Airflow in Action: Best Practices Learned From Scaling AI at Oracle
5 min read |
At the Airflow Summit Ashok Prakash, Senior Principal Engineer at Oracle, shared practical lessons from building and operating high-scale AI systems at Oracle Cloud. This talk is for engineers and platform teams responsible for training, benchmarking, and serving models in production, especially when workloads run on cloud Kubernetes and spend is material.
Scaling ML Infrastructure: Lessons from Building Distributed Systems spans GPU-driven workloads and healthcare-focused agentic platforms. The talk frames AI infrastructure as a compute and coordination problem, then shows how Apache Airflow® becomes the logic layer that turns fragmented ML components into reliable, observable production pipelines. The talk provides concrete patterns for scaling Airflow Dags on Kubernetes, improving GPU ROI, and hardening workflows for production.
Compute Is the Bottleneck Now
Ashok opens with the core constraint for teams running GPU-backed ML systems: compute demand. He frames the “paved path” as the operating model cloud platforms use to deliver GPUs reliably at scale, then translates those lessons into practical orchestration patterns teams can apply with Airflow.
He organizes the challenge around clear pillars: scalable compute, cost efficiency and GPU return on investment, and a control plane that can coordinate heterogeneous work. Kubernetes provides the core abstraction layer for GPUs, but it does not solve orchestration on its own. You still need a control plane that understands what should run, when it should run, and how to react when it fails.
Airflow as the ML/AI Control Plane
The core argument is simple: MLOps is inherently heterogeneous. Data preparation, feature engineering, training, registry updates, and serving workflows span multiple systems and services. Airflow matters because it “glues everything together” into Dags that teams can reason about, operate, and evolve.
Ashok highlights three reasons Airflow fits at the center of ML and AI workflows:
- Data agnosticism: Pipelines need to handle many data types and formats, from structured records to audio and video. Airflow orchestrates the ETL and transformation flow for all types of data, no matter where you store it.
- Scalable compute coordination: AI inference workloads can suddenly spike without warning, requiring autonomous load sharing.. Airflow provides the coordination layer to trigger the right compute at the right time, rather than keeping large inference capacity idling to hedge against unpredictable spikes.
- Operational reliability: Airflow’s reliability features like automatic retries protect against rate limits and transient API failures and callbacks can be used to run code notifying engineers in case of Dag or task failures.
