Watch the recording


Note: For additional information check out the OpenLineage and Airflow: A Deeper Dive webinar.
Community links:

groups.google.com/g/openlineage
Part 1: OpenLineage
1. The need for lineage metadata
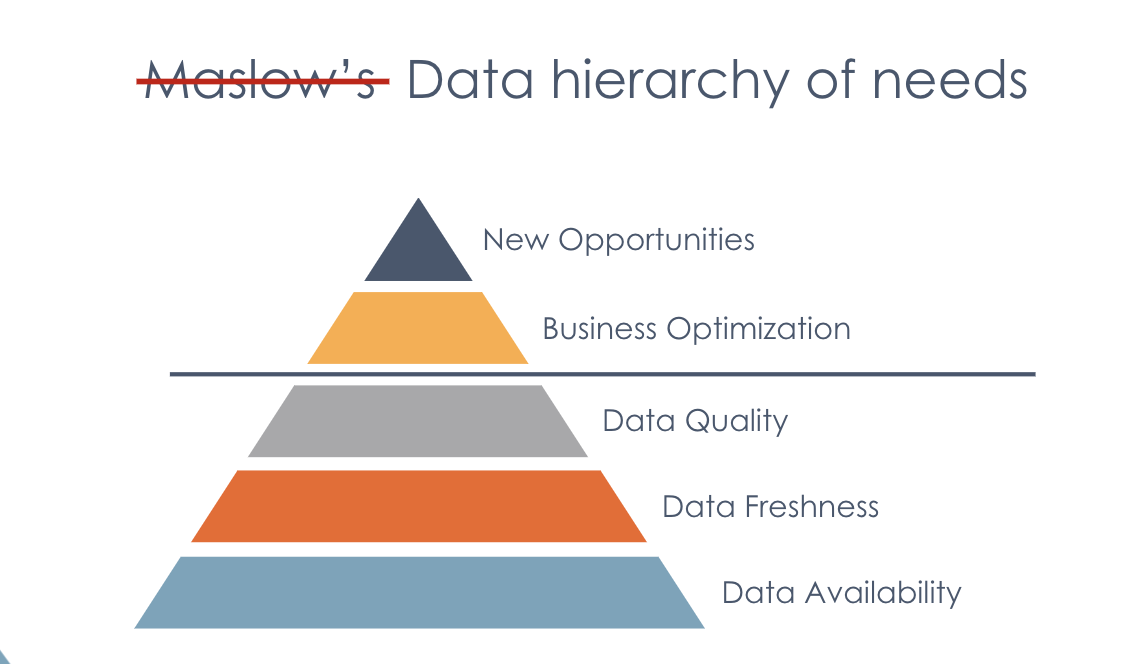
How do we go about building good data inside of an organization?
Data availability, freshness, and quality are fundamental capabilities, required as a base layer to achieve higher-order business benefits.
An organization consistently supplied with good data can begin to methodically optimize and improve its processes, look for anomalies in the data that can lead improvements and better business results.
2. Building a healthy data ecosystem
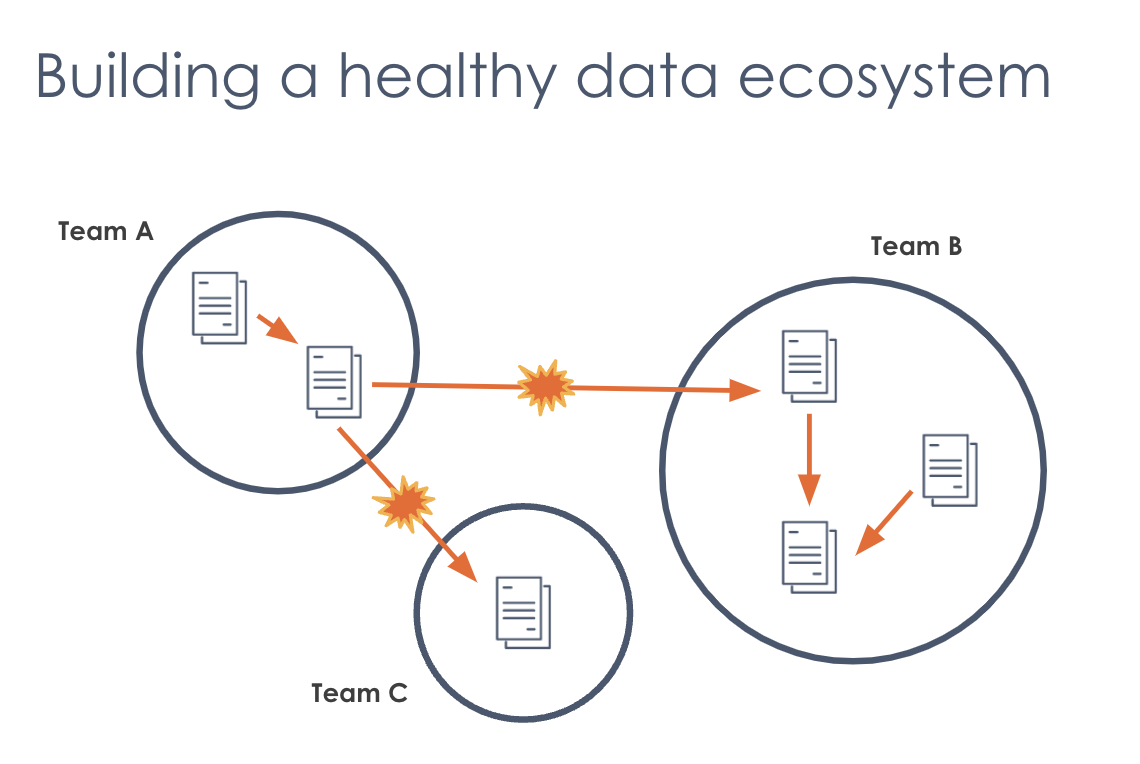
But it's not super easy to build a healthy data ecosystem!
The result of data democratization (which is otherwise a terrific thing) is fragmentation, as in the picture above. This creates opportunity for conflict. A healthy data ecosystem in a properly functioning organization looks like a somewhat fragmented, chaotic mess that provides both opportunity and challenge.
3. Challenge: limited context
Having a fragmented data ecosystem with the potential for organic growth in an organization is beneficial, but it also creates a data "black box."
It can be difficult to find information such as:
- What is the data source?
- What is the schema?
- Who is the owner?
- How often is it updated?
- Where does it come from?
- Who is using it?
- What has changed?
The solution to this challenge is data lineage.
4. What is data lineage?
Data lineage is the set of complex relationships between datasets and jobs in a pipeline.
- Producers & consumers of each dataset
- Inputs and outputs of each job
Practically speaking, data lineage should be something very visual, like a map of your data pipeline that helps you understand how datasets affect one another
5. OpenLineage
First and foremost, OpenLineage is a community.
Contributors:

There's a lot to gain by having the entire industry work together to establish a standard for lineage, and OpenLineage is exactly that: a lingua franca for talking about how data moves across different tools.
6. The purpose of Open Lineage
PURPOSE: To define an open standard for the collection of lineage metadata from pipelines as they are running.
The best moment to capture context about a dataset is when that dataset is created. So OpenLineage observes jobs to capture data lineage as they run (as opposed to attempting to reconstruct it afterward from the information left behind).
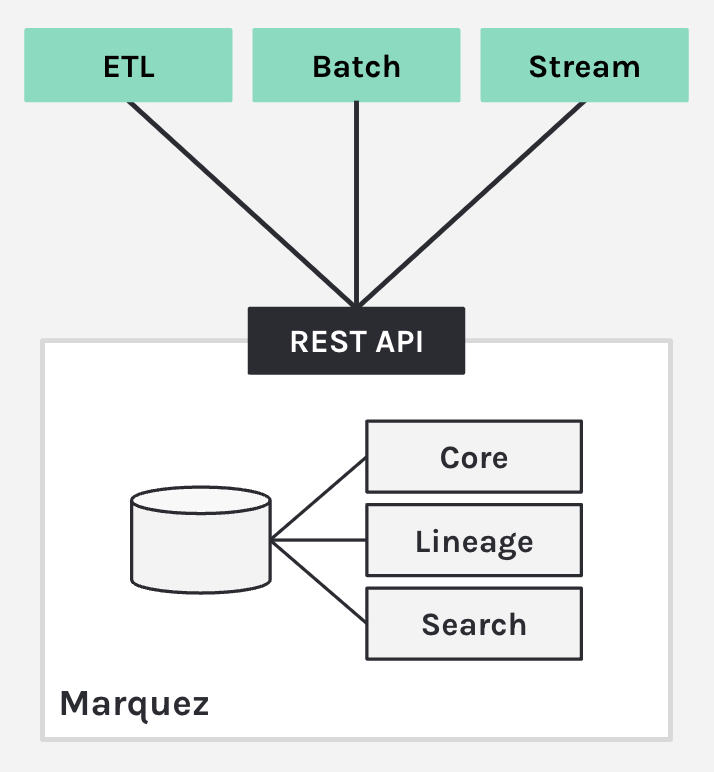
7. OpenLineage architecture
The OpenLineage architecture was designed to capture real-time data lineage for operational use cases, and work with all kinds of different tools.
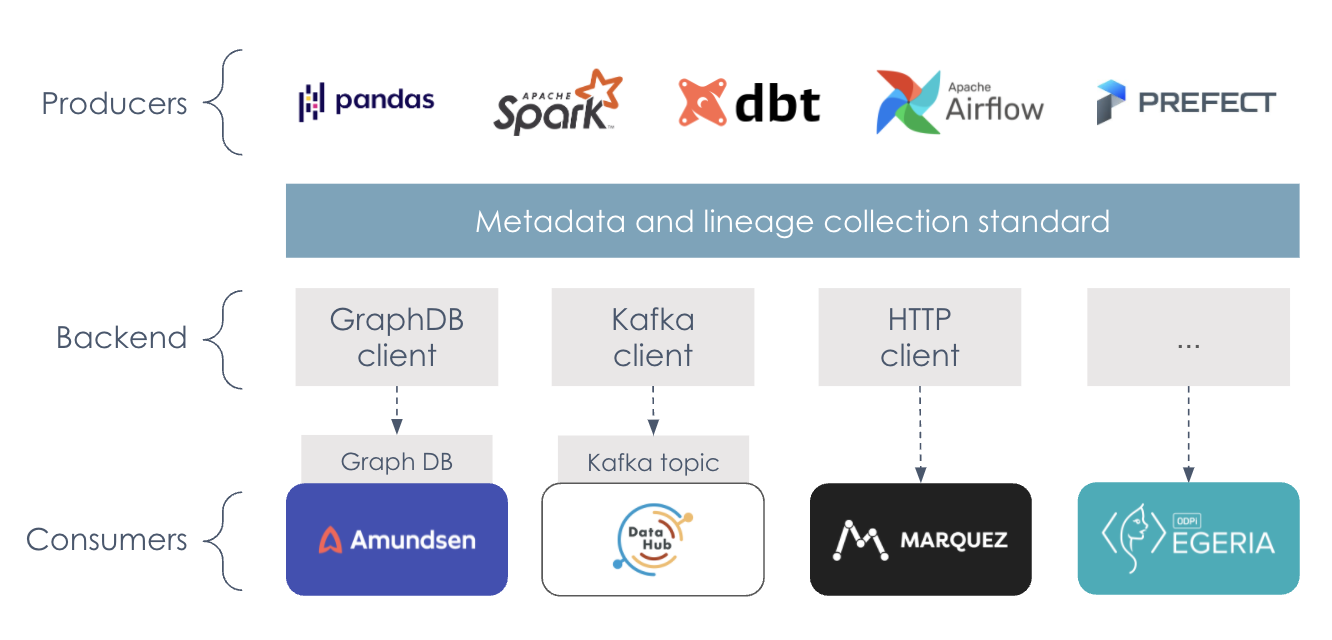
- Capturing lineage metadata from the tools that produce datasets and perform data transformations.
- Sending lineage information using the OpenLineage specification to various backends.
- Providing lineage information to various consumers that require this data.
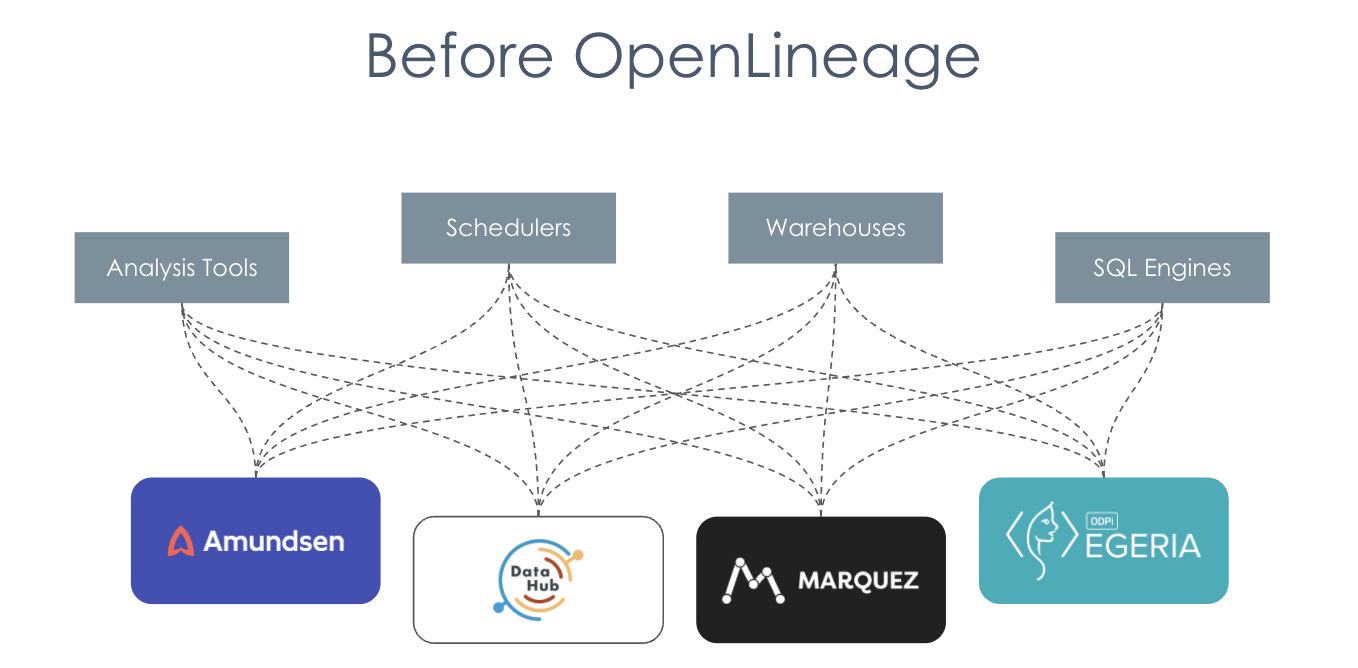
Before OpenLineage
Before OpenLineage tools like Marquez, Amundsen, etc. would have had to build separate integrations with all the different analysis tools and schedules and warehouses and SQL engines and other metadata servers. This was a lot of duplicated effort.
