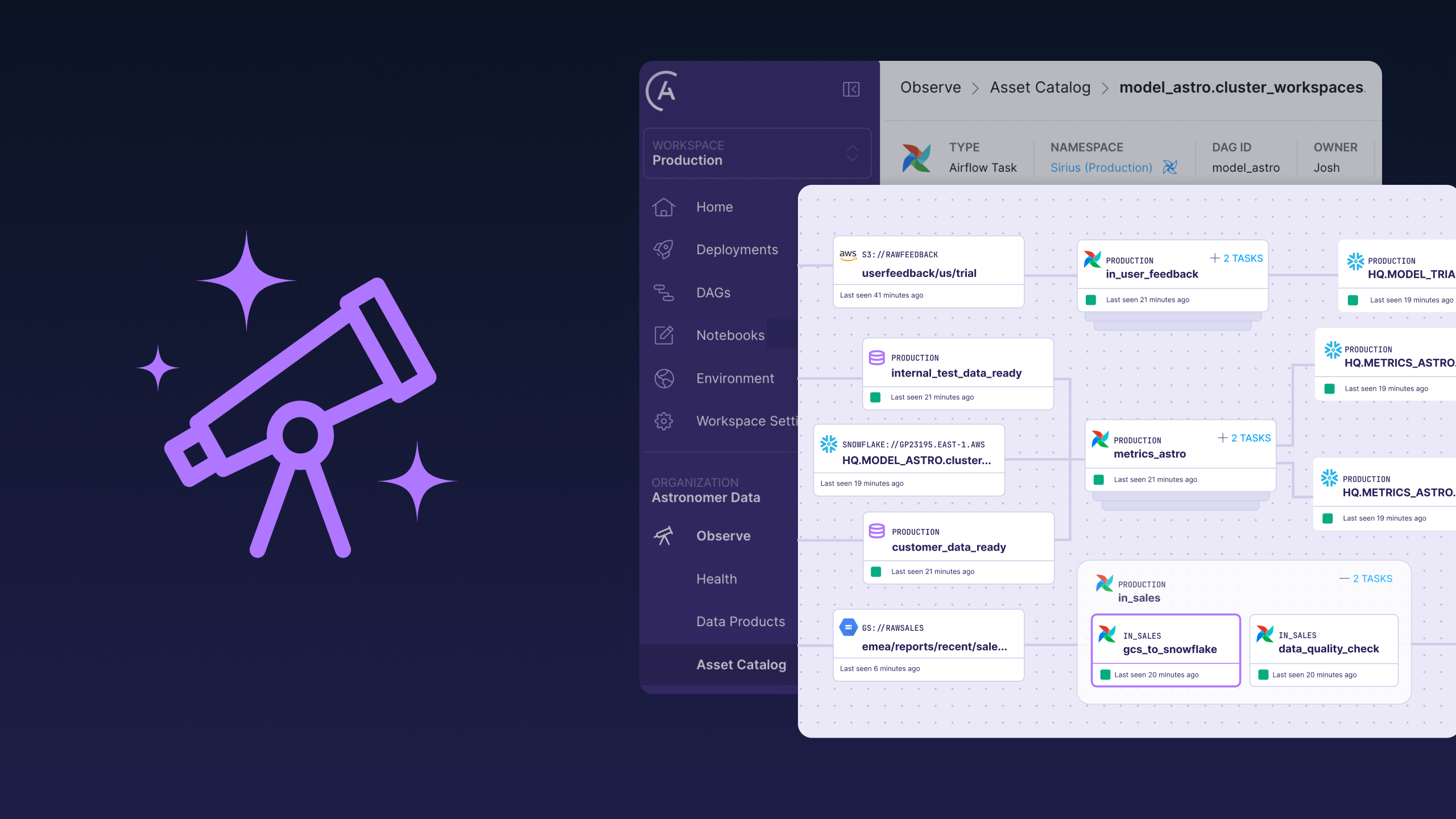
Supercharge dbt Orchestration with Astronomer Cosmos and Apache Airflow®
Cosmos 1.11.0a1 introduces alpha support for dbt Fusion—the next-generation dbt engine that unlocks lightning-fast parsing, state-aware orchestration, and real-time validation, all orchestrated natively in Airflow.