How to Build a Modern Data Stack
8 min read |
In today’s digital world, economists have declared data one of the most valuable business resources. Companies that will manage to unlock the value of their datasets will leap miles ahead of their competition. But how to deliver value rapidly when there’s an entire data infrastructure to build first?
Indeed, historically establishing end-to-end data tools and infrastructures used to be a costly, time-consuming endeavor. However, with the development of self-service data suppliers for enterprises, cloud-based warehouses, and open-source frameworks, businesses of all sizes may quickly modernize their data stack, drastically reducing time-to-insights. Especially if they add the orchestration layer!
What is a data stack?
In order to understand what a data stack is, it’s essential to realize that “data is gold” indeed, but oftentimes raw data isn’t enough to deliver immediate business value. In order to produce value from data, it must first be gathered, categorized, and cleansed - and a data stack is the collection of technologies that routes data through those stages. It delivers a fast and reliable flow of information, facilitating a smooth data journey from the source to the destination. Experts say that data stack often differentiates growing data-driven organizations from companies on the verge of going bust.
If, for example, you have a marketing data stack, it likely includes a CRM, automation, and analytical tools. It can consist of as many elements as your goals require. Information travels through the stack in line with your internal processes, which allows your team to access the data at any given stage.
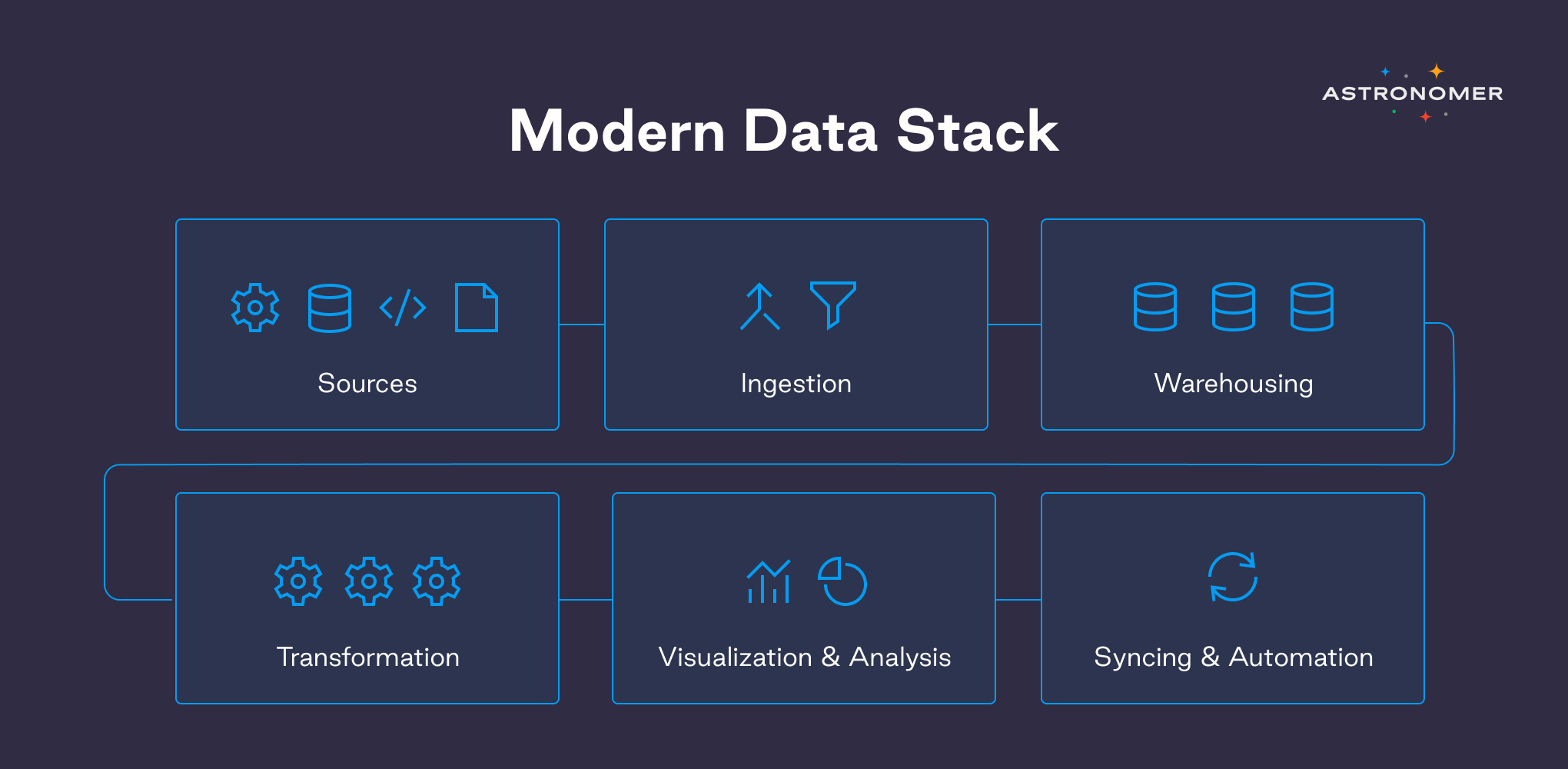
The components of a modern data stack
A modern data stack is built on the foundation of four main components: a data warehouse or lake, data pipelines, a transformation tool, and an analytics platform.
- Storage: data warehouse
A place for storing the data is a data warehouse (or lake) that acts as the primary place for all of the organization's data collection. The data warehouse is a central storage location for all types of data originating from various sources. It enables you to quickly pull together all of your data at any size and gain insights via analytical dashboards, operational reports, or advanced analytics. It can be cloud-based, or on-premises.
- Ingestion: data pipelines
