Airflow and dbt, Hand in Hand
7 min read |
The best way to describe the relationship between Airflow and dbt might be spiritual alignment.
Both tools exist to facilitate collaboration across data teams, addressing problems — data orchestration, in Airflow’s case, and data transformation, in dbt’s — that go hand in hand. And because both orchestration and transformation have clearly defined boundaries, so too do Airflow and dbt: in a sense, each one picks up where the other leaves off. Both are vital parts of any modern data stack.
There are a lot of different ways Airflow and dbt can be used together — including options for dbt Core and, for those using dbt Cloud, a new dbt Cloud Provider, co-developed by Astronomer and the team at dbt Labs, that’s ready for use by all OSS Airflow users. The best choice for you will depend on things like the resources available to your team, the complexity of your use case, and how long your implementation might need to be supported.
But the first big decision will depend on whether you’re using dbt Core or Cloud. Let’s dive into what different implementations are available.
Airflow and dbt Core
Whether you are early on your dbt journey or a longtime user, there’s a good chance you’re already using dbt Core. Almost every data team has a workflow where data has to be ingested into the warehouse before being modeled into views for consumption, and Airflow and dbt Core can be used to see a single view of the end-to-end flow.
Airflow’s flexibility allows you to bring your own approach to the ingestion layer. You can build your own custom connector (like the Astronomer Data Team did for ingesting Zendesk data), or you can choose to go with a solution like Fivetran or Airbyte, and simply orchestrate that with Airflow.
Once the data has been ingested, dbt Core can be used to model it for consumption. Most of the time, users choose to either:
- Use the dbt CLI+ BashOperator with Airflow (If you take this route, you can use an external secrets manager to manage credentials externally), or
- Use the KubernetesPodOperator for each dbt job, as data teams have at places like Gitlab and Snowflake.
Both approaches are equally valid; the right one will depend on the team and use case at hand.
| Dependency<br />Management | Overhead | Flexibility | Infrastructure<br />Overhead | |
| dbt CLI + BashOperator | Medium | Low | Medium | Low |
| Kubernetes Pod Operator | Very Easy | Medium | High | Medium |
If you have DevOps resources available to you, and your team is comfortable with concepts like Kubernetes pods and containers, you can use the KubernetesPodOperator to run each job in a Docker image so that you never have to think about Python dependencies. Furthermore, you’ll create a library of images containing your dbt models that can be run on any containerized environment. However, setting up development environments, CI/CD, and managing the arrays of containers can mean a lot of overhead for some teams. Tools like the astro-cli can make this easier, but at the end of the day, there’s no getting around the need for Kubernetes resources for the Gitlab approach.
If you’re just looking to get started or just don’t want to deal with containers, using the BashOperator to call the dbt CLI can be a great way to begin scheduling your dbt workloads with Airflow.
It’s important to note that whichever approach you choose, this is just a first step; your actual production needs may have more requirements. If you need granularity and dependencies between your dbt models, like the team at Updater does, you may need to deconstruct the entire dbt DAG in Airflow. If you’re okay managing some extra dependencies, but want to maximize control over what abstractions you expose to your end users, you may want to use the GoCardlessProvider, which wraps the BashOperator and dbt CLI.
Unify Your Workflows with dbt on Astro Discover a seamless experience for deploying and managing dbt on Astro.
Take 30 Second TourRerunning Jobs From Failure
Until recently, one of the biggest drawbacks of any of the approaches above was the inability to rerun a job from the point of failure — there was no simple way to do it. As of dbt 1.0, however, dbt now supports the ability to rerun jobs from failure, which should provide a significant quality-of-life improvement.
In the past, if you ran 100 dbt models and 1 of them failed, it’d be cumbersome. You’d either have to rerun all 100 or hard-code rerunning the failed model.
One example of this is dbt run –select <manually-selected-failed-model>.
Instead you can now use the following command:
dbt build –select result:error+ –defer –state <previous_state_artifacts> … and that’s it!
