Integrate OpenLineage and Airflow with Marquez
OpenLineage is the open source industry standard framework for data lineage. Integrating OpenLineage with Airflow gives you greater observability over your data pipelines and helps with everything from data governance to tracking the affected area of a task failure across DAGs to managing PII.
Viewing and interacting with lineage metadata requires running a lineage front end. Marquez is the most common open source choice for this purpose, and integrates easily with Airflow.
In this tutorial, you’ll run OpenLineage with Airflow locally using Marquez as a lineage front end. You’ll then generate and interpret lineage metadata using two DAGs that process data in Postgres.
Time to complete
This tutorial takes approximately 30 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, make sure you have an understanding of:
- The basics of OpenLineage. See Integrate OpenLineage and Airflow.
- Airflow fundamentals, such as writing DAGs and defining tasks. See Get started with Apache Airflow.
Prerequisites
- The Astro CLI.
- PostgreSQL.
Step 1: Run Marquez locally
-
Clone the Marquez repository:
-
Run the following command in the
marquezdirectory to start Marquez:
For more details, see the quickstart in the Marquez README.
Step 2: Configure your Astro project
Use the Astro CLI to create and run an Airflow project locally that will integrate with Marquez.
-
Create a new Astro project:
-
Add the Airflow OpenLineage provider to your requirements.txt file. Note that the minimum Apache Airflow version required is 2.7.0 (Astro Runtime 9.0.0+).
-
Add the following environment variables below to your Astro project
.envfile:These variables allow Airflow to connect with the OpenLineage API and send your lineage metadata to Marquez.
By default, Marquez uses port 5000 when you run it using Docker. If you are using a different OpenLineage front end instead of Marquez, or you are running Marquez remotely, you can modify the
OPENLINEAGE_URLas needed. -
Marquez also uses Postgres, so Airflow needs to use a different port than the default 5432, which is already allocated to Airflow. Run the following command to use a port 5435 for Postgres:
-
Run the following command to start your local project:
-
Confirm Airflow is running by going to
http://localhost:8080, and Marquez is running by going tohttp://localhost:3000.
Step 3: Configure your database
To show the lineage metadata that can result from Airflow DAG runs, you’ll use two sample DAGs that process data in Postgres. To run this example in your local environment, complete the following steps:
-
Using
psql, create a local Postgres database in the same container as the Airflow metastore:If you already have a Postgres database or are using a different type of database you can skip this step. Note that this database should be separate from the Airflow and Marquez metastores.
-
Run the following SQL statements in your new database to create and populate two source tables:
Step 4: Configure your Airflow connection
The connection you configure will connect to the Postgres database you created in Step 3.
-
In the Airflow UI, go to Admin > Connections.
-
Create a new connection named
postgres_defaultand choose thepostgresconnection type. Enter the following information:- Host:
host.docker.internal - Login:
postgres - Password:
postgres - Port:
5435
If you are working with a database other than local Postgres, you may need to provide different information to the connection.
- Host:
Step 5: Create your DAGs
For this tutorial, you create two DAGs to generate and interpret lineage metadata.
-
In your Astro project
dagsfolder, create a new file calledlineage-combine.py. Paste the following code into the file: -
Create another file in your
dagsfolder and call itlineage-reporting.py. Paste the following code into the file:
The first DAG creates and populates a table (animal_adoