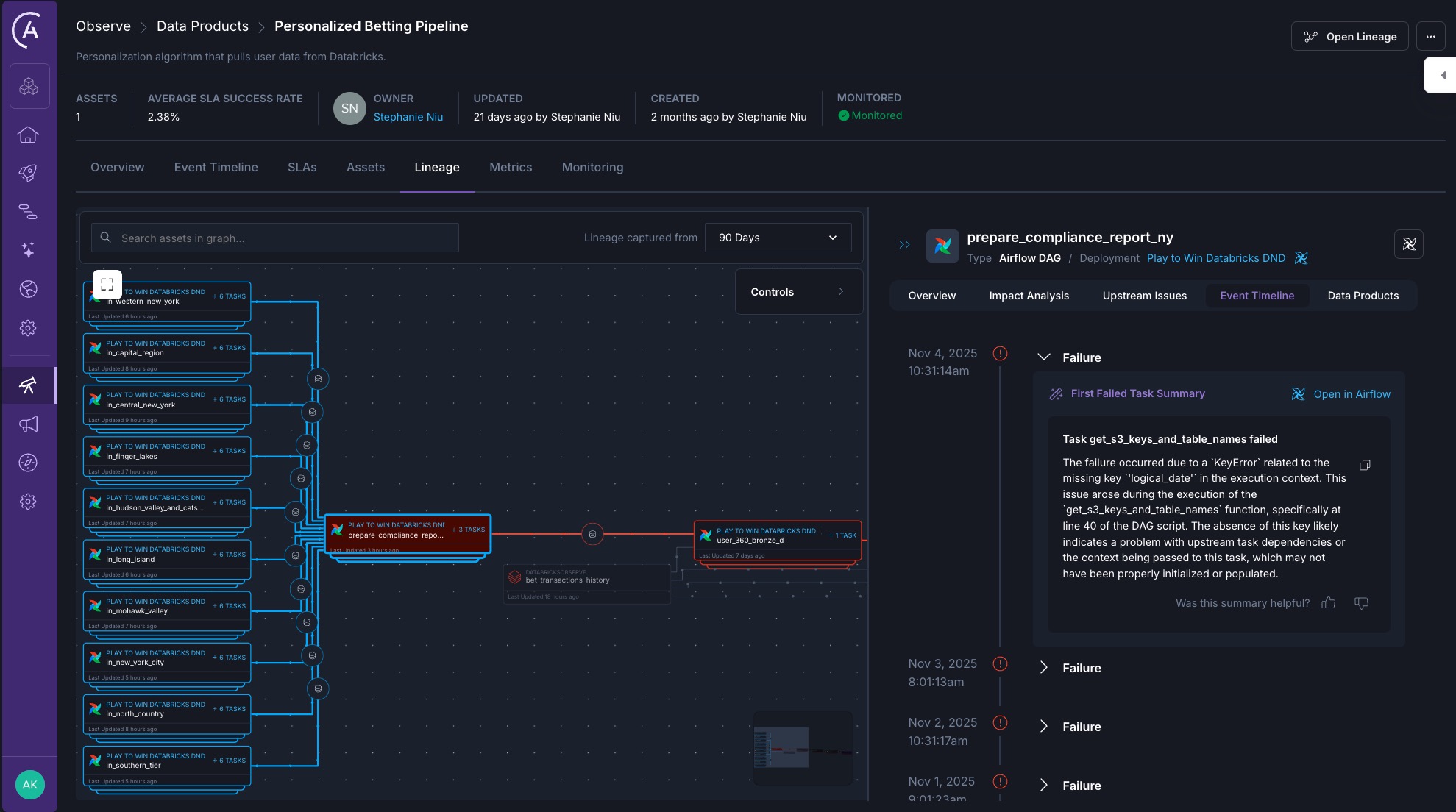 Astro Observe real-time lineage and AI log summary
### **See It in Action**
Imagine you're on the data team at a sports betting company. Your data product, `personalized_betting_pipeline`, that powers the personalized betting algorithm depends on several upstream Dags. One fails at 3 AM.
Astro Observe immediately alerts you, taking you directly to the lineage view that shows not just the failure, but the downstream dashboards now at risk. Alongside the alert, Astro Observe surfaces an AI-generated log summary that explains what broke and why, highlighting the failed task that caused the issue. You fix it before the morning deploy. No one else even knows there was an issue.
That is the difference between reactive monitoring and proactive, context-aware observability.
## **The Orchestration-Native Advantage**
Because Astro Observe is built directly into Astro, Proactive Failure Monitors are not standalone scripts or bolt-on alerts. They are part of a unified observability layer that already understands your pipelines, tasks, and dependencies.
This unlocks capabilities traditional data monitoring tools cannot match:
* **Real-time lineage** to instantly visualize failure impact, built automatically based on Airflow metadata when your Dags run.
* **AI-powered root cause analysis** that explains what broke, why it happened, and how to fix it, removing the need to dig through Airflow logs.
* **SLA tracking and ownership** to track freshness and timeliness for critical data products, helping to drive team accountability and confidence.
By combining orchestration context with observability, Astro Observe helps teams focus on the failures that truly matter to their business-critical data products, not the noise.
## **Ready to Move Beyond Reactive Monitoring?**
Data teams can no longer afford to operate reactively. Every hour spent chasing alerts or debugging in isolation is an hour not spent building. The faster you detect and resolve failures at the source, the more reliable your data becomes and the more your organization trusts it.
Want to learn more? [Book a personalized demo](/book-a-demo/) to see how Astro Observe can help your team prevent alert fatigue and catch failures before they cascade.
Astro Observe real-time lineage and AI log summary
### **See It in Action**
Imagine you're on the data team at a sports betting company. Your data product, `personalized_betting_pipeline`, that powers the personalized betting algorithm depends on several upstream Dags. One fails at 3 AM.
Astro Observe immediately alerts you, taking you directly to the lineage view that shows not just the failure, but the downstream dashboards now at risk. Alongside the alert, Astro Observe surfaces an AI-generated log summary that explains what broke and why, highlighting the failed task that caused the issue. You fix it before the morning deploy. No one else even knows there was an issue.
That is the difference between reactive monitoring and proactive, context-aware observability.
## **The Orchestration-Native Advantage**
Because Astro Observe is built directly into Astro, Proactive Failure Monitors are not standalone scripts or bolt-on alerts. They are part of a unified observability layer that already understands your pipelines, tasks, and dependencies.
This unlocks capabilities traditional data monitoring tools cannot match:
* **Real-time lineage** to instantly visualize failure impact, built automatically based on Airflow metadata when your Dags run.
* **AI-powered root cause analysis** that explains what broke, why it happened, and how to fix it, removing the need to dig through Airflow logs.
* **SLA tracking and ownership** to track freshness and timeliness for critical data products, helping to drive team accountability and confidence.
By combining orchestration context with observability, Astro Observe helps teams focus on the failures that truly matter to their business-critical data products, not the noise.
## **Ready to Move Beyond Reactive Monitoring?**
Data teams can no longer afford to operate reactively. Every hour spent chasing alerts or debugging in isolation is an hour not spent building. The faster you detect and resolve failures at the source, the more reliable your data becomes and the more your organization trusts it.
Want to learn more? [Book a personalized demo](/book-a-demo/) to see how Astro Observe can help your team prevent alert fatigue and catch failures before they cascade.
Astro Observe real-time lineage and AI log summary
### **See It in Action**
Imagine you're on the data team at a sports betting company. Your data product, `personalized_betting_pipeline`, that powers the personalized betting algorithm depends on several upstream Dags. One fails at 3 AM.
Astro Observe immediately alerts you, taking you directly to the lineage view that shows not just the failure, but the downstream dashboards now at risk. Alongside the alert, Astro Observe surfaces an AI-generated log summary that explains what broke and why, highlighting the failed task that caused the issue. You fix it before the morning deploy. No one else even knows there was an issue.
That is the difference between reactive monitoring and proactive, context-aware observability.
## **The Orchestration-Native Advantage**
Because Astro Observe is built directly into Astro, Proactive Failure Monitors are not standalone scripts or bolt-on alerts. They are part of a unified observability layer that already understands your pipelines, tasks, and dependencies.
This unlocks capabilities traditional data monitoring tools cannot match:
* **Real-time lineage** to instantly visualize failure impact, built automatically based on Airflow metadata when your Dags run.
* **AI-powered root cause analysis** that explains what broke, why it happened, and how to fix it, removing the need to dig through Airflow logs.
* **SLA tracking and ownership** to track freshness and timeliness for critical data products, helping to drive team accountability and confidence.
By combining orchestration context with observability, Astro Observe helps teams focus on the failures that truly matter to their business-critical data products, not the noise.
## **Ready to Move Beyond Reactive Monitoring?**
Data teams can no longer afford to operate reactively. Every hour spent chasing alerts or debugging in isolation is an hour not spent building. The faster you detect and resolve failures at the source, the more reliable your data becomes and the more your organization trusts it.
Want to learn more? [Book a personalized demo](/book-a-demo/) to see how Astro Observe can help your team prevent alert fatigue and catch failures before they cascade.

Get started free.
OR
API Access
Alerting
SAML-Based SSO
Airflow AI Assistant
Deployment Rollbacks
Audit Logging
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.