Watch the recording


What is Data Lineage?
Data lineage starts with a desire to build a healthy data ecosystem within an organization — one that can span the team boundaries that develop as the company grows. Team A on one platform produces datasets, team B consumes some of those datasets and produces additional datasets, and team C are outside stakeholders.
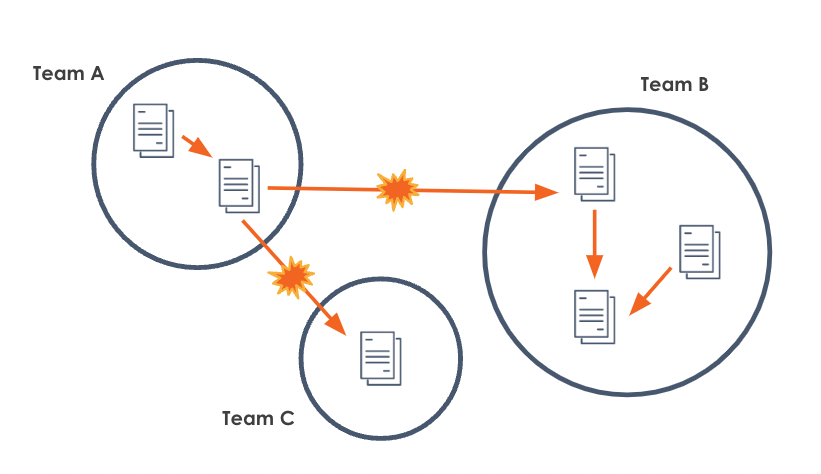
As a record of the producers and consumers of each dataset, and the inputs and outputs of each job, data lineage contains what you need to know to solve some of the most complicated problems in data engineering.
Different Approaches to Data Lineage
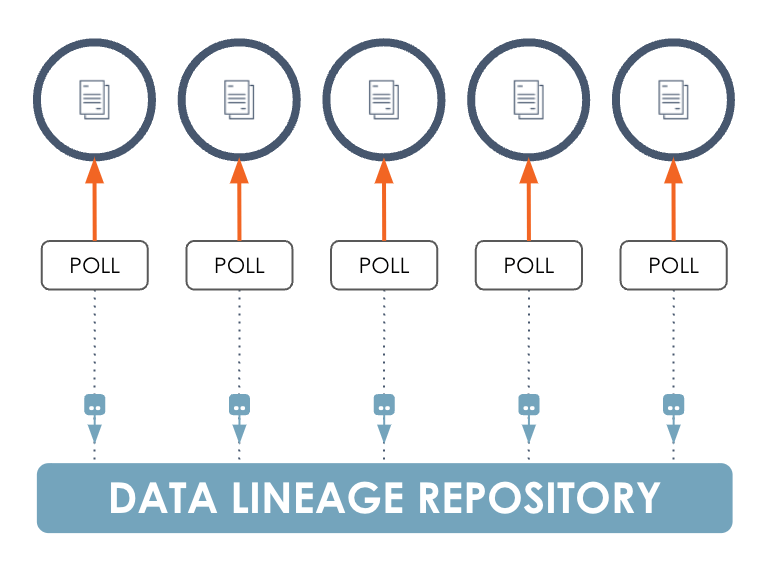
Forensic data lineage
With this approach, you integrate with data stores and warehouses to learn what queries were executed and which datasets they consumed or produced. An agent regularly polls the data store, gathers metadata, and sends everything back to a lineage metadata repository.
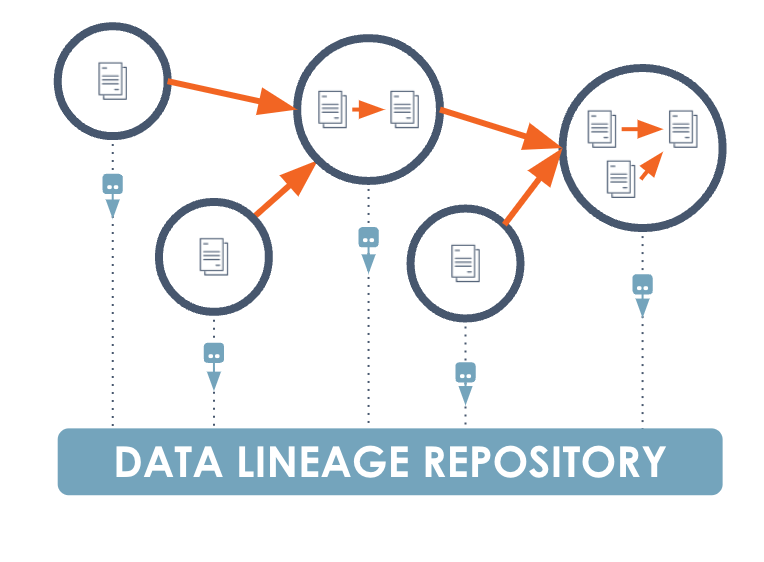
Operational data lineage
With operational data lineage, you integrate with the data orchestration system and, as jobs run, you observe the way they affect data. These integrations also send their observations to a central lineage metadata repository for reporting.
What Data Lineage Makes Possible
Data lineage creates all sorts of higher-order possibilities, including:
- Dependency tracing
- Root cause identification
- Issue prioritization
- Impact mapping
- Precision backfills
- Anomaly detection
- Change management
- Historical analysis
- Compliance
Studying Lineage in Heterogeneous Pipelines
OpenLineage is an open standard for collecting lineage metadata from pipelines as they are running, operating as an observer of the relationships between consumers and producers of information. It serves as a lingua franca for talking about data lineage across the entire industry.
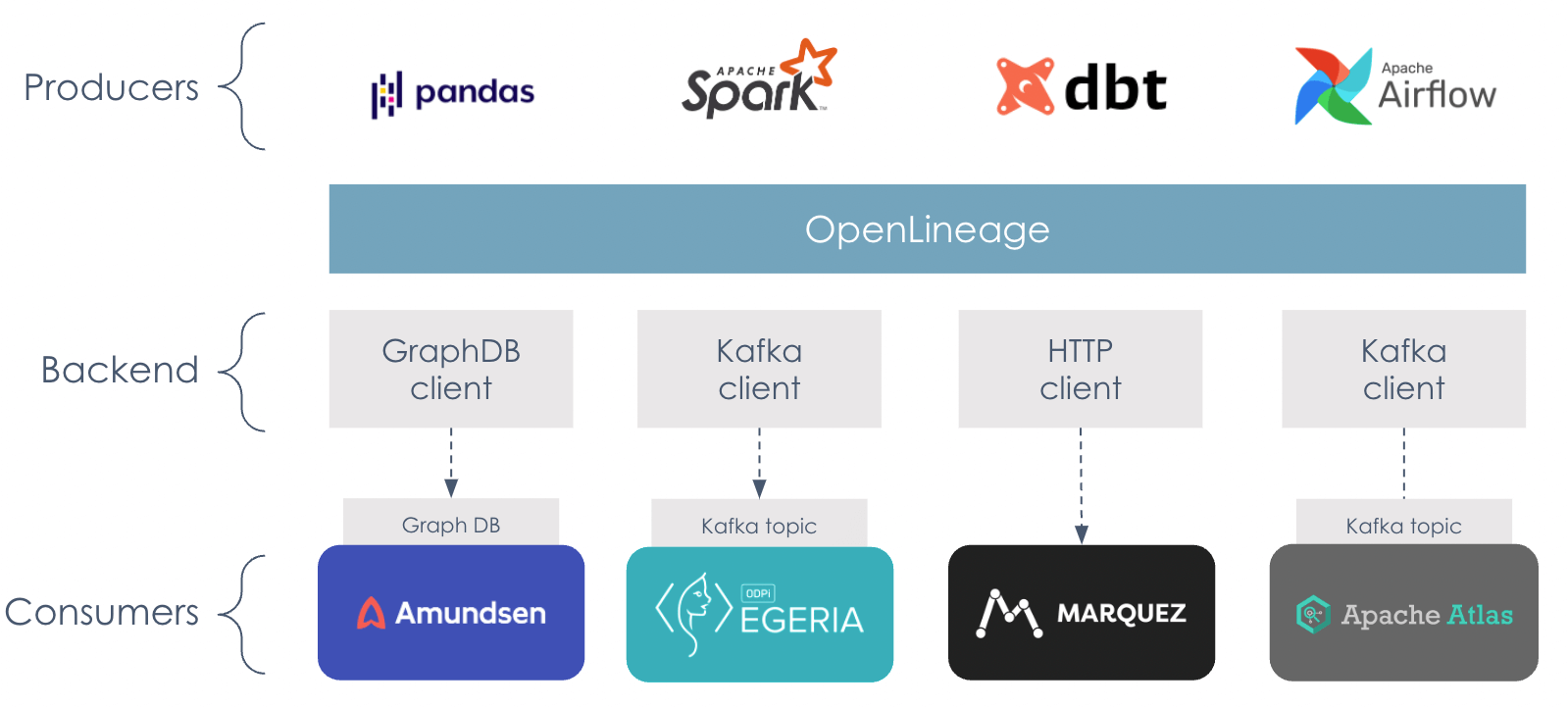
How Does OpenLineage Work?
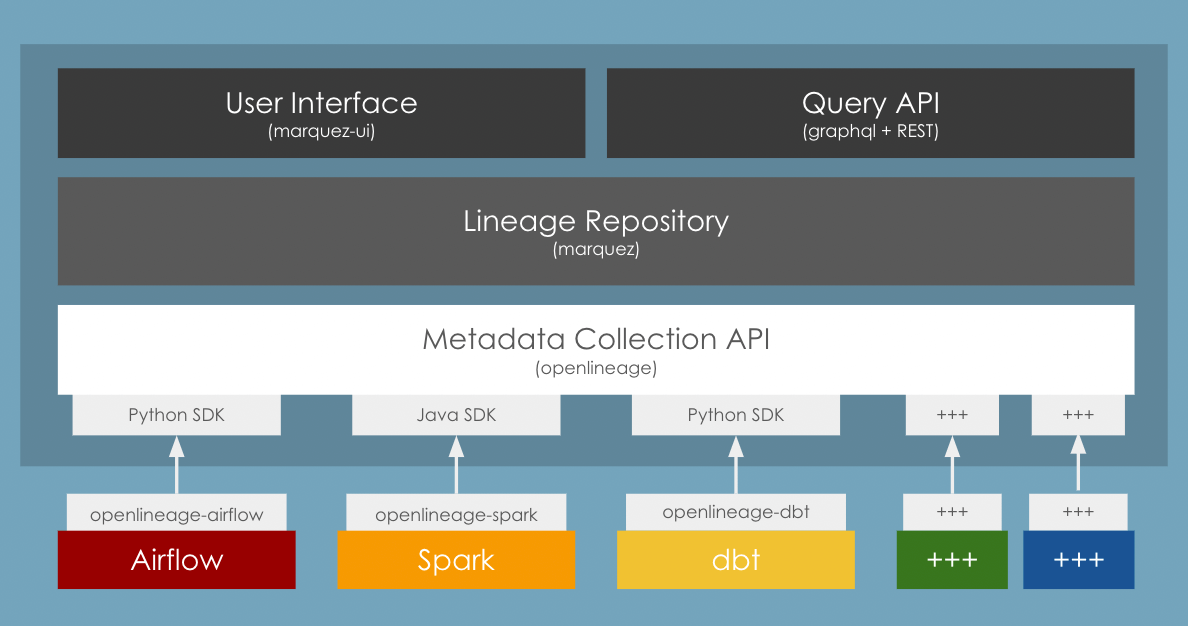
The OpenLineage Stack
The elements of the OpenLineage stack:
Data model
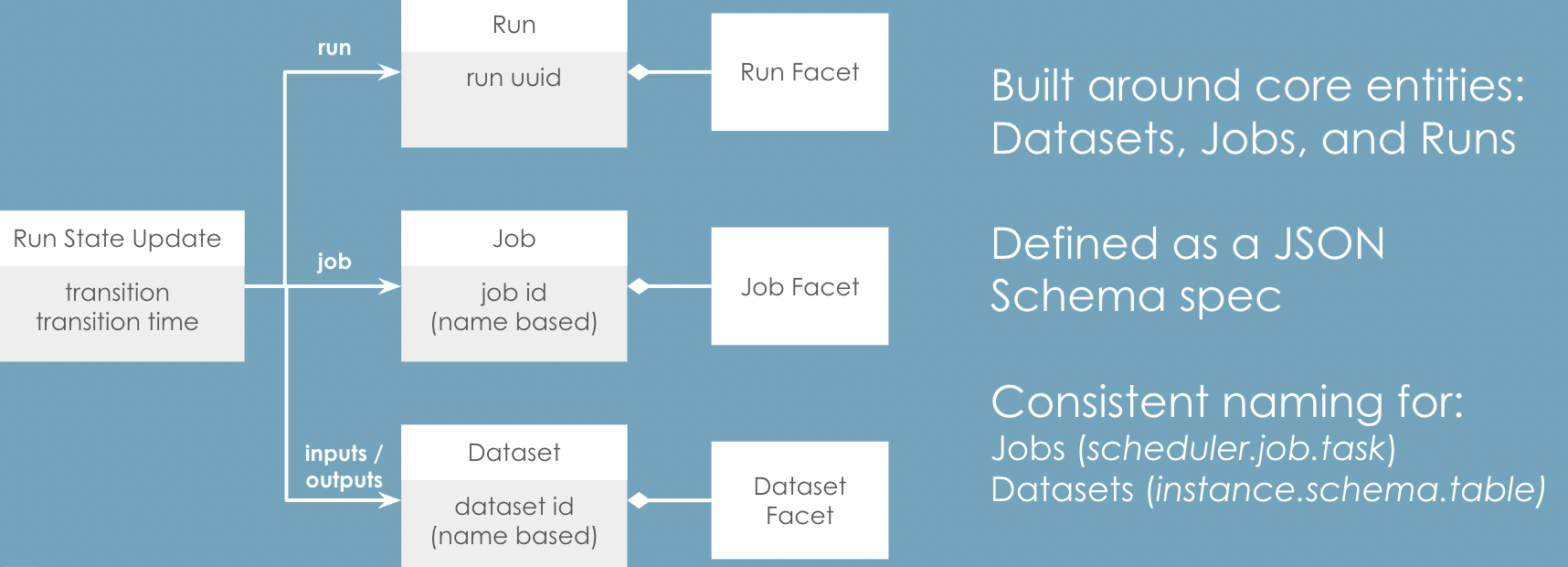
OpenLineage metadata is communicated through