What Is DataOps?
DataOps is an approach to data engineering that applies agile, DevOps-style practices to how data pipelines are built, run, and monitored. It combines workflow orchestration, automation, testing, and observability to help data teams deliver reliable data products faster and at greater scale.
As data becomes the foundation for AI, applications, and analytics, the pressure on data teams has never been higher. DataOps gives those teams the operational discipline and tooling to meet that demand without burning out or breaking things.
According to Gartner’s 2025 Market Guide for DataOps Tools, DataOps is evolving into a foundational enabler for AI readiness, driven by the increased need for optimized data pipelines to support AI initiatives and growing analytic use cases.
The DataOps Definition: What It Covers and Why It Matters
Defining the Modern Practice
DataOps orchestrates the full data lifecycle: ingestion, integration, transformation, quality monitoring, governance, and delivery. It sits above the data compute layer and turns raw inputs from source systems, operational apps, databases, sensors, logs, APIs, into reliable, trusted data products ready for consumption by downstream AI models, applications, and analytics tools.
It does this through a combination of:
- Workflow orchestration to automate and sequence complex data pipelines
- Continuous integration and testing to catch errors before they reach production
- Real-time observability and lineage tracking to maintain data quality and trust
- Governance controls to ensure compliance and accountability
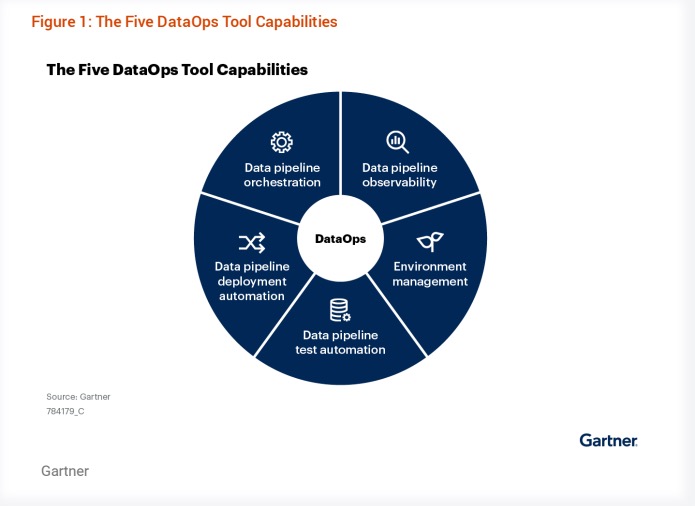
Figure 1: DataOps tools address capabilities across five critical areas: data pipeline orchestration, data pipeline observability, environment management, data pipeline test automation, and data pipeline deployment automation.
DataOps vs. DevOps: What’s the Difference?
DevOps transformed software engineering by bridging the gap between development and operations. DataOps applies that same philosophy to data work, but addresses challenges that are unique to data: volume, latency, completeness, lineage, and integration across a fragmented tool ecosystem.
Where DevOps ships code, DataOps ships data products.
DataOps in the Age of AI and Agents
AI models and autonomous agents are only as reliable as the data feeding them. As enterprises move from AI experimentation to production deployment, the data layer has become the make-or-break factor.
DataOps is what makes that data layer production-ready. Specifically, it addresses three critical requirements that AI and agentic workloads introduce:
1. Continuous, High-Quality Data Pipelines
AI models degrade when trained or served on stale, incomplete, or inconsistent data. DataOps automates the ingestion, validation, and transformation steps that keep data pipelines running reliably in production, ensuring models always have access to accurate, up-to-date inputs.
2. Context for AI Agents
Agents don’t just need access to data. They need context: where the data came from, how it was transformed, what it means, and whether it can be trusted. DataOps platforms with rich metadata, lineage, and observability capabilities give agents the grounding they need to take accurate, reliable actions.
This is why orchestration is increasingly central to agent architectures. Orchestration knows what data exists, where it lives, how it flows, and how it is being consumed. That context is the foundation for agents that can act intelligently on data without human intervention.
3. Operational Scale and Reliability
AI workloads are demanding. Training jobs, real-time inference pipelines, and multi-step agentic workflows place extreme load on data infrastructure. DataOps provides the elastic compute management, resource observability, and pipeline reliability needed to run these workloads in production without constant manual intervention.
The bottom line: Organizations that struggle to move AI projects from prototype to production often have a DataOps problem before they have an AI problem. The models are ready; the data infrastructure is not.
Why DataOps? The Challenges It Solves
Despite data being more abundant than ever, most enterprises still struggle to turn it into reliable, actionable products. The root causes are consistent:
- Fragmented data environments: Siloed, fragmented environments where legacy on-prem systems collide with cloud-native stacks, creating duplicate datasets, ownership gaps, and a lack of cohesive standards.
- Limited skills and capacity: Skills constraints that leave data engineers juggling heavy backlogs and suboptimal tooling, leading to slower delivery and missed innovation opportunities.
- Tooling sprawl and maintenance overhead: Non-differentiated toil driven by patching together disparate tools, which sinks budget and engineering hours into complex configurations instead of business value.