See more examples.
This means that whether you’re actively developing or you simply want to rerun a scheduled job (because of, say, permission errors or timeouts in your database), you now have a unified approach to doing both.
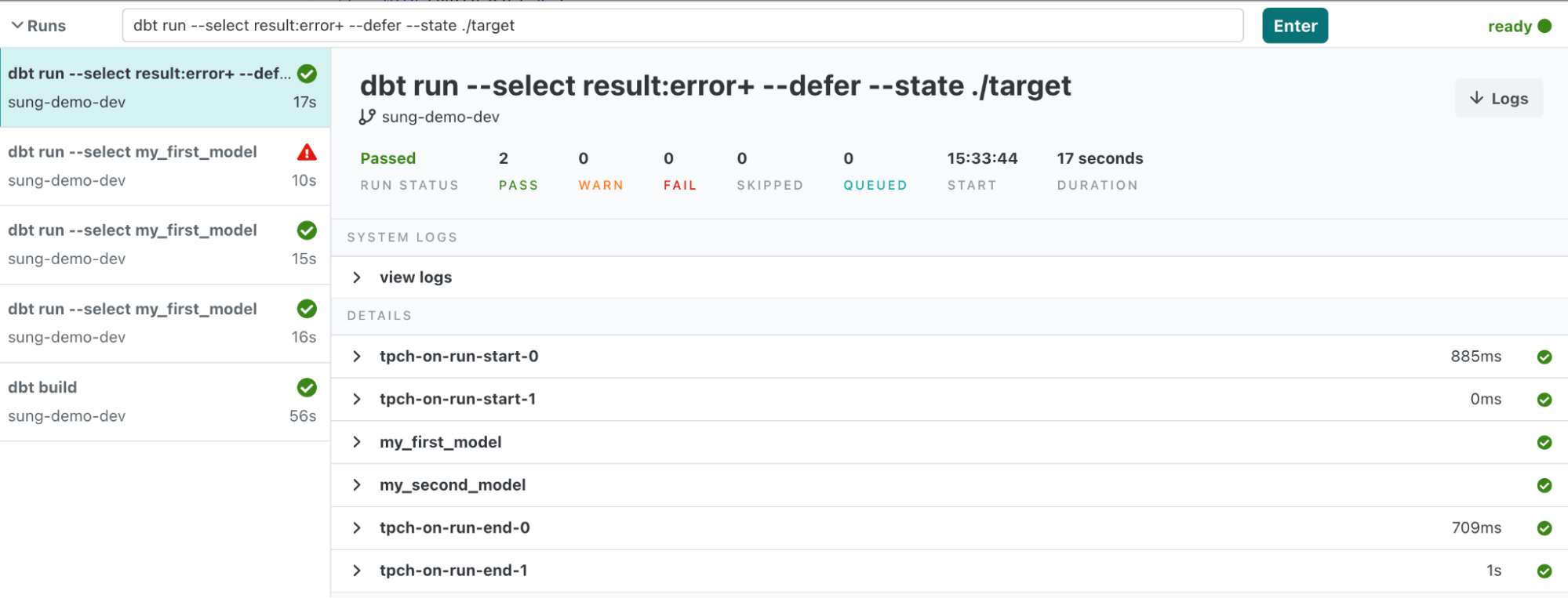
In an Airflow context, you can use this command with TriggerRules to make it so that, in the event that your initial model fails, you can keep rerunning it from the point of failure without leaving the Airflow UI. This can be especially convenient when the reason your model fails isn't related to the model code itself (permissions for certain schemas, bad data, etc.)