a series of lineage events known as run state updates. The data model is built around three major kinds of entities: datasets, jobs, and runs.
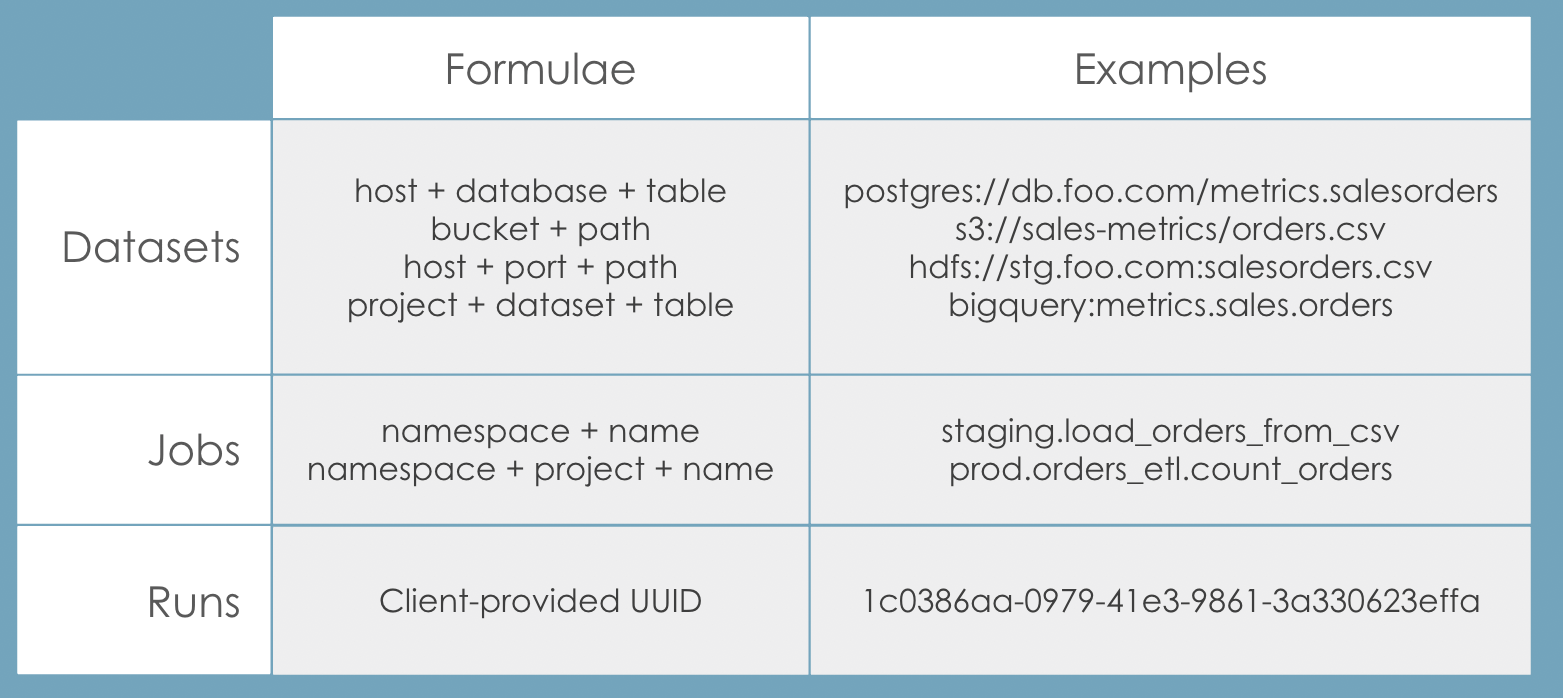
There are conventions for producing different names for datasets, jobs, and runs.
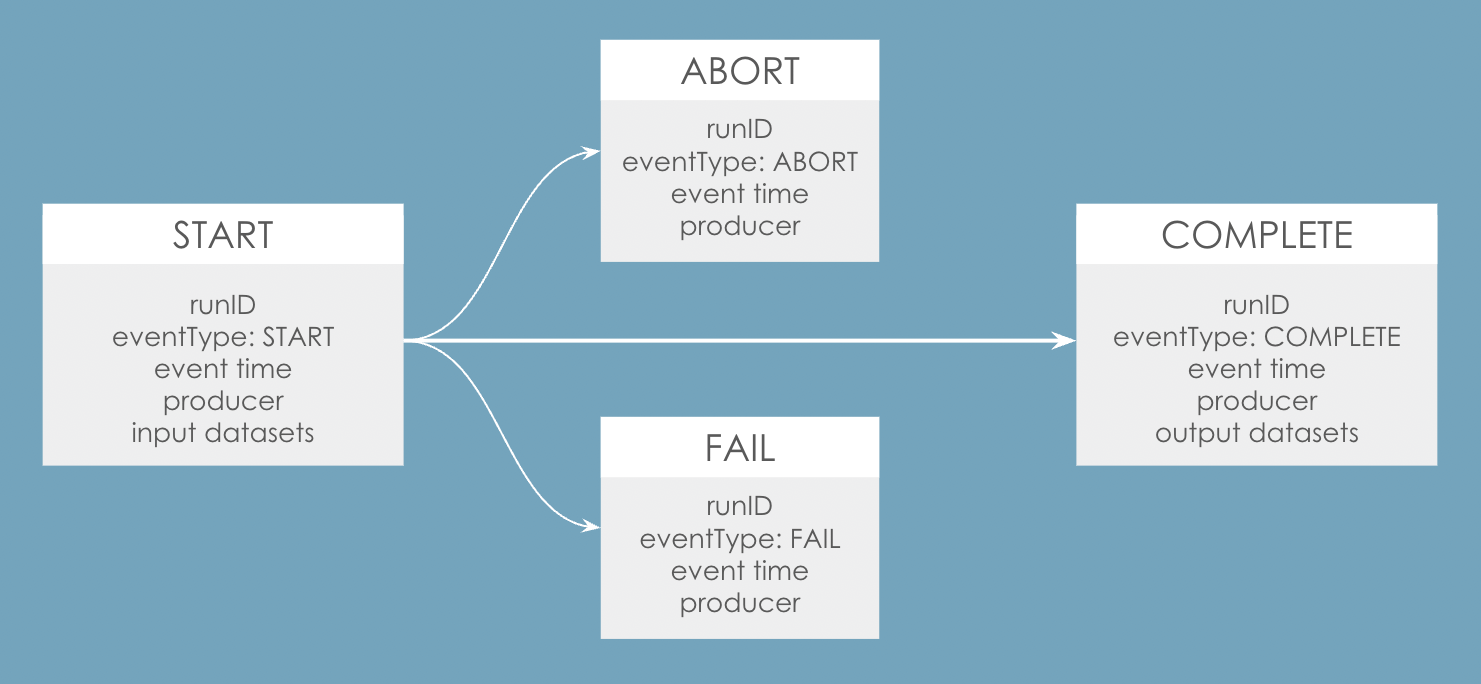
Lifecycle of a job run
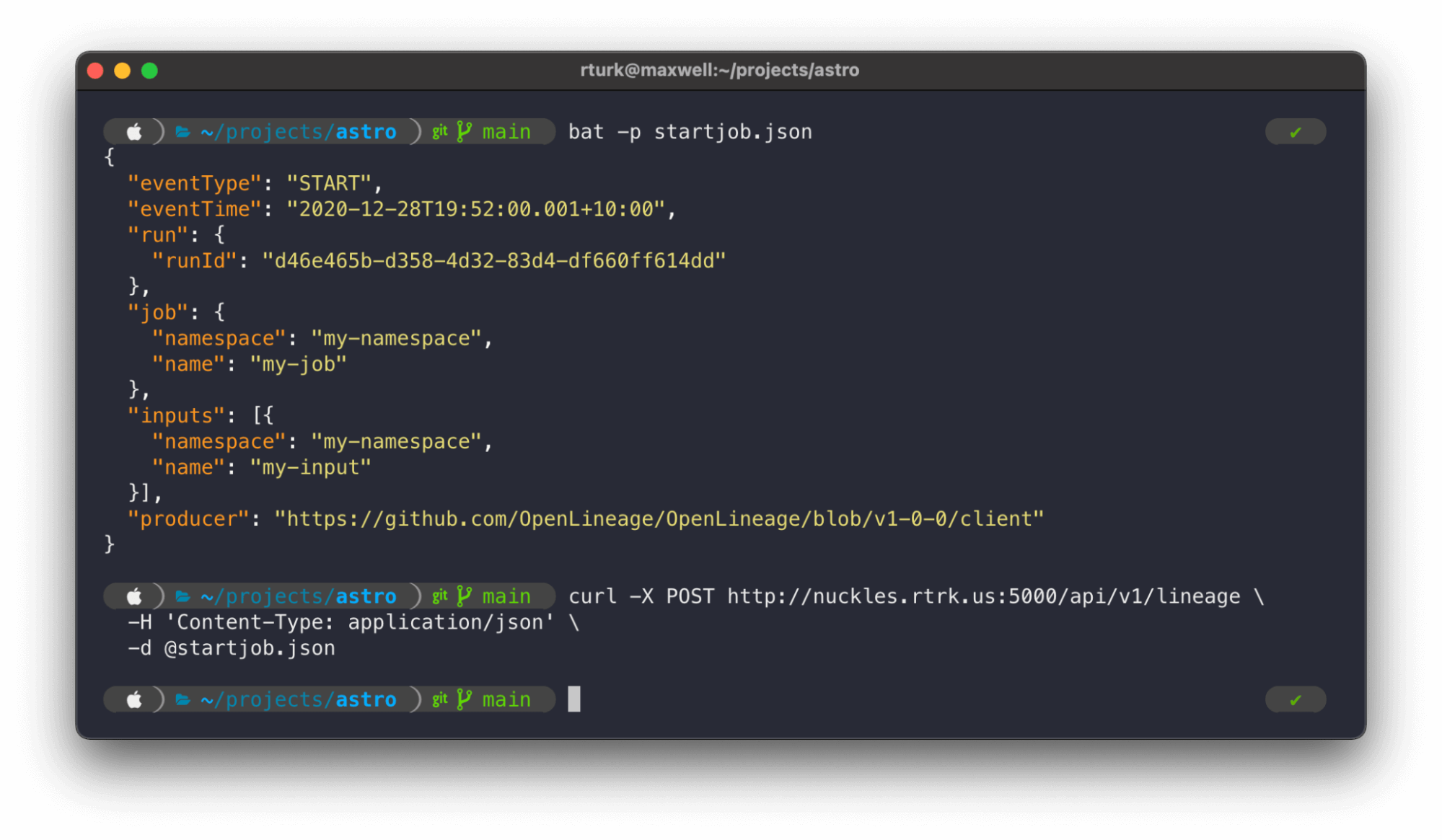
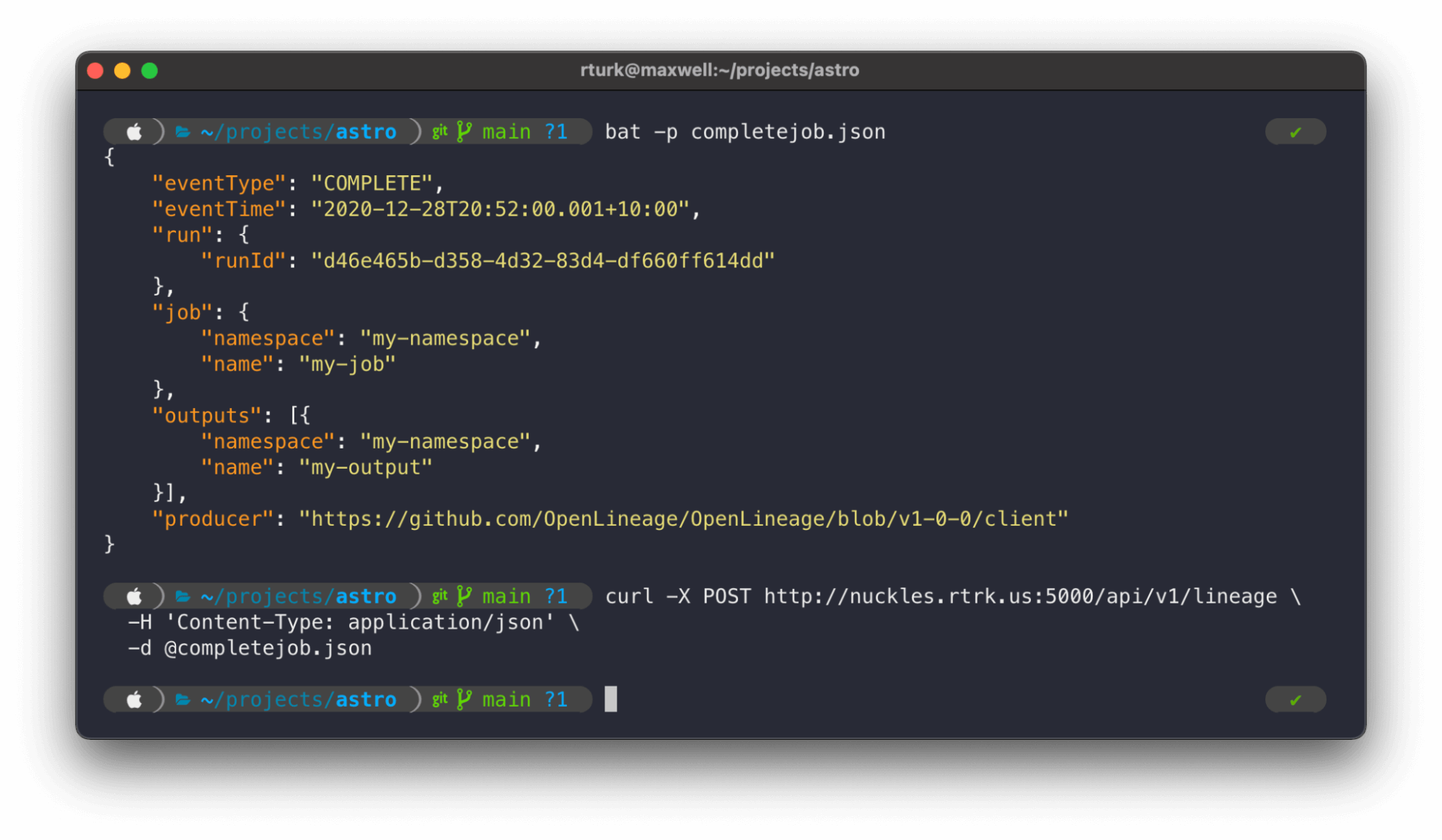
Typically, a job run contains at least two lineage events: a START and a COMPLETE. You can also ultimately send an abort or a fail if something goes wrong with the job.
Extending the data model with facets
Facets are atomic pieces of metadata attached to core entities which:
- Can be given unique, memorable names
