How Astro runs billions of Airflow tasks around the world
8 min read |
Astronomer was founded in 2018 on a mission to deliver the world's data. We've done this by offering our users the ability to run and manage Apache Airflow® at a very large scale. If you're not familiar, the first version of Airflow was built at Airbnb in 2015 by Maxime Beauchemin as one of the first data orchestration platforms to offer the ability to write data pipelines as code. It was subsequently open-sourced and ultimately adopted by the Apache Software Foundation, where today it continues to thrive as the most active and popular open-source data orchestration platform.
Astro, our fully managed SaaS offering, has experienced explosive growth since we released it in mid-2022. It's the culmination of years of experience running Apache Airflow® at scale, and we're really proud of what we've built. Today, the platform runs over 100 million tasks per month (that's over 2,000 tasks per minute!) across all 3 public clouds and ~400 shared and dedicated Kubernetes clusters. As a point of reference, there are some open-source users that have built out internal Airflow-as-a-service offerings and publicly talk about their scale: Snap runs ~10m tasks per month, Shopify runs ~5m tasks per month, Etsy runs ~1m tasks per month, and Pinterest runs ~1m tasks per month.
We've never been very public about how we run Airflow at this scale, but that changes today with this inaugural post on our engineering blog. This article will walk through Astro's high-level architecture and set up context for more in-depth future discussions.
The Control Plane
Without getting into the details of our RBAC model (everyone's favorite topic), at its core, Astro lets users create Deployments - instances of Apache Airflow® packaged with our commercial Astro Runtime layer. Deployments run on Clusters, which represent the physical infrastructure required to run a Deployment. Clusters are available in all 3 public clouds and are either multi-tenant or single-tenant, depending on a user's networking and cost preferences. The Astro Control Plane refers to a set of services and infrastructure that is responsible for providing interfaces to provision, configure, and manage Astro entities.
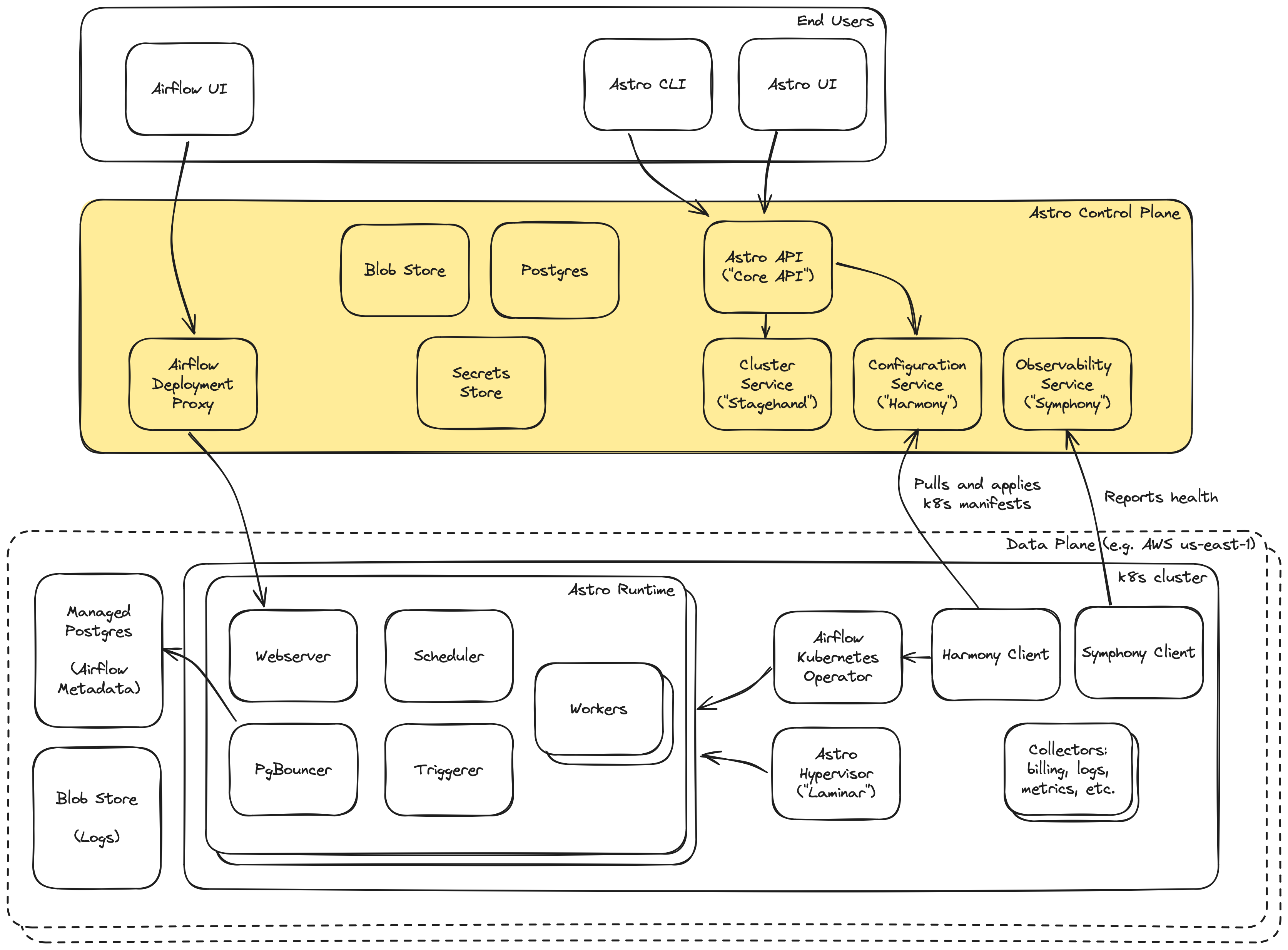
The Astro API is the public REST API that powers the Astro platform, including the UI and CLI that our customers use, and also allows customers to write their own tools to automate directly against Astro. The API allows users to manage clusters, deployments, workspaces, users, and to deploy code to their Astro Deployments by interacting with its downstream REST APIs.