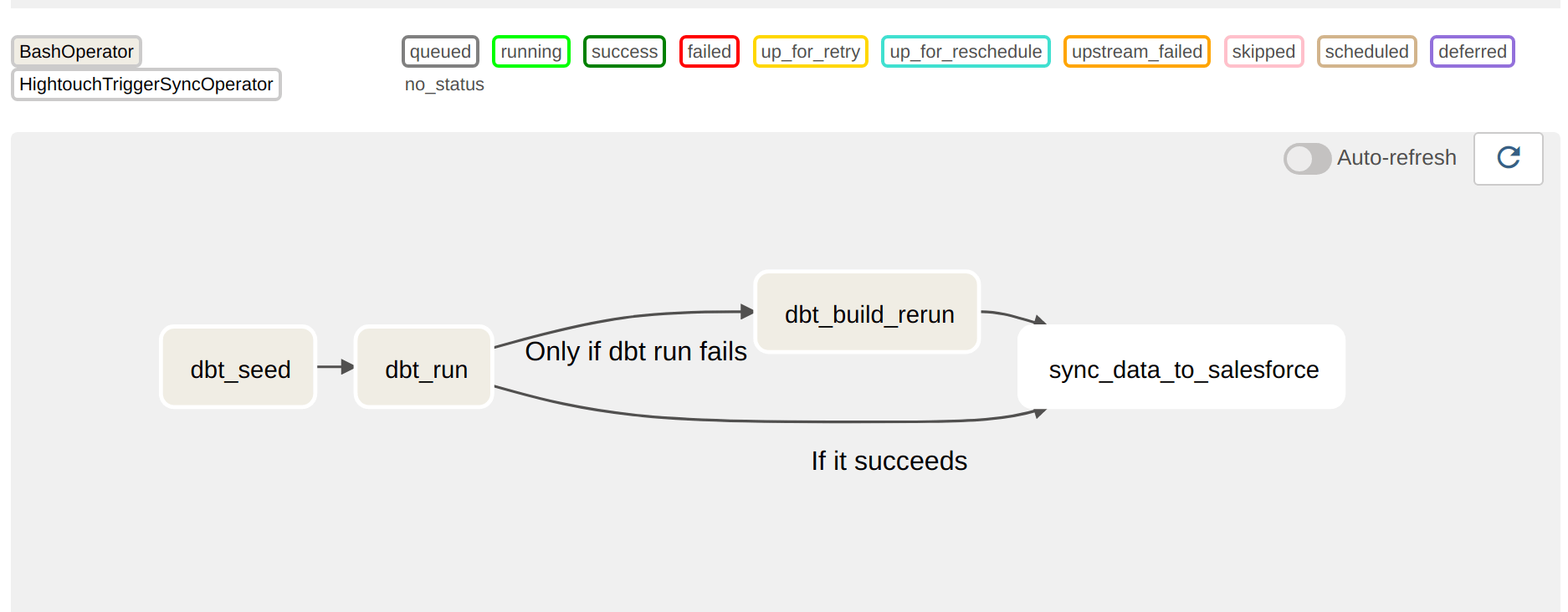
Airflow and dbt Cloud
With the new dbt Cloud Provider, you can use Airflow to orchestrate and monitor your dbt Cloud jobs without any of the overhead of dbt Core. To see how Astro can simplify this integration even further, learn more about using dbt Cloud with Astro. Out of the box, the dbt Cloud provider comes with:
- An operator that allows you to both run a predefined job in dbt Cloud and download an artifact from a dbt Cloud job.
- A hook that gives you a secure way to leverage Airflow’s connection manager to connect to dbt Cloud. The Operator leverages the hook, but you can also use the hook directly in a TaskFlow function or PythonOperator if there’s custom logic you need that isn’t covered in the Operator.
- A sensor that allows you to poll for a job completion. You can use this for workloads where you want to ensure your dbt job has run before continuing on with your DAG.
TL;DR - This combines the end-to-end visibility of everything (from ingestion through data modeling) that you know and love in Airflow with the rich and intuitive interface of dbt Cloud.
To set up Airflow and dbt Cloud, you can:
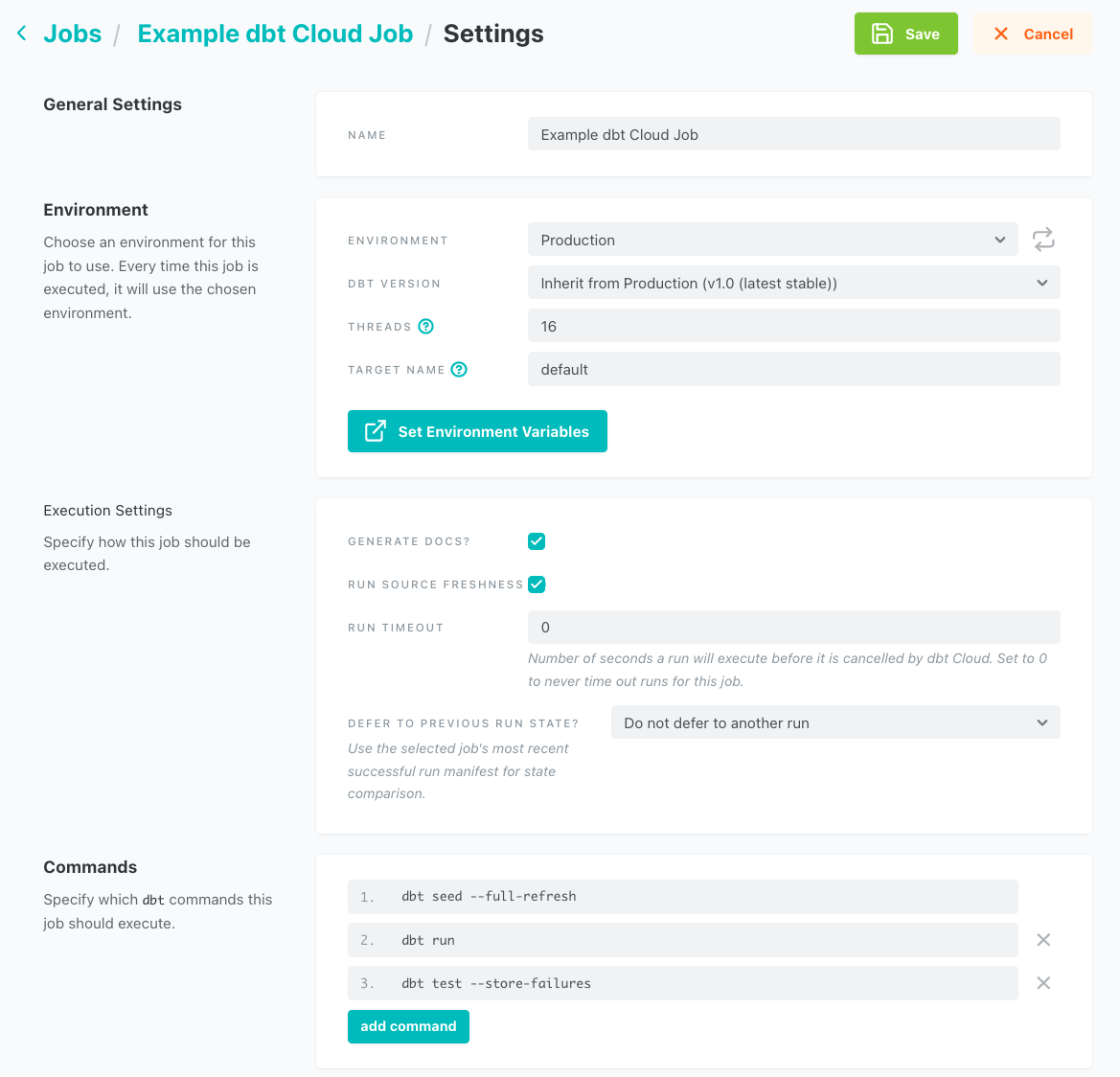
- Set up a dbt Cloud job, as in the example below.
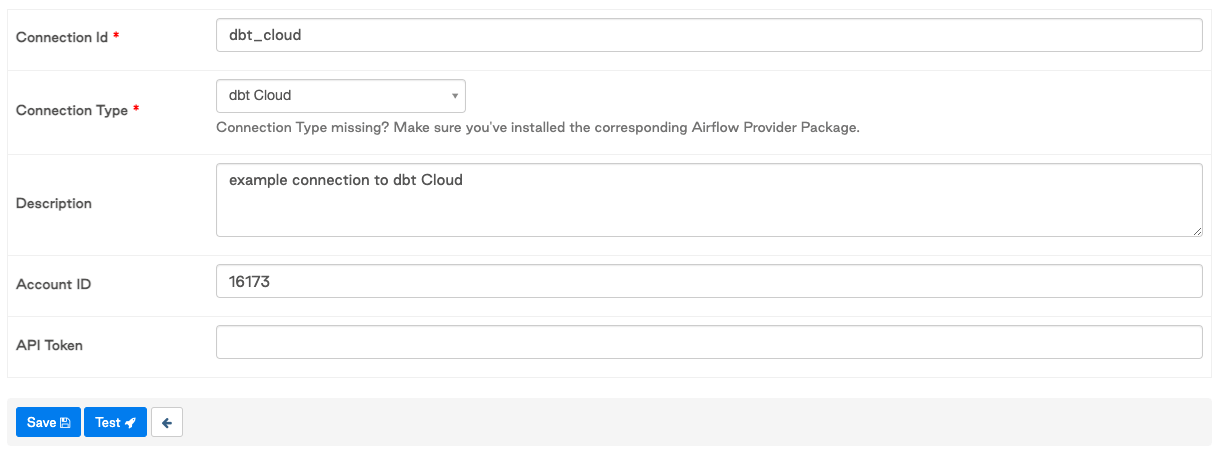
- Set up an Airflow Connection ID
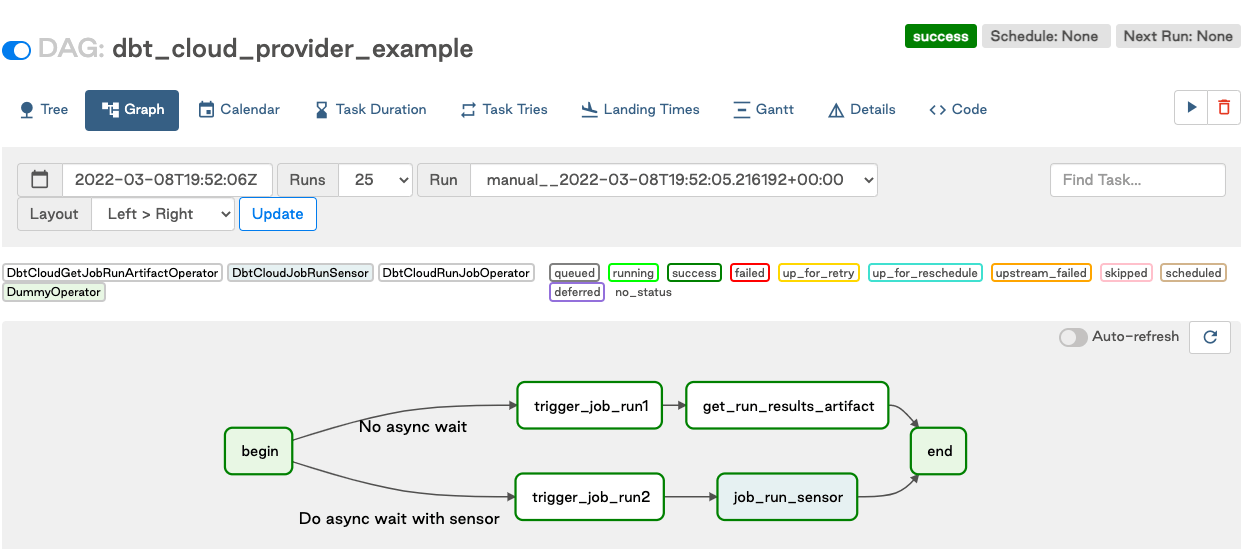
- Set up your Airflow DAG similar to this example.