- Are defined using JSON schema objects
- Can be attached to any core entity: job, dataset, and run
Facet examples:

An example OpenLineage run event
- Starting a job run
- Completing a job run
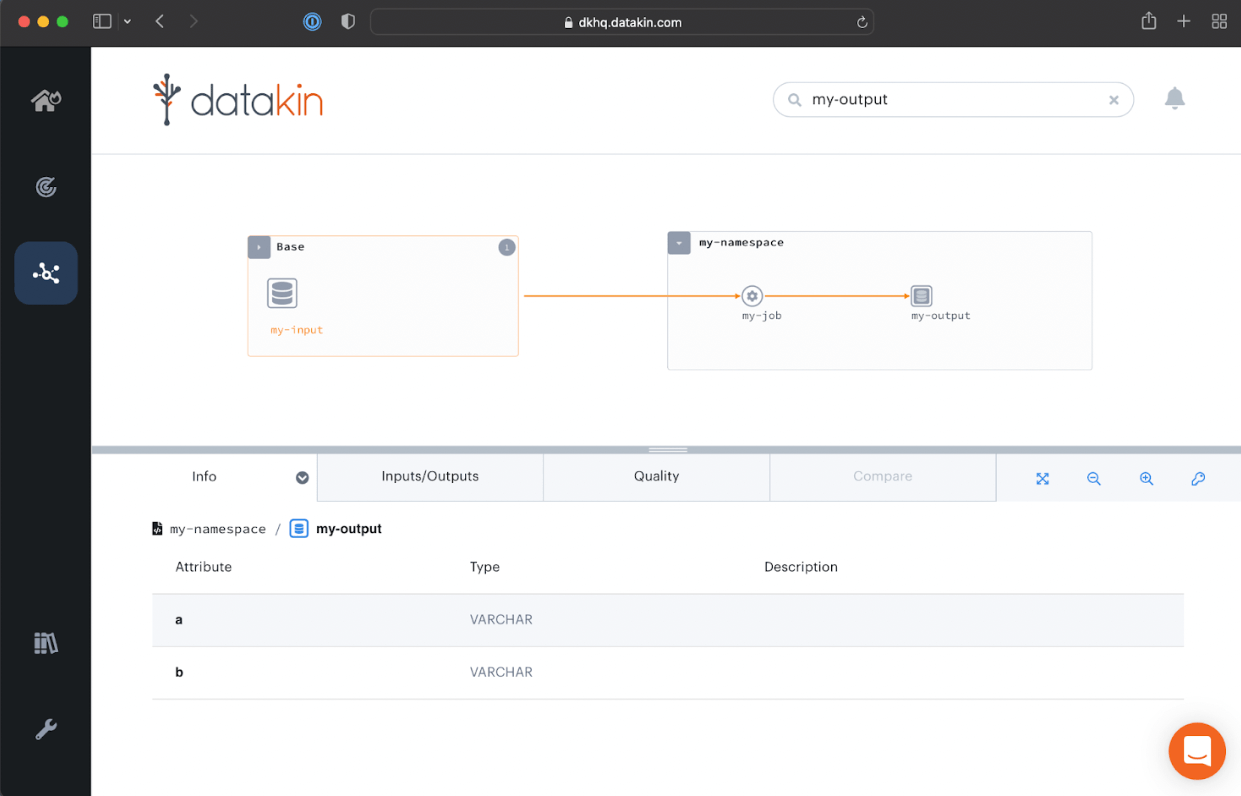
- Viewing a job run
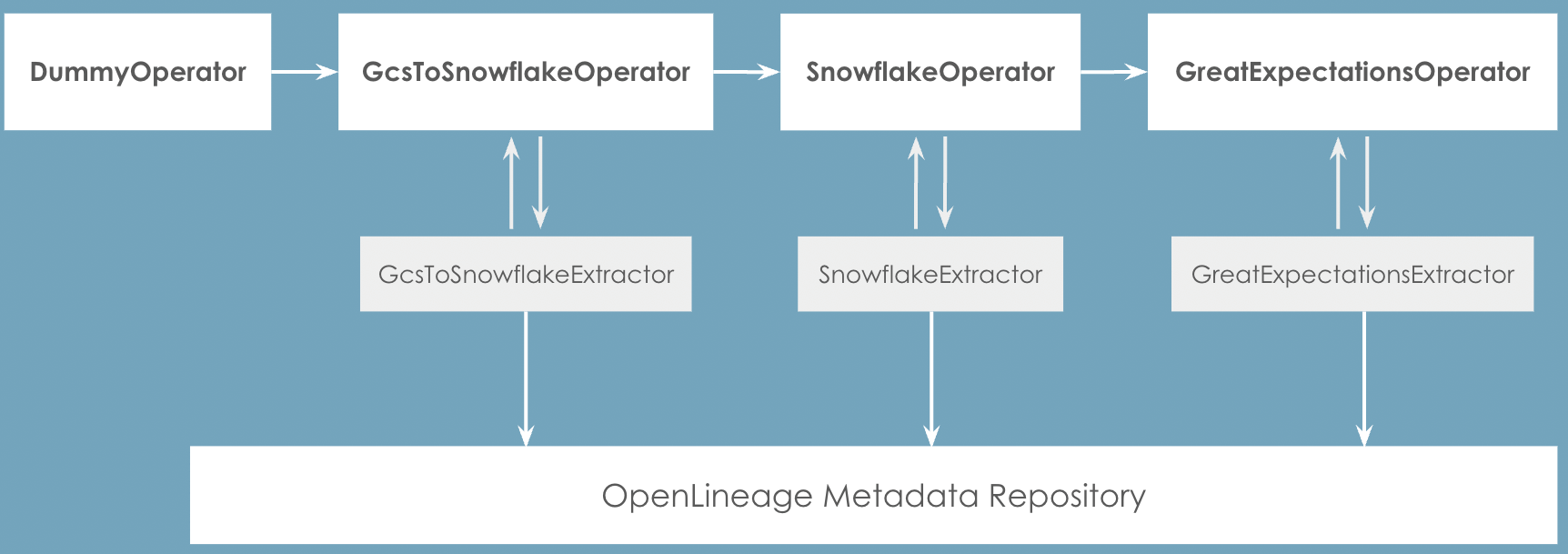
How OpenLineage Works With Airflow
OpenLineage works with Airflow using a series of extractors, each one designed to observe a specific Airflow