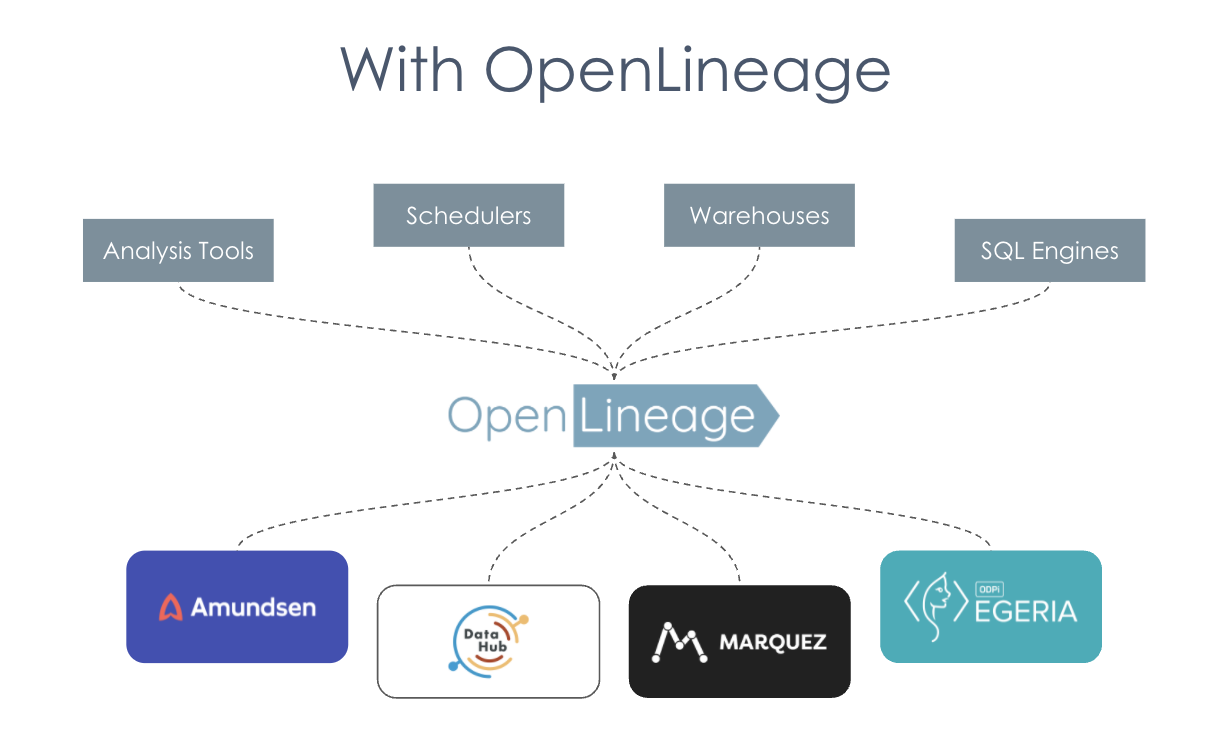
With OpenLineage
With OpenLineage, we're able to unify a lot of this work so that these data collectors can be built once and benefit a whole cohort of tools that need the same information. OpenLineage standardizes how information about lineage is captured across the ecosystem.
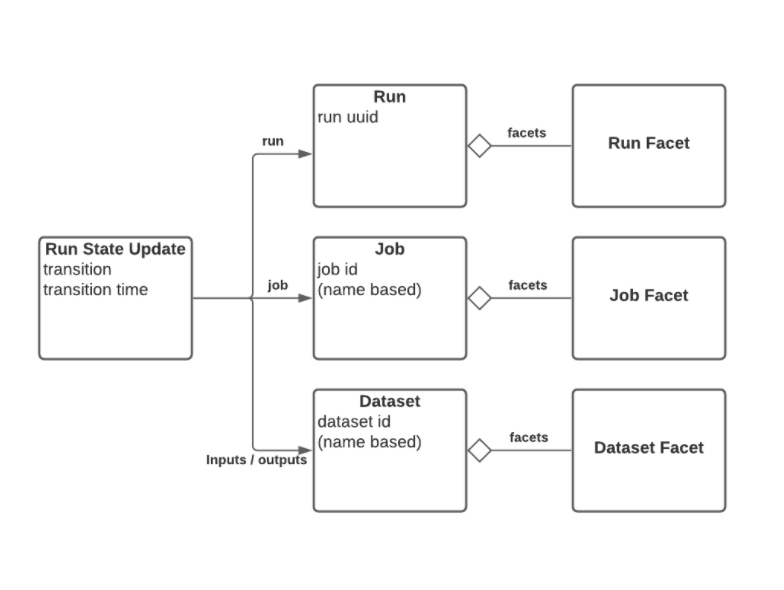
8. The data model
- Built around core entities: Datasets, Jobs, and Runs
- Defined as a JSONSchema spec
- Consistent naming for:
- Jobs (scheduler.job.task)
- Datasets (instance.schema.table)
9. OpenLineage Facets
Extensible Facets are atomic pieces of metadata identified by a unique name that can be attached to core OpenLineage entities.
Decentralized Prefixes in facet names allow the definition of Custom Facets that can be promoted to the spec at a later point.
Facet examples

Facets can be used to extend each of these core entities in a variety of ways.
What is the use case for lineage? It truly enhances every use case that it touches.
- Dependency tracking
- Root cause identification
- Issue prioritization
- Impact mapping
- Precision backfills
- Anomaly detection
- Change management
- Historical analysis
- Compliance
The possibilities are endless!
Part 2: Marquez
1. Metadata Service
At its core, Marquez is a metadata service.
- Centralized metadata management
- Sources
- Datasets
- Jobs
- Features
- Data governance
- Data lineage
- Data discovery + exploration
Imagine joining a company, and you want to know some top datasets or some data sets that you should be using for your dashboard or pipeline. Marquez allows you to search catalogs and give you all the answers quickly.
2. The model of Marquez
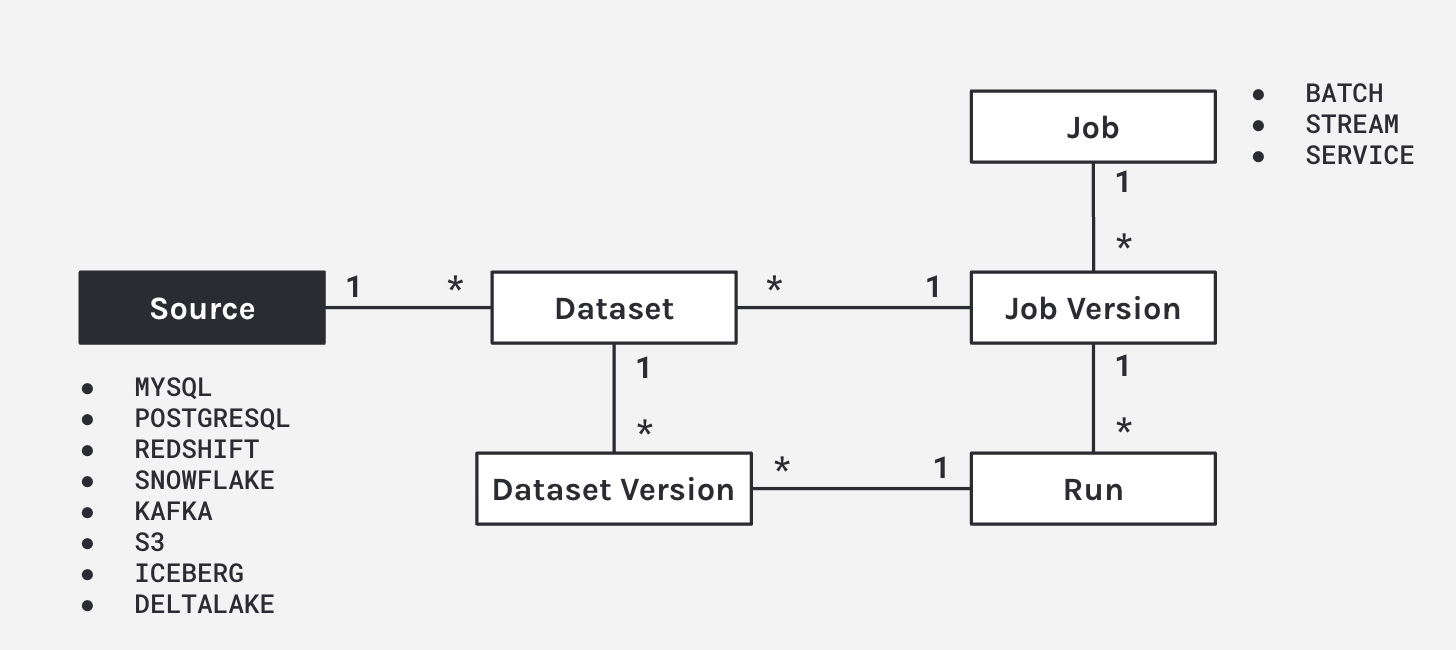
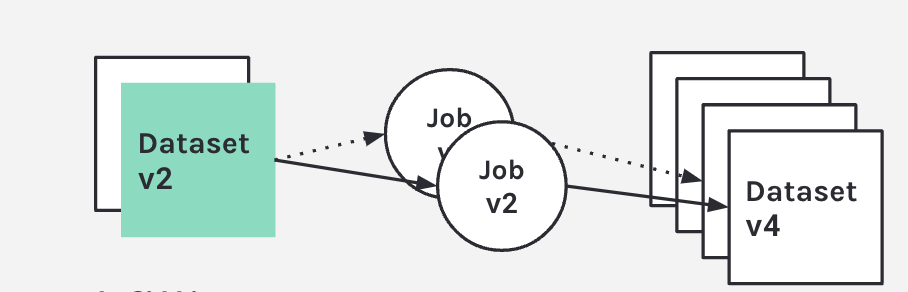
Marquez introduces the ability to version datasets and jobs.
As Marquez looks at the linear events and looks at a job, it sees what metadata has changed. A lot of the time, with a job, the code changes; it's not static. So as your code changes the integrations with GitHub GitLab, Marquez applies a straightforward logic to version that dataset. As you start a job, Marquez begins to collect the run states, and then associates run states to that run, producing a dataset version when completed.
3. Design benefits
Debugging What job version(s) produced and consumed dataset version X?
Backfilling Full/incremental processing
So what are the benefits of this model?
It makes you able to answer the question at what point in time was this issue introduced, and also, what are the downstream systems or jobs that now are affected by that?
If you can identify the job that produced the error, you'll be able to do the full and incremental process of backfilling your data and trigger downstream DAGs, which will now use corrected data.
4. Airflow observability with OpenLineage
Airflow support for Marquez:
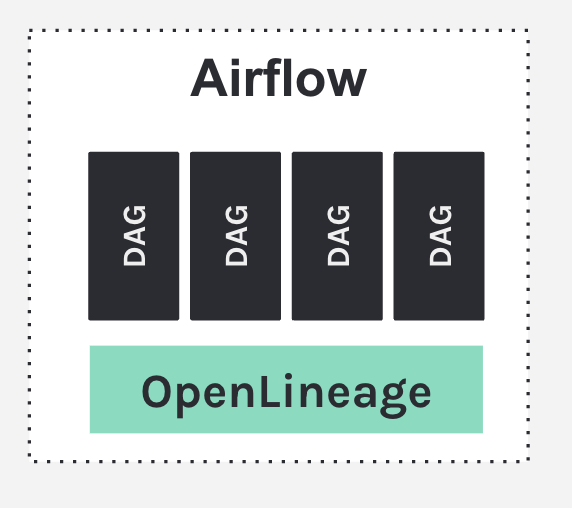
- Metadata
- Task lifecycle
- Task parameters
- Task runs linked to versioned code
- Task inputs / outputs
- Lineage
- Track inter-DAG dependencies
- Built-in
- SQL parser
- Link to code builder (GitHub)
- Metadata extractors
5. Task-level metadata
Metadata extractors are essentially a one-to-one relationship. For every operator, you have an extractor that looks at the surface level of what that operator's doing.