- Flying blind on data quality: Lack of visibility without robust observability and governance, making it difficult to ensure quality, track lineage, or measure the business impact of data products. This opens the door to poor-performing AI, costly errors, and added risk of regulatory and compliance issues.
The Benefits of DataOps
By adopting DataOps practices, data engineering teams can achieve:
Higher Development Agility
DataOps streamlines the development lifecycle by automating testing, deployment, and continuous integration, allowing teams to respond to change faster. It breaks down silos between data engineering, software, and ML teams, accelerating the pace of innovation.
Faster and More Predictable Data Delivery
Automated orchestration and monitoring ensure pipelines are faster, more scalable, and more consistent in performance. Predictable pipeline behavior reduces bottlenecks and minimizes downtime, even during peak demand.
Better Data Quality, Trust, and Governance
DataOps integrates quality controls, lineage tracking, and real-time observability into the data lifecycle. Combined with granular cost and resource insights, this creates a governance model that data consumers can trust, and that finance teams can account for.
Orchestration: The Foundation of a DataOps Platform
A DataOps strategy is only as strong as the layer that unifies it. That layer is workflow orchestration. And not just any orchestration, it needs to be independent, cross-stack, and built for the full breadth of your data and AI environment.
Orchestration connects to all tools and data sources across the stack. It knows where data comes from, where it is going, how it is being used, and what happened when something went wrong. This deep integration and contextual awareness makes orchestration the ideal control plane for the entire DataOps layer — and increasingly, for AI agents that need cross-system context to operate reliably.
Why Localized Orchestrators Are a Strategic Dead End
Every major data platform vendor, Snowflake, Databricks, and others, has shipped a native orchestrator. These tools are easy to adopt inside their ecosystems, and that is precisely the problem.
Localized orchestrators, by design, can only see within their walled garden. A renewal agent, for example, might need to pull from your CRM, ticketing system, data warehouse, Slack, and semantic layer in a single decision flow. No single-platform orchestrator can see across all of those systems. And because it can only see fragments, it can only capture fragments of the context that AI needs to act reliably.
An independent orchestration layer is infrastructure. Like your network or your identity provider, it needs to work across everything, not just within one vendor’s boundaries. That is what makes it a durable foundation for DataOps and for the AI era ahead.
Why Other Tool Categories Fall Short as a Foundation
Teams often ask whether data cataloging, observability, transformation, or integration tools can serve as the DataOps control plane. Each plays a valuable role, but none has the cross-stack context needed to anchor a full DataOps strategy:
- Data cataloging: Provides a passive view of data assets. Valuable for visibility, but limited for operational control at scale.
- Data observability: Surfaces what is happening to data, but typically cannot intervene or control pipeline execution in response.
- Data transformation: Handles one stop in the lifecycle and is often SQL-centric, with limited awareness of upstream or downstream context.
- Data integration: Moves data well, but only addresses one part of the lifecycle with no understanding of how data is consumed downstream.
- Platform-native (localized) orchestrators: Tightly integrated with a single vendor’s ecosystem. Easy to start with, but unable to capture cross-system context and strategically constraining as AI workloads require multi-platform coordination.
Apache Airflow: The Industry Standard for DataOps Orchestration
Apache Airflow is the most widely adopted orchestration platform in the world. With over 3,000 contributors (more than Apache Spark and Apache Kafka combined). It is central to data operations at many of the world’s most innovative companies.
Airflow is downloaded over 30 million times every month. What began as a tool for data engineers is now critical infrastructure for AI and ML engineers, software developers, and platform teams running production AI workloads, MLOps pipelines, and real-time analytics at scale.
Astro: A Unified Orchestration Platform Built on Airflow
Astro is Astronomer’s managed unified orchestration platform for Apache Airflow. It serves as the unified control plane for every data and AI workflow across your stack, from ETL and operational analytics to ML pipelines and autonomous agents. Astro brings development, execution, and monitoring together in a single platform, so your team spends less time on infrastructure and more time shipping.
For teams adopting or scaling a DataOps strategy, Astro provides:
- Astro Build: Developer tooling that enables engineers across data, ML, and software teams to build, test, and deploy data products on Airflow up to 10x faster — including AI-assisted Dag authoring and in–browser testing with native CI/CD.
- Astro Run: The Astro engine 2x the performance of other Airflow solutions, providing reliable, elastic, secure, multi-tenant pipeline delivery across hybrid and multi-cloud environments, with detailed cost and usage reporting.
- Astro Observe: Full visibility and governance across the pipeline lifecycle with lineage, data product SLA tracking, data quality, proactive monitoring and AI-assisted troubleshooting and RCA.
Astro also provides day-zero access to Airflow 3 features with 1-hour SLA-backed expert support. Customers, from startups to Fortune 100 enterprises, trust Astro to run their most critical data and AI pipelines.