Stagehand (the Clusters Service) is responsible for provisioning Data Plane Clusters, reporting their provisioning status back to Astro API, and keeping clusters up to date. After receiving a request from Astro API to create a Cluster, it interacts with Cloud Provider APIs to provision all the infrastructure needed to eventually run Astro Deployments, informs Harmony (the Configuration Service) about the cluster, and installs the Harmony Client into the Data Plane Cluster.
From that point onward, the Harmony Client in each data plane cluster maintains the system's harmony by periodically querying Harmony (in the Control Plane) for the set of desired Kubernetes manifests in that Data Plane, then syncing them down into the Data Plane cluster and applying them. These manifests contain all components that need to run in the Data Plane, including cluster-level components (ingress gateways, observability tooling, other cluster-level components pictured below) and the Astro Runtime components needed for each Deployment.
Harmony offers APIs to facilitate per-cluster manifest generation (written to by the Astro API), and APIs to fetch the desired set of manifests (consumed by the Harmony Client). Under the hood, these manifests are generated by server-side code executing business logic around per-customer entitlements and configuration. They are then stored in blob storage at customer-specific paths, and are fetched from blob storage when Harmony Client requests the desired set of manifests to apply to a cluster. More on this later!
Deployment CRUD requests go through the Astro API, and then to Harmony. The desired manifests are generated and stored in blob storage along with the rest of the cluster's manifests to be fetched the next time they're requested by Harmony Client. The manifests chiefly include a fully-formed specification defining the Airflow Kubernetes Custom Resource for a Deployment, which gets reconciled by our Airflow Kubernetes Operator, the component responsible for actually spinning up and configuring the Astro Runtime components.
The Data Plane

As configuration changes are either made by users through the Astro API and propagated down to Harmony, or as Astro itself pushes out new configuration via a Harmony code change or feature flag change, the Airflow Kubernetes Operator reconciles changes and keeps Astro Runtime up to date with the desired state.
The Airflow Kubernetes Operator reconciles a fully formed Custom Resource spec and brings up the Astro Runtime components. This spec includes Astro and Airflow-specific configurations like:
- the Airflow Executor type, Kubernetes or Celery
- scheduler sizing, to accommodate task volume
- anti-affinity settings, to ensure workloads are spread across nodes and availability zones
- worker sizing/scaling configuration, to balance customer cost with performance and scalability
- environment variables, to configure Astro Runtime and inject configuration into user DAG code
- service accounts for the Runtime components, to run securely following least privilege principles
We also write and deploy a Database Operator, another Kubernetes Operator which is responsible for managing the lifecycle of logical Airflow databases within the Cluster's physical database instance. All Deployments in a Cluster share a single physical database instance, which Astronomer is responsible for monitoring, configuring and sizing appropriately. As Deployments are created and deleted, the logical databases are life-cycled accordingly, with the Operator also supporting soft-delete capabilities: we don't immediately delete a Deployment's database upon Deployment deletion to protect against accidental deletion.
The Airflow Deployment Proxy provides Airflow UI and API access to end users. Proxying this traffic through the Control Plane is important for two reasons – it allows us to enforce authorization checks (is user A allowed to perform X action against a given Deployment?), and it ensures that nothing in the Data Plane is publicly exposed to the internet. With a large portion of our customer base being security conscious, it's imperative that we eliminate any public internet exposure in the Data Plane, and instead have components in the Data Plane reaching out to the Control Plane rather than the other way.
While the Airflow Kubernetes Operator configures and manages Deployments, it is imperative for us to provide visibility into Deployment status and health for end users. We do this with a combination of Symphony (the Observability Service) and Laminar (the Astro Hypervisor).
The Symphony Client, running in the Data Plane, is constantly scraping multiple data sources in the cluster, gathering data, and sending information up to Symphony in the Control Plane. One of the data sources that Symphony Client scrapes is the Kubernetes API. It does this to gather information about currently running pods, what state they're in, what versions of software they are running. With all this information, Symphony is able to determine the status of a Deployment (healthy, unhealthy or deploying), which we expose via the Astro API and UI.
The Symphony Client also receives information from Laminar, our newly-built hypervisor for Airflow. While the Kubernetes API gives us infrastructure-level visibility, Airflow is a complex system that requires more than infrastructure-level monitoring. Laminar (the Astro Hypervisor) is intimately familiar with Airflow and the metadata database, and today performs two tasks: intelligent autoscaling, and enhanced visibility into the health of the Astro Runtime.
If there are no tasks that require the Airflow Triggerer (i.e. no Airflow tasks are using deferrable operators), the Triggerer can be scaled down to zero, saving unnecessary infrastructure cost.
Laminar’s ability to reach into the Airflow metadata database also lets us report on Airflow-specific deployment health metrics. For example, tasks may be stuck in “queued” for longer than a given threshold. Once Laminar detects this state, Symphony Client will be made aware of it the next time it scrapes Laminar, and can play this music back up to the Control Plane, allowing us to make end users aware that there is an operational issue with their Deployment.
Next Steps
While we have the pleasure of writing about the Astro platform, building it was a full team effort from all past and present Astronomers.
This is the first time we’re publicly talking about how we’ve built Astro at this level of detail. We plan to share more on specific components, features, and experiences in the coming months. If you have any feedback, thoughts, or general comments, please let us know at either mehul@astronomer.io or julian@astronomer.io. Until next time!

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.