Now that we have the data warehouse set, an ingestion tool kicks in to pull in raw data from various sources. App data, marketing data, social media users data, and website logs and APIs - it all needs to get pulled in for further processes. Generally, one or more data pipelines guarantee that data is fed into the warehouse smoothly and with minimum technical effort.
- Transformation: cleaning up raw data
Once the raw data has been imported into the data warehouse, it is ready for transformation and unification. During the transformation step, a set of rules or functions are applied to the loaded data. Renaming columns, combining several tables, and aggregating data are all common transformation activities. This phase cleans up raw data in order to facilitate subsequent analysis. dbt (Data Build Tools) is a SQL command-line program that allows data analysts and engineers to convert data within their warehouse more effectively. Another popular approach is to use Airflow as an orchestration engine in conjunction with transformation written in either python or SQL - highly recommended.
- BI and data analytics platform
Last but not least, the fourth component is a data science platform that can analyze data and via which end users may access their insights. It gives an opportunity to create interactive dashboards and reports and visualize data - to deliver better business decisions in the long run.
Modernizing the data stack
A distinctive characteristic of the modern data stack is that it was born in the cloud era, allowing users to more quickly drive business value from SaaS solutions without dealing with the collection of challenges that come with managing infrastructure. Moreover, what makes a data stack “modern” is that it meets various demands of modern data issues at each phase of the data lifecycle - from the moment it’s generated to when it’s ready to become “information”. It’s crucial to realize that the modern data stack seems more advanced technologically, but on the contrary - it actually reduces the technological barrier to data integration. Modern data stacks are designed to allow data engineers, analysts, and business users to optimize for time-to-value and rapid iteration without building out a custom suite of internal tooling. These capabilities promote end-user accessibility, scalability, and iteration, allowing companies to easily accommodate growing data demands without costly, lengthy delivery windows.
How does Airflow fit in the modern data stack?