Your DAG is executing, and all this information is sent to the Marquez REST API, which then populates the model. Marquez is able to look at that metadata and know how to version it and put and catalog it in suitable tables.
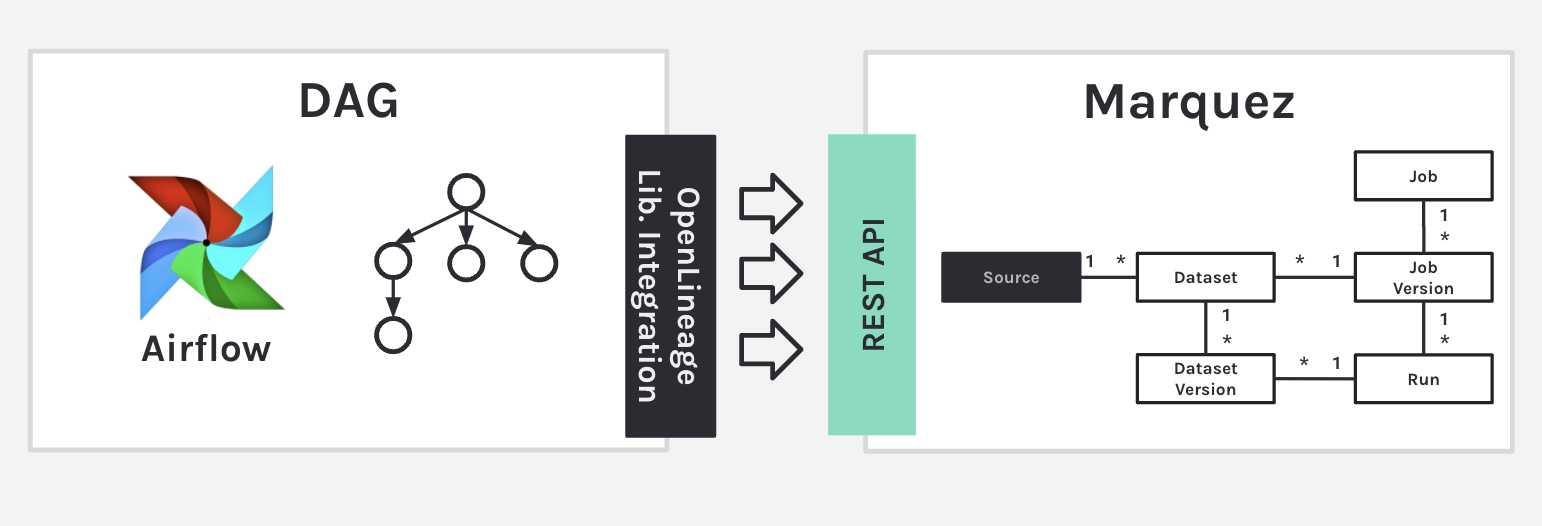
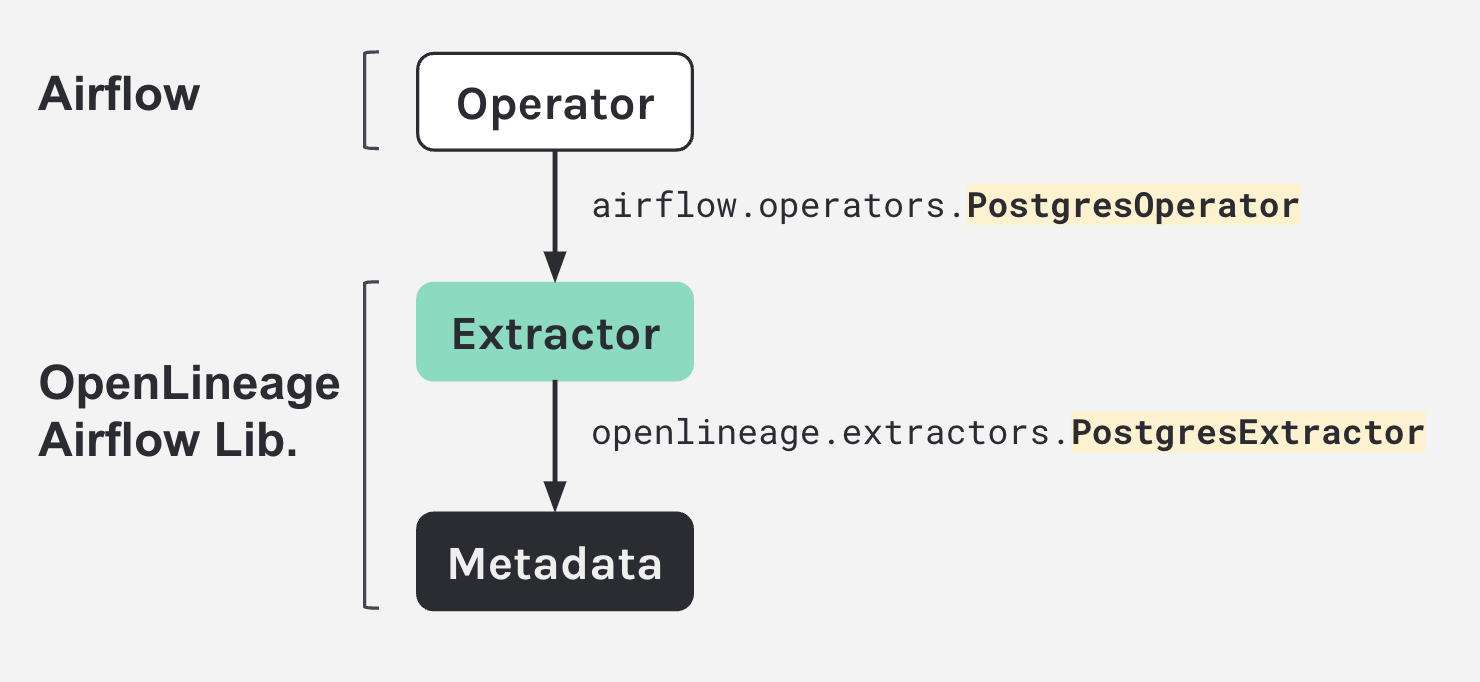
6. OpenLineage Airflow Lib
- Open source! 🥇
- Enables global task-level metadata collection
- Airflow 2 Lineage Backend Support!
Option 1: configuration through airflow.cfg
[lineage]
backend=openlineage.lineage_backend.OpenLineageBackendOption 2: configuration through ENV var
AIRFLOW__LINEAGE__BACKEND=openlineage.lineage_backend.OpenLineageBackend7. Operator metadata
Operator metadata example: new room booking DAG that uses a post-stress operator and all it's doing is just generating room booking system surveys in the sample.
- Source
new_room_booking_dag.py
Look at the connection ID and identify it as a source.
t1=PostgresOperator(
task_id=’new_room_booking’,
postgres_conn_id=’analyticsdb’,
sql=’’’
INSERT INTO room_bookings VALUES(%s, %s, %s)
’’’
parameters=... # room booking
)- Dataset
new_room_booking_dag.py
Tokenize the SQL.
t1=PostgresOperator(
task_id=’new_room_booking’,
postgres_conn_id=’analyticsdb’,
sql=’’’
INSERT INTO room_bookings VALUES(%s, %s, %s)
’’’
parameters=... # room booking
)- Job
new_room_booking_dag.py
The job itself is going to be the task ID.