operator. Because Airflow operators are so flexible and powerful, it’s difficult to develop a single mechanism that would extract lineage out of them all. There are extractors available for several common operators, but it is still early in the development of this integration.
How to enable the integration depends on whether you’re using Airflow 2.1+, Airflow 1.10+, or Astro Cloud.
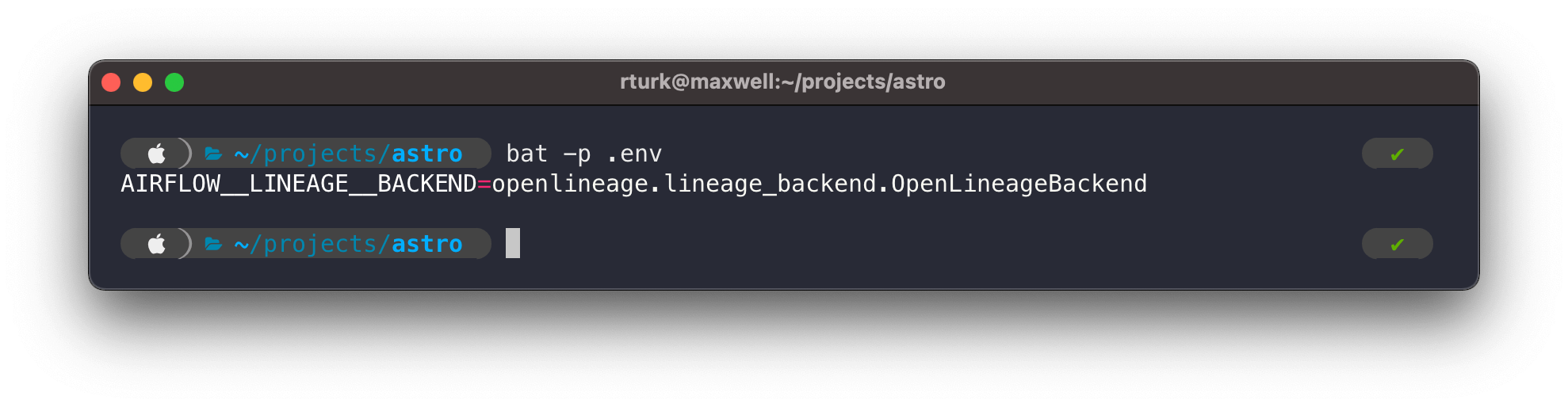
