Cross-Region Disaster Recovery on Astro Is Now Generally Available: Here's How We Built It
13 min read |
Cross-region disaster recovery (DR) on Astro is now generally available for our AWS data planes, giving customers the ability to fail over their Airflow workloads to a secondary region with a single click. This post covers how we designed and built it: the architecture decisions, the trade-offs, and what we learned along the way.
Why We Built This
Our customers run business-critical data pipelines. Financial services firms use them for regulatory reporting. Healthcare companies use them for patient data processing. When these pipelines stop, the downstream impact is real and immediate.
Teams running Airflow at enterprise scale treat cross-region resilience as a hard requirement. Before Astro DR, meeting that requirement meant building it yourself: standing up parallel infrastructure, wiring up replication, writing custom failover runbooks. That's typically a 3–6 month engineering effort, and maintaining it is a burden that never goes away.
We wanted to deliver DR as a platform capability: toggle it on, pick a secondary region, and the platform handles the rest. Our target SLAs were aggressive but achievable: an RTO under 1 hour and an RPO under 15 minutes, with tighter replication targets for Airflow metadata (5 minute) than for task logs.
The High-Level Architecture
At its core, our DR solution provisions a second EKS cluster and associated infrastructure in an alternate AWS region. In normal operation, this secondary cluster runs in a warm standby mode with just enough components to stay healthy and ready to take over. When a failover is triggered, workloads shift from the primary to the secondary cluster while data replication ensures continuity.
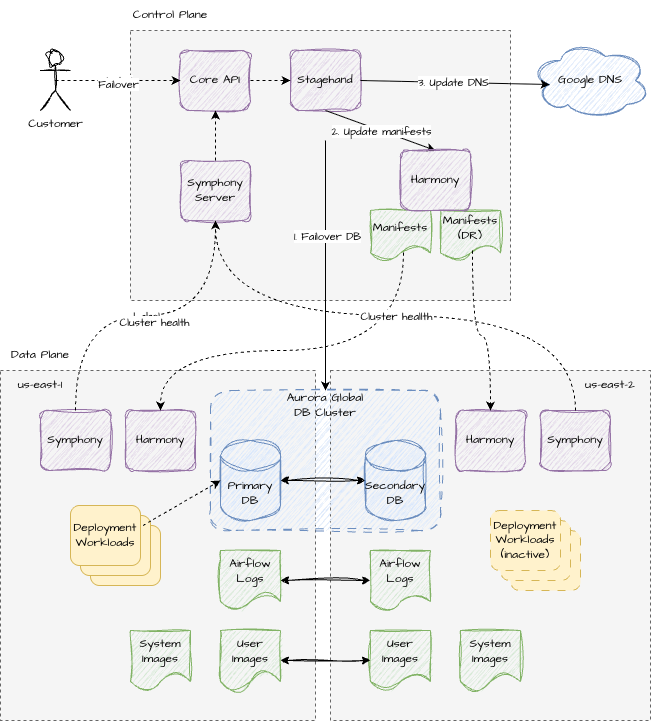
Three categories of state need to survive a regional failure:
Airflow metadata: the database backing Dag runs, task instances, connections, and variables
Task logs: stored in S3, needed for debugging and audit trails
Container images: customer-deployed images that need to be available in the secondary region
Each of these has a different replication strategy, which we'll walk through below.
Data Model: One Cluster, Two Regions
One of the most consequential design decisions was how to model the DR cluster in our control plane. We had two options:
Option A: Model the DR cluster as an entirely separate record, a first-class cluster with its own ID, APIs, and lifecycle.
Option B: Model DR as an extension of the existing cluster record, a property indicated by a `dr_region` field, with a companion `is_failed_over` flag to track state.
We went with Option B, and it wasn't close.
Option A was appealing on the surface. It would simplify observability (each cluster reports metrics under its own ID) and allow independent upgrade rollouts to reduce blast radius. But it introduced a cascade of problems:
- Schema duplication. Many fields including VPC CIDRs, DB instance sizes, node pool configs, must be identical across the pair. Two separate records means either duplicating these fields (and keeping them in sync) or adding join logic everywhere.
- API complexity. Operations that don't make sense on a DR cluster (creating deployments, configuring VPC peering, mapping workspaces) would need guards and special-case handling across dozens of endpoints.
- Deployment association. Deployments, API keys, and workspace mappings are all tied to a cluster. Associating them with two clusters would require significant schema changes or lookup indirection throughout the codebase.
- Infrastructure coupling. The two clusters share an AWS account, use replicated KMS keys, and have ordering dependencies during provisioning. Coordinating this across two independent cluster lifecycles would push orchestration complexity into the API layer.
With Option B, enabling DR is mostly opaque to existing API operations. The control plane sees one cluster. The complexity of managing two sets of infrastructure lives entirely in our infrastructure provisioning and manifest generation systems, exactly where it belongs.