t1=PostgresOperator(
task_id=’new_room_booking’,
postgres_conn_id=’analyticsdb’,
sql=’’’
INSERT INTO room_bookings VALUES(%s, %s, %s)
’’’
parameters=... # room booking
)8. Managing inter-DAG dependencies
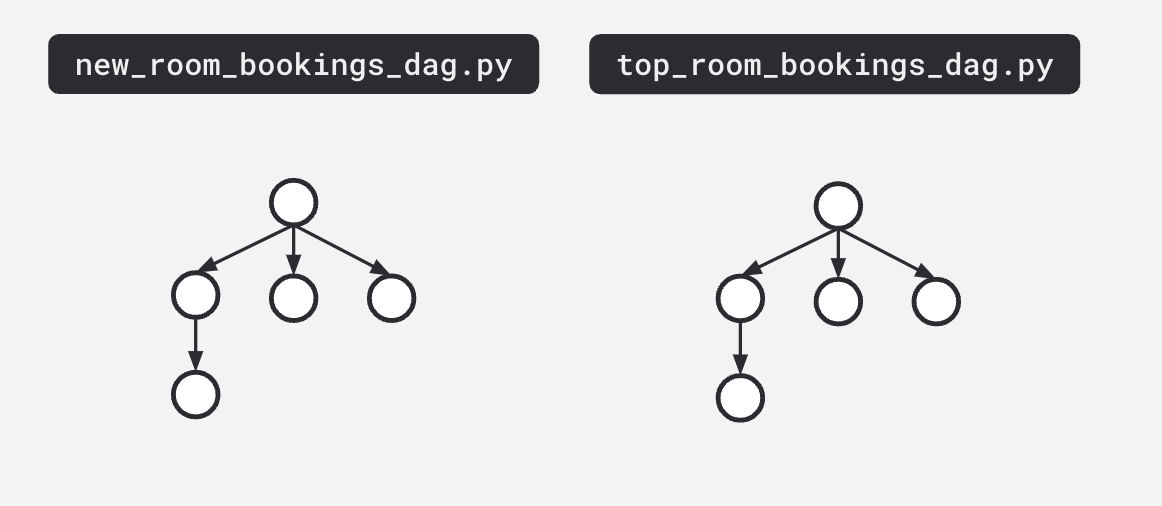
Sometimes a DAG looks great, but you have these dependencies that aren't surfaced until you have a lineage graph:
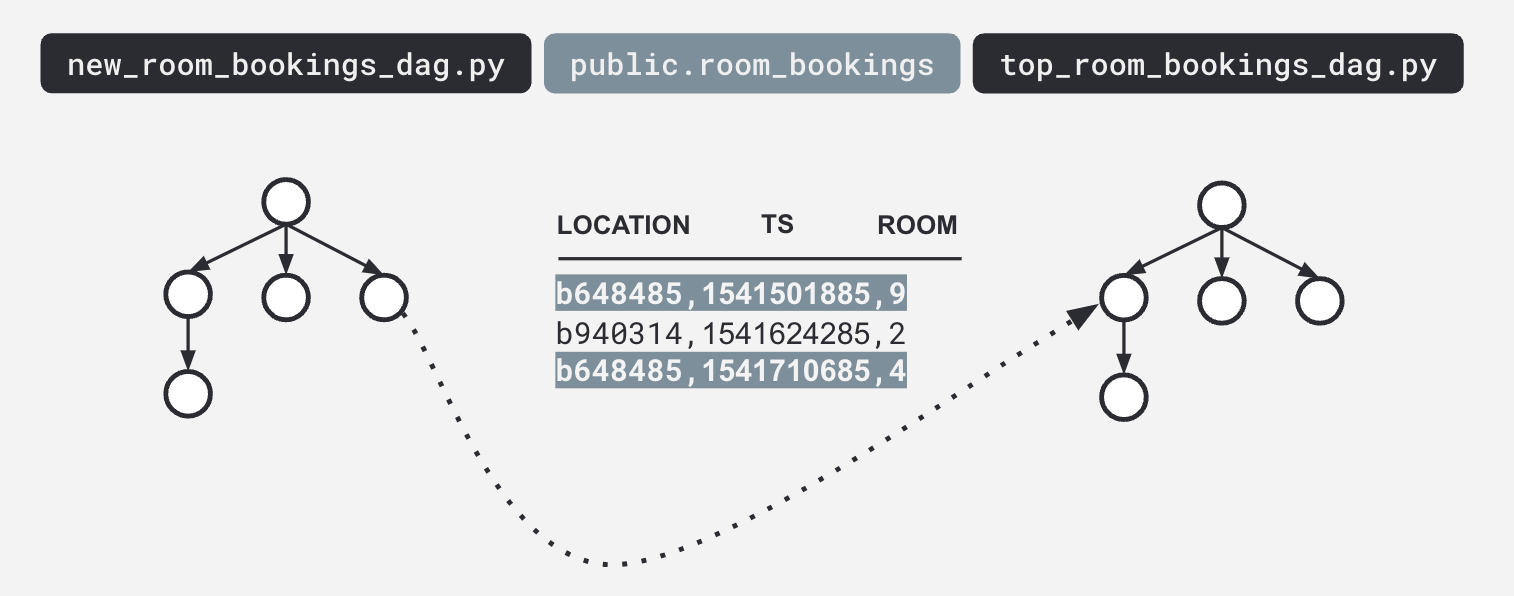
9. Demo
Go to the video for an amazing demo and Q&A which start at the 27th minute!
Related Content:

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.