Airflow in Action: How American Express Orchestrates Metadata Across 3,000 Databases
5 min read |
At the Airflow Summit, Kunal Jain, Software Architect at American Express, delivered a practical session on using Airflow to solve one of enterprise data engineering's most stubborn problems: metadata management at scale. He walked through how his team built a scalable, metadata pipeline spanning thousands of databases and data sources orchestrated by Apache Airflow®, and shared the lessons learned along the way. Whether you are wrestling with metadata staleness, heterogeneous data sources, or governance compliance, this session delivers hard-won insights you can apply directly.
Metadata Is Not Optional
Kunal opened with clear definitions that set the stage for everything that followed. Data management is the practice of managing data across its full lifecycle, from ingestion to destruction, covering quality, security, lineage, and cataloging. Data governance provides the policy framework that makes data management effective. Neither works without the other.
At the center of both is metadata. Metadata is data about data. It provides the context that makes raw data consumable and trustworthy. Kunal breaks metadata into four types:
- Technical metadata, extracted directly from physical data sources
- Declared or business metadata, defined by data owners and stewards
- Operational metadata, generated by data engineering pipelines, capturing lineage, transformation, and refresh frequency
- Monitoring metadata, produced by scanners and validators that assess data quality and sensitivity.
Without the right metadata in place, data sitting in a table means nothing to its consumers. To be able to fully use your data you need the right context for it.
3,000 Databases. One Big Problem.
American Express operates at serious scale: 3,000 on-premises databases, four data marts, and a central data warehouse with around 10,000 tables. At that scale, the challenge is not finding tools that can scan databases. The challenge is coordinating hundreds of them, reliably, across thousands of sources.
The team faced several compounding challenges. Understanding the full landscape of data spread across RDBMS, NoSQL, data marts, file stores, and data warehouses is complex enough. Add unstructured data, including files, reports, and message queues, and the problem grows significantly harder. Business metadata is particularly difficult because it depends on human knowledge that does not scale easily. Added to this constraint, metadata goes stale fast. The speed at which applications and data sources change means that without continuous, automated scanning, the metadata catalog quickly becomes unreliable.
Airflow as the Orchestration Backbone
Airflow emerged as the natural enabler. The team built a templated metadata pipeline that connects to every data source type in their environment, scans for metadata, standardizes and enriches it, identifies changes since the last scan, and publishes delta events to their metadata catalog and message queues for downstream consumers.
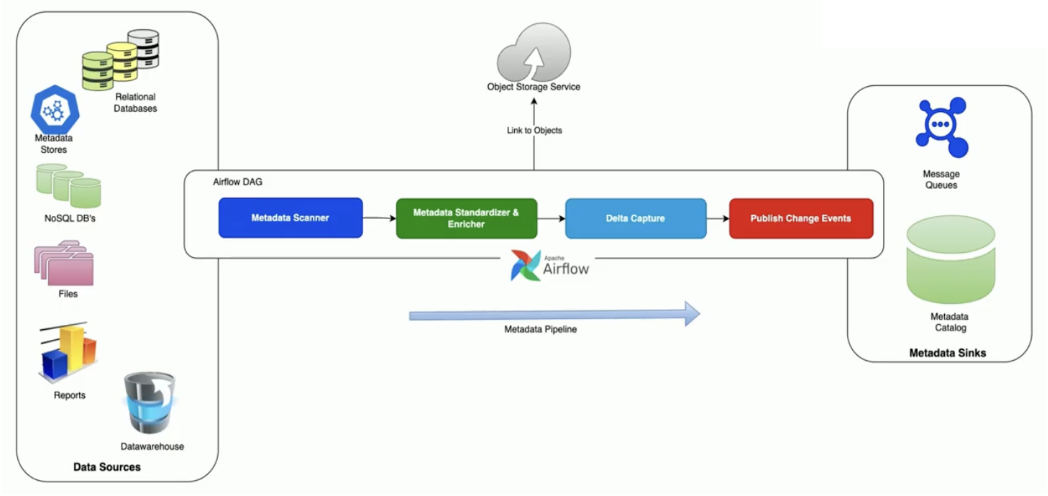
Figure 1: How Amex moves metadata: scan, standardize, capture, publish. Image source.
Custom Airflow operators sit at the heart of this architecture. The team built three different classes of custom operators, each serving a distinct purpose. Together they provide a unified, extensible framework for metadata collection across the entire enterprise.
- Technology-specific metadata operators for databases like PostgreSQL, BigQuery, and Cassandra.
- Integration operators that pull retention schedules, data quality rules, and quality scores from internal repositories.
- Scanning and profiling operators that detect sensitive data and assess data quality.
The scale of the implementation is significant. The team currently orchestrates more than 100 production metadata jobs through Airflow, ensuring continuous and reliable metadata collection across the enterprise.
Airflow 3 Makes This Even More Powerful
The current implementation is schedule-based, but the team is actively looking at Airflow 3 to take it further.
- Event-driven scheduling will allow metadata pipelines to refresh in response to real events, such as a GitHub pull request or an ETL job completing, rather than running on a fixed schedule.
- Remote execution enabled by the new task execution interface opens the door to offloading scanning to remote agents, enabling metadata extraction from sources like mainframes that cannot be reached directly by Airflow operators.
- The new human-in-the-loop operator is another capability the team is excited about, bringing data stewards directly into the pipeline to review anomalies and approve whether a run should proceed.
Key Learnings
Airflow gave American Express a scalable, standardized, and extensible foundation for enterprise metadata management, replacing fragmented tooling with a single orchestration layer that enforces policy, monitors quality, and adapts to new data sources with minimal overhead.
Watch the full session replay: How Airflow can help with Data Management and Governance to get the complete technical detail behind the architecture, the operator design patterns, and the team's roadmap for Airflow 3 adoption.
If you’re planning your move to Airflow 3, you should download our Practical guide: Upgrade from Apache Airflow 2 to Airflow 3 ebook. It walks you through every stage of the upgrade process, from understanding the new Airflow 3 architecture to using built-in upgrade tools like ruff rules and config lint, so you can plan, test, and deploy your upgrade with confidence.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.