Database: Aurora Global Clusters
This was one of our bigger infrastructure changes. We replaced RDS with AWS Aurora Global Clusters, which gave us purpose-built cross-region replication with automatic write-fencing during failover.
An Aurora Global Cluster consists of two database clusters: one primary (writer) and one secondary (reader), each spanning multiple availability zones. The architecture separates compute from storage, which unlocked a key cost optimization: we run the secondary database cluster in headless mode. Storage is continuously replicated, but we only provision compute instances when an actual failover occurs. In our testing, spinning up the compute layer during failover takes roughly 5 to 10 minutes, well within our RTO budget.
Aurora also gives us strong consistency guarantees during failover. It exposes an `rds.global_db_rpo` parameter which bounds the maximum data loss window at the cost of write latency, though we found no noticeable performance impact during our load testing when setting this to its minimum value of 20 seconds. And when failing back to the primary region after recovery, Aurora's switchover operation guarantees zero data loss by handling write fencing internally.
We did extensive performance testing to validate that Aurora performed comparably to RDS for Airflow workloads before committing to this migration. The results confirmed that Aurora was a viable drop-in replacement with no meaningful regression.
Storage: Bi-Directional S3 Replication
Task logs and the customer image registry bucket use bi-directional S3 replication with optional S3 Replication Time Control (S3 RTC), which provides an SLA-backed 15-minute RPO for replicated objects.
Bi-directional replication is important here. During a failover, new task logs and newly pushed images are written to buckets in the secondary region. When the customer eventually fails back to the primary, those new objects need to replicate in the other direction so nothing is lost in the transition.
Not everything gets replicated, though. Our proxy registry bucket which serves as a pull-through cache for upstream image repositories is excluded since it can be rebuilt on demand. This does depend on our internal image registries already being replicated across geographic areas, which they are, though we've noted that expanding replication to more regions within each area would further improve availability.
Compute: Warm Standby
The secondary EKS cluster runs a curated subset of components - enough to be healthy and observable, but not so much that we're burning resources on idle workloads.
Always running in standby:
- Karpenter: (cluster autoscaler for EKS) required for any workloads to run at all
- Harmony: (our GitOps-style manifest reconciler) needed to apply configuration changes that inflate the cluster during failover
- Managed egress: (in-cluster component that manages and synchronizes route tables for controlling egress traffic) so custom networking configuration stays in sync
- Observability stack: (metrics, logging, collectors) so we have continuous visibility into DR cluster health
- Various other foundational components: cert-manager, IAM controllers, the bin-pack scheduler
Deliberately not running in standby:
- Deployment workloads: Airflow deployments must only run on one cluster at a time to prevent split-brain scenarios with external systems. In practice, scaling deployments from zero takes 5–10 minutes in the worst case, well within our RTO.
- Airflow infrastructure controllers: these depend on database connectivity, which isn't available while the secondary DB is in headless mode.
One subtle but important detail: we always provision deployment IAM roles in both regions, even during standby. AWS IAM is a global service, but its control plane (the API endpoint for write operations like CreateRole, AttachRolePolicy, etc.) is hosted in us-east-1. So while IAM resources are globally available once created, the ability to create or modify them depends on us-east-1 being operational. By pre-provisioning them, we avoid a dependency on a potentially-affected region during the failover critical path.
We also took great care to ensure that the failover (and switch back) operations themselves have no dependency on AWS APIs in the region being switched away from. We skip unnecessary Cloudformation stack updates and make sure that any other API calls we need to make are only being performed against the region we are switching to.
Manifests: Two Versions, One Source of Truth
Our manifest generation system needed to produce two variants of every plugin and deployment manifest. One for the primary cluster, one for the DR cluster. Each variant can also differ based on the current failover state (e.g. to inflate or deflate workloads).
The implementation is straightforward: when generating manifests for a DR-enabled cluster, we also produce a second set of manifests for the secondary cluster. Each plugin's generation function receives a parameter indicating whether it's generating for the DR cluster, and can adjust its output accordingly - different region configs, different identity bindings, inflated or deflated workloads etc.
The DR manifests are uploaded as separate blobs and the Harmony client on the secondary cluster is configured to request the secondary variant of manifests.
The Failover Sequence
When a customer initiates failover from the UI, the API simply updates an `is_failed_over = true` field on the cluster record in the DB and triggers a cluster update. Our dataplane infrastructure management system (Stagehand) orchestrates the actual failover through a deterministic and idempotent sequence of operations:
- Provision Aurora compute. The CloudFormation stack in the secondary region is updated to spin up the database compute instance - adding the "head" to our headless setup.
- Failover the Aurora Global Cluster. We invoke the Aurora failover API to promote the secondary region to the writer and poll until the promotion is confirmed.
- Inflate the secondary cluster. We trigger manifest regeneration for all plugins. The updated manifests, now in the "failed-over" state, inflate workloads on the secondary cluster.