Now that you know the components of a data stack, you understand how companies benefit from a modern approach. They use separate, interface-driven tools to extract, load, and transform data - but without an orchestration platform like Airflow, these tools aren’t talking to each other. If for whatever reason, there’s an error during the loading, the other tools won’t know about it. The transformation will be run on bad or yesterday’s data - and deliver an inaccurate report that, on a bad day, no one will notice. Imagine the implications!
Moreover, companies often have more than two data stack tools - five, ten, sometimes even more. Manually managing those dependencies at scale gets very challenging. As companies grow and adopt new SaaS technologies or cloud-based tools for pipelines, spotting all the errors and ensuring smooth dataflow becomes a nightmare. They need data orchestration.
A data orchestration platform can sit on top of all that, tying the components together, orchestrating the dataflow, and alerting if anything goes wrong. It’s vital in the context of overseeing the data end-to-end life cycle, allowing businesses to maintain interdependency across all the systems. It fits perfectly in the modern data stack paradigm - making connections between all the key tools.
There are a number of orchestrators in the market that can help you achieve that, but our tool of choice is Apache Airflow®. It’s interoperable, mature as a product, and the open-source community behind it is a real gem. Airflow makes it simple to execute any data task, such as Python scripts, SQL queries, distributed Spark tasks, or instructions to run processes on other orchestrators or ETL tools.
Reasons to modernize your data stack with Airflow
- More time and money to spend on actual data engineering instead of infrastructure management
How much time is your team spending on administration, updates, maintaining, and scaling infrastructure powering your data services? By modernizing your data stack you can’t eliminate all the administration entirely, but you can sure start instantly scaling up your workloads and simplifying your life. So if you want a faster time-to-value (and who doesn't? ), this is the ideal approach to keep your team focused on providing high-value solutions to your company rather than wasting time on server updates.
- (Almost) real-time analytics and data-driven decisions
Probably the most compelling reason to adopt a modern data stack is that it shortens the time required to arrive at insights. It’s particularly valuable for fast-growing organizations which take a lot of important decisions every day. By adopting a modern data stack, data teams can rapidly offer business decision-makers the data and insights for better, data-driven decisions. With time to insight minimized, companies respond more effectively to market changes. As a result, data-driven decision-making can move at the speed of business.
- Eliminate the need for DevOps resources
For every small company and startup, there will come a moment to undertake extensive research on a product, market, and customers in order to make tactical business decisions to stay ahead of the competition. It may involve gathering data from many sources, such as marketing platforms, web traffic data, own app data, and then combining it into a centralized platform for reports and dashboards.
Achieving this requires an extensive suite of tools. Typically, a Data Engineering team would partner with a DevOps team to learn, build, operate and monitor a suite of infrastructure to power this, but smaller companies who want to move fast don’t always have the bandwidth to support an ever-growing amount of data infrastructure needs. Airflow can be the answer.
- Data self-service for non-technical employees, too
A wide range of users can use modern data platforms intuitively. It’s important because people shouldn’t need an analyst to help them grasp their own company’s data. If someone wants to implement data into their work - kudos to them, it should be easy as pie. And it often isn’t.
With an orchestrated modern data stack, employees can effortlessly discover and analyze data, understand the context through column descriptions or lineage, and derive insights.
- Agile data management
The complexity of legacy data stacks is one of their primary issues, as obtaining data generally necessitates the execution of time-consuming ETL operations. And if you need to make a minor change to your data or query, the lengthy procedure begins again. Modern data platforms change this.
Orchestrating your modern data stack with Astronomer
With Astronomer, a data stack is easy to set up, with no lengthy sales process and time-consuming implementation cycles. It’s a classic example of “plug and play” - the modern data stack will innovate naturally, and Astronomer will make sure your data can benefit from the best of breed tools. Airflow offers an incredible number of providers and tools, by the way. They are built on open standards and APIs, making integration with the rest of the stack easy as pie. Airflow is all about putting power in the hands of users, and making your life easier. And Astronomer makes it even better.
If you’re convinced by now, get in touch with one of our experts! If not, definitely get in touch with one of our experts, too.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.