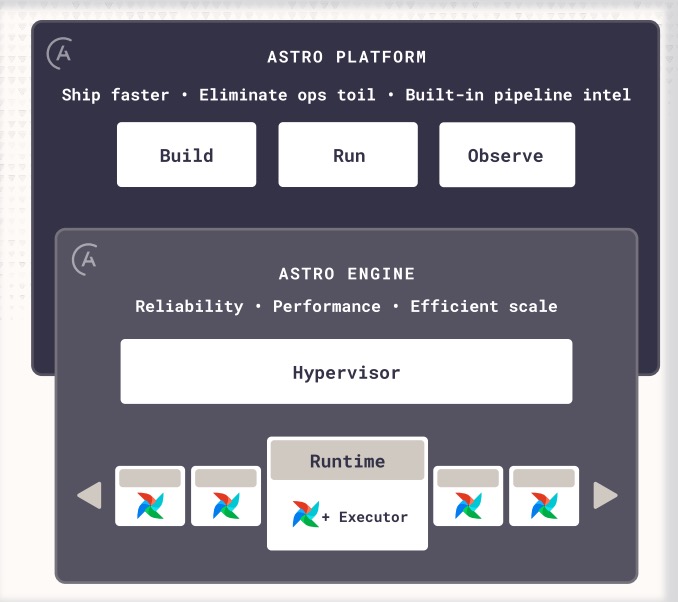
Figure 2: Astro combines a hardened execution engine with an intuitive platform for building, running, and observing your most critical data and AI pipelines.
DataOps in Action: Customer Stories
Northern Trust: Modernized Financial Data Operations
Managing $1.5 trillion in assets, Northern Trust was hampered by fragmented data workflows and poor pipeline visibility. Late failure detection caused recurring data quality issues and delayed delivery of critical financial data. Astronomer centralized their pipelines and added real-time monitoring and automated alerting, dramatically reducing manual troubleshooting and improving data reliability.
Autodesk: Cloud Transformation in 12 Weeks
Autodesk’s legacy orchestration tools couldn’t keep up with the complexity of their cloud data workflows, resulting in frequent pipeline errors and slow deployment cycles. After migrating to Astronomer, they completed the transformation ahead of schedule with no long-tail issues, achieved 90% fewer data errors, and accelerated code deployment by 33%.
Building a DataOps Strategy: Where to Start
Organizations that succeed with DataOps typically follow a phased approach:
- Evaluate your current state. Identify where pipeline fragmentation, data quality issues, or lack of visibility are creating the most drag on your team.
- Pilot on high-value use cases. Start with foundational workloads like ETL or data delivery where the impact is immediate and measurable.
- Scale and standardize. Bring in more complex workloads such as ML/AI Ops and formalize DataOps practices through a Center of Excellence.
Getting Started with Astronomer
Whether you’re on legacy schedulers, self-managing Airflow, or ready to standardize orchestration across your organization, Astronomer meets you where you are. No rip-and-replace, just faster time-to-value with proven playbooks and hands-on support from the team that drives Airflow development.
Frequently Asked Questions
What is DataOps?
DataOps is the practice of applying agile and DevOps-like principles to data engineering. It automates and streamlines data workflows, from ingestion through transformation and delivery, using orchestration, continuous integration, observability, and governance controls to produce reliable, high-quality data products faster and at scale.
What is a DataOps platform?
A DataOps platform is a unified set of tools that automates and governs the full data product lifecycle. It typically includes workflow orchestration, pipeline monitoring, lineage tracking, and developer tooling, all integrated into a single operational layer above the data compute layer. Astro, built on Apache Airflow, is an example of a managed DataOps platform.
Why is DataOps important for AI?
AI models and autonomous agents depend on continuous access to accurate, well-governed data. DataOps ensures that data pipelines are reliable, that data quality is monitored in real time, and that the metadata context needed by AI agents is maintained. Without a solid DataOps foundation, AI initiatives frequently stall in prototyping and fail to reach production.
How does DataOps differ from DevOps?
DevOps focuses on software delivery: shortening the cycle between writing code and running it reliably in production. DataOps applies similar principles to data work but addresses challenges specific to data, including volume, timeliness, lineage, and cross-tool integration. Where DevOps ships code, DataOps ships data products.
What problems does DataOps solve for data teams?
DataOps addresses fragmented data environments, manual and error-prone pipeline management, limited visibility into data quality and lineage, and the toil of maintaining disparate tooling. By automating and centralizing data operations, it reduces downtime, cuts costs, and accelerates the delivery of AI, analytics, and application use cases.
Why is orchestration the foundation of DataOps?
Orchestration connects across all tools and data sources in the stack, giving it a unique cross-system view of how data flows, where it comes from, and how it is consumed. This makes it the most capable control plane for a DataOps strategy. Other tool categories, including data catalogs, observability tools, transformation tools, and integration tools, play important roles but each addresses only one slice of the data lifecycle without the broader operational context that orchestration provides.
What is the difference between DataOps and data engineering?
Data engineering is the discipline of building and maintaining data pipelines and infrastructure. DataOps is the operational practice that governs how that work is done, emphasizing automation, collaboration, continuous delivery, and quality controls. DataOps is to data engineering what DevOps is to software engineering.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.