- Update DNS. The top level cluster ingress DNS record is pointed to the secondary cluster's load balancer IP. DNS for deployment level domains and other system services simply use CNAMEs pointing to the top level cluster domain so we only need to change the one DNS record here.
- Cleanup. After the failover operation is complete, we run a second workflow to de-provision the DB compute in the non-active region to revert it back to a "headless" setup. This runs as a separate workflow outside the critical path of DR failover so that it doesn't impact RTO.
Failing back to the primary follows the same sequence in reverse, with one key difference: we use Aurora's switchover operation instead of a failover, which guarantees zero data loss since the secondary cluster has been the active writer.
Programmatic Control: API and Terraform Support
As part of the GA release, DR is now fully manageable via the Astro API and Terraform. Platform teams can initiate failover and failback programmatically, integrate DR operations into existing runbooks and automation, and provision DR-enabled clusters through infrastructure-as-code without touching the UI.Terraform support covers cluster creation with DR enabled (specifying the secondary region and optional VPC CIDR overrides) as well as the failover state toggle. The Astro API exposes the same operations. Both are available now in the Astro Terraform provider and API documentation.
Observability: Seeing Both Clusters
We run the full observability stack on the DR cluster from day one. Metrics and logs from the secondary cluster are distinguished using a `-dr` suffix on the cluster ID. We debated between this approach and adding a new metric label to indicate metrics from a DR cluster. We landed on simply adding the suffix as it avoided needing to update many existing dashboards and alert queries to group on a new label. For dashboards and alerts, DR secondary clusters are treated as separate entities from their primary counterparts.
In addition to the various metrics we track we also have a custom in-cluster health monitoring component (Symphony) which reports cluster health issues to our control plane. These health details from both regions roll up into a single cluster health status. If either the primary or secondary cluster reports an issue, the overall cluster health is marked unhealthy at the highest reported severity. This ensures that a degraded DR cluster gets surfaced immediately rather than silently sitting broken for months.
Deployment health requires no changes, since deployments only run on one cluster at a time. Whichever cluster is active simply reports health as normal.
Migration Path for Existing Clusters
New clusters can enable DR at creation time by simply specifying the secondary region as well as some optional CIDR values for the VPC subnets. Enabling DR on an existing cluster is a more involved process which requires migration from the cluster's current RDS instance to Aurora and performing a one-time batch replication of existing S3 objects to the secondary buckets (since S3 replication only replicates objects created after replication is enabled). The migration uses Aurora's read-replica capability to minimize downtime: we create an Aurora cluster as a read-replica of the existing RDS instance, let it catch up, stop writes briefly, then promote the replica. The original RDS instance is preserved throughout the process as a safety net - rollback is possible at any point before the final cutover by restoring from the last RDS snapshot. This process is handled by our customer reliability engineering team upon request, using internal tooling to guide each step and reduce the risk of errors.
Lessons Learned
Centralizing DR awareness in the manifest system paid off. Manifest generation code quickly accumulates DR-specific conditionals: different region configs, different metadata, different workload states depending on primary vs. secondary. Spreading that logic across every plugin would have been a maintenance liability. We refactored our manifest generation system so that all DR-specific differences are handled in one place, abstracted away from downstream plugin code. Future developers can write plugin logic without needing to hold the full DR model in their heads.
Aurora pricing models require empirical comparison, not paper math. Aurora offers two pricing models: Standard (pay per IO request) and IO Optimized (higher hourly rate, all IO included). We spent significant time analyzing IO and storage usage across our cluster fleet, and discovered that RDS IO metrics do not translate directly to Aurora billing metrics because of Aurora's fundamentally different storage architecture. We ended up running identical Airflow workloads on both RDS and Aurora to derive an approximate conversion factor for our cost estimates.
Headless database standby made DR economically viable to deliver. Aurora's compute/storage separation meant we could maintain continuously replicated storage in the secondary region without running idle database compute between failovers. Storage stays live and ready; compute spins up only when it's needed. Without this architecture, delivering DR as a managed platform capability at the reliability targets we set would have been significantly harder to justify.
Test failover end-to-end, repeatedly. We validated our RTO on production-scale clusters running 80 deployments with 1,200+ concurrent tasks. The confidence this gave us - and our customers - was worth every hour of testing. Also, since performing a real DR failover should be a (hopefully) rare occurrence, it was important for this capability to be tested frequently to ensure that things work when they are needed most.
Before GA, we completed a formal reliability testing engagement with AWS covering mock failover and failback scenarios and confirming that no step in the failover sequence has a dependency on the primary region. DR failovers are hopefully rare, which makes continuous automated testing essential.
We've also expanded our integration test suite to include comprehensive coverage of failover validation and DR-enabled cluster behavior with every production release.
What's Next
We're extending support to GCP and Azure over the coming quarters, and we're working toward a fully self-service migration experience for existing clusters. If you are running Astro on AWS and want to enable DR, reach out to your account team or contact Astronomer support to get started.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.