- You can use Airflow to call the dbt Cloud API via the new
DbtCloudRunJobOperatorto run the job and monitor it in real time through the dbt Cloud interface.
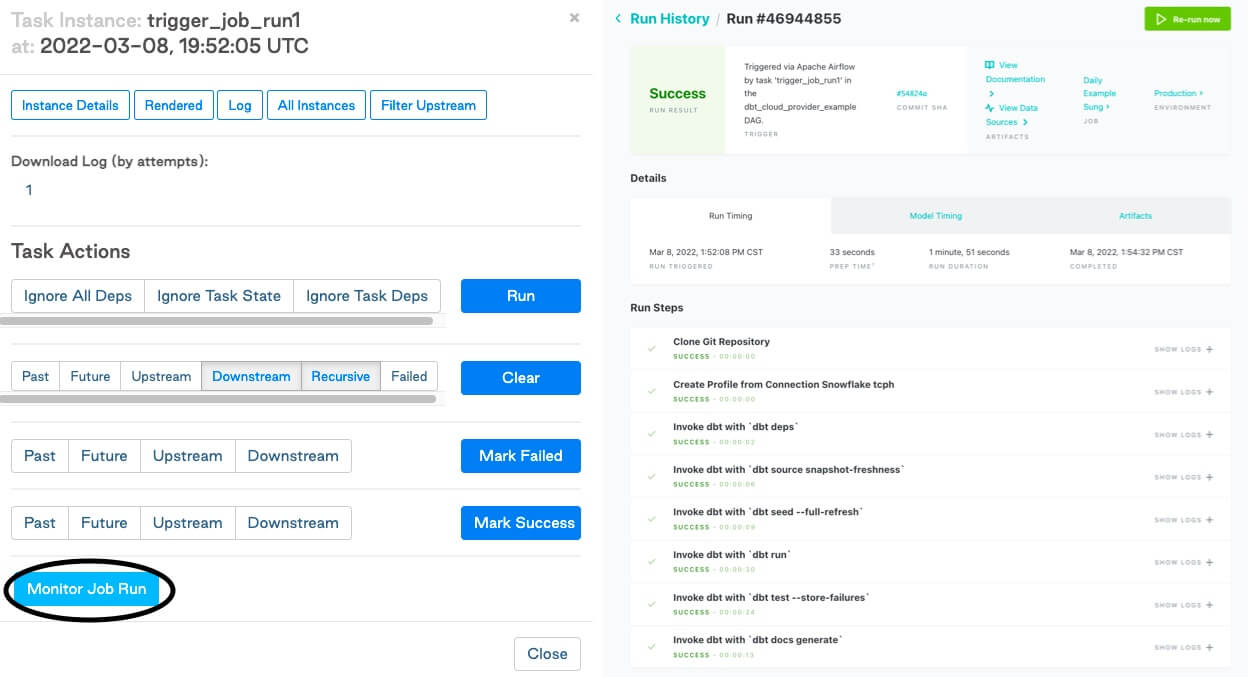
If your task errors or fails in any of the above use cases, you can view the logs within dbt Cloud (think: data engineers can trust analytics engineers to resolve errors).
Conclusion
Bringing Airflow and dbt together helps form a common interface between data analysts and data engineers. Data engineers have the flexibility to express the ingestion layer of their pipelines and monitor the analyst-defined transformation layer from a single pane of glass. Data analysts can write their dbt models with confidence and transparency as to the state and freshness of the data. These two tools are an “and” story for a robust, modern data platform, not an “or.” The new dbt Cloud provider takes that even further, and allows data teams to focus on their DAGs and models, instead of on infrastructure or maintaining API calls.
If you want to learn more about how to incorporate Airflow into your modern data platform, contact Astronomer's experts.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.