Airflow 2.1+: set an environment variable to specify the lineage back end as the open lineage back end
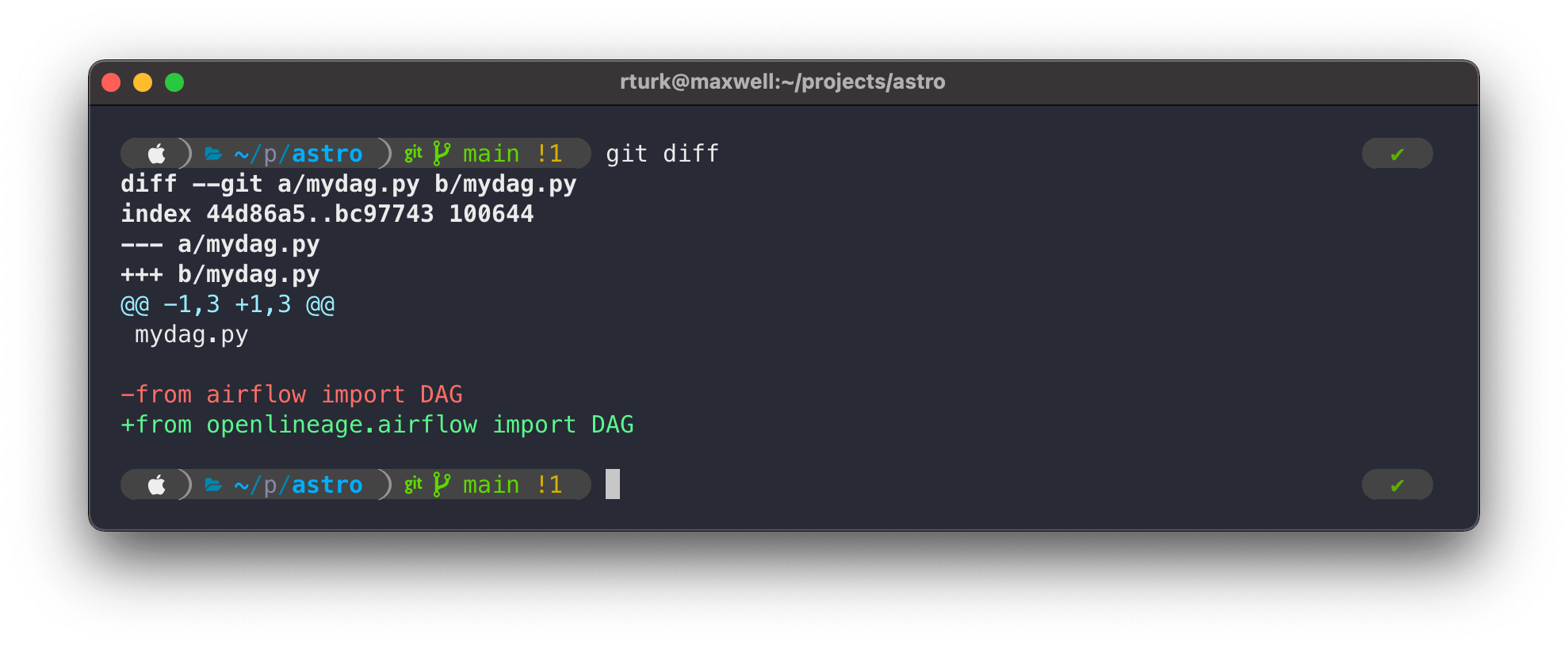
Airflow 1.10+: override the DAG import
Astro Cloud: if you’re using the latest version of the Astro Runtime on Astro Cloud, you don’t need to do anything — OpenLineage integration is already configured
Building a Custom Extractor
If you want to extract lineage from an Airflow operator that does not currently have an extractor — perhaps for a