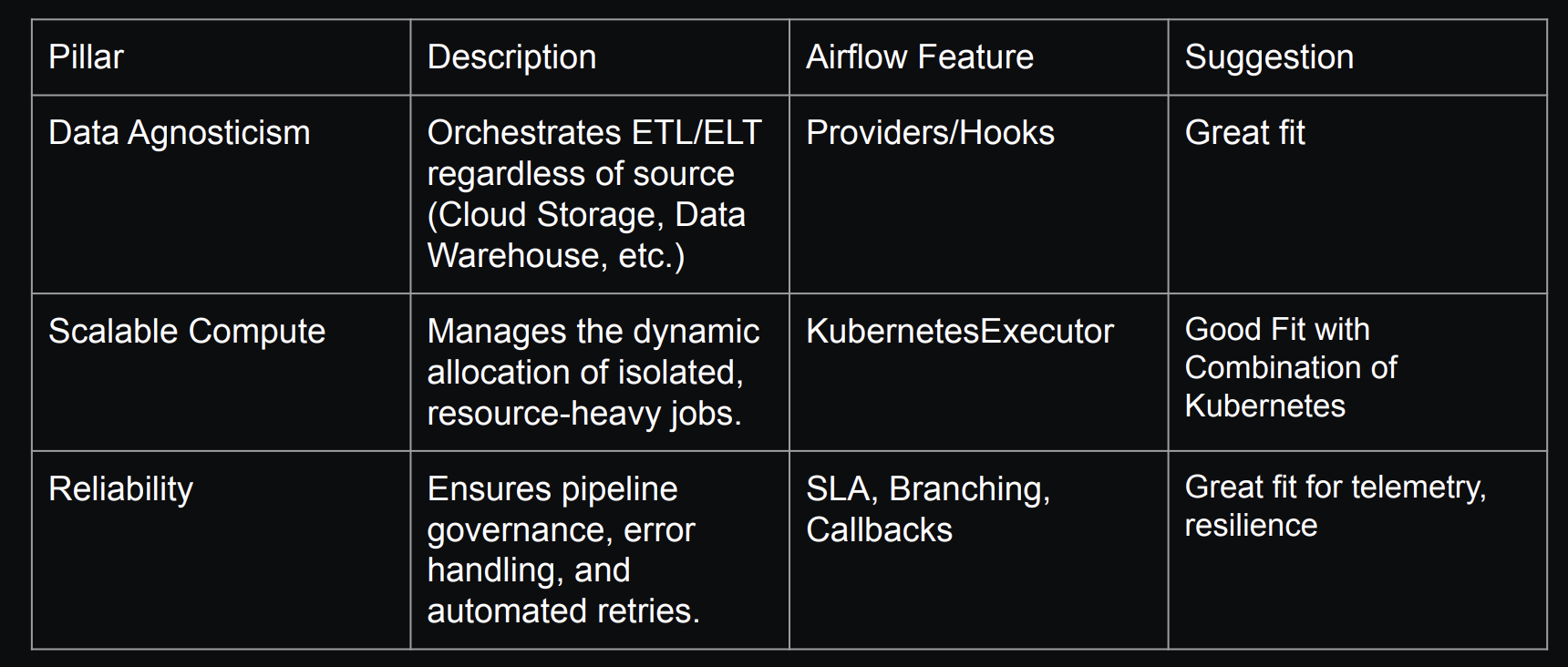
Figure 1: The three pillars of Airflow in ML and AIOps, based on scaling GPU workloads at Oracle. Image source.
Stop Mixing Planes
A key best practice: separate infrastructure provisioning from orchestration. Ashok is explicit that teams should not collapse VPCs, networking, and provisioning into the same layer as Airflow Dag logic. Use infrastructure-as-code tools like Terraform or CDK to provision the underlying platform. Run GPU jobs on Kubernetes. Use Airflow underneath as the logic control plane that triggers and coordinates those jobs. This separation prevents Airflow from becoming a scaling bottleneck and keeps responsibilities clean.
Scale GPUs With Dynamic Workflows
Ashok’s scaling guidance focuses on making GPU usage measurable and adjustable:
- Right-size jobs dynamically: Use Kubernetes resource requests and limits, then adjust GPU allocation based on the job’s needs. He gives the pattern of running a job with four GPUs, then rerunning or tuning with two GPUs based on results.
- Explode experiments safely: When you have many datasets or hyperparameter combinations, dynamic task mapping lets you scale out experimentation without hand-built Dag sprawl.
- Share metadata fast: Instead of pushing every intermediate result through slower external stores, use XCom to share lightweight metadata like hyperparameters between tasks when you need quick iteration loops.
He also reinforces the goal behind these mechanics: maximize GPU ROI by reducing idle time, shrinking failure rates, and ensuring each run produces actionable outputs.
Production Means Process
Ashok closes with production fundamentals that many teams skip:
- CI/CD for Dags and workflows so changes ship predictably.
- Modular Dag design to avoid one giant shared Dag that turns updates into chaos.
- Security hygiene: no hardcoded secrets, and careful handling of third-party credentials.
- Human review: automation helps, but production systems still need checks because mistakes can break systems and burn spend quickly.
Wrap-Up
The experience from Oracle is that scaling AI is not just about getting GPUs. It is about coordinating compute, data, and teams with a clean separation of concerns. Kubernetes abstracts the GPU fleet, and Airflow provides the logic plane that makes ML/AI workflows reliable, observable, and production-ready. Watch the replay to see Ashok’s end-to-end framing and the concrete Airflow patterns he recommends for GPU-heavy ML and AIOps at scale.
If you’re building AI-driven applications, download the Astronomer eBook “Orchestrate LLMs and Agents with Apache Airflow®” for actionable patterns and code examples on how to scale AI pipelines, event-driven inference, multi-agent workflows, and more.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.