custom operator you have written yourself — it can be implemented by extending BaseExtractor and registering your extractor using an environment variable.
- New extractor registering
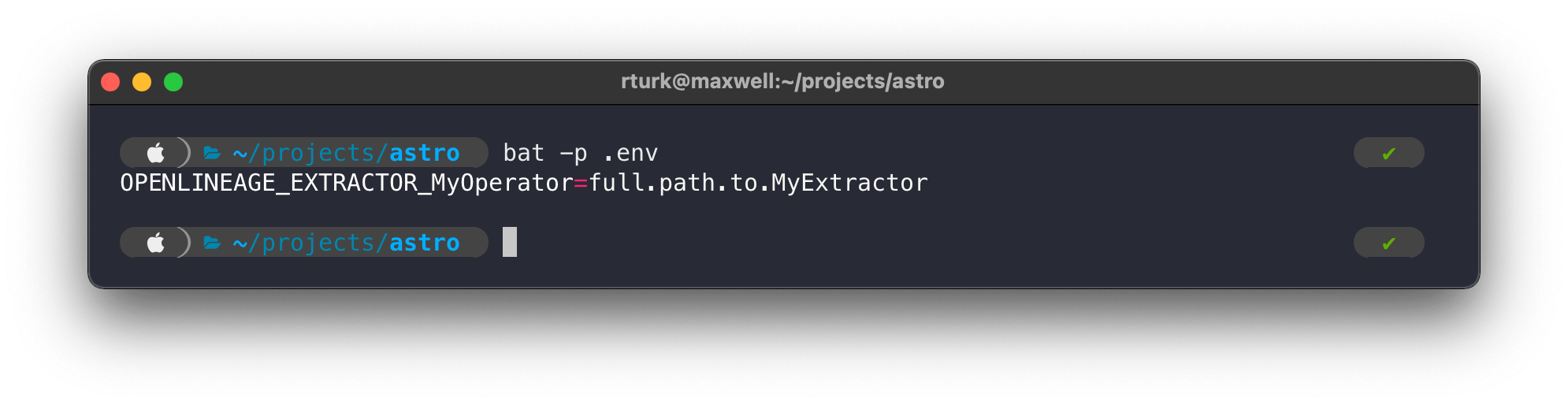
- Extractor building

Code examples Go to Code 1 and Code 2 to learn more about extractors and see how they work.
To learn more about how Astronomer brings together Airflow and OpenLineage, connect with us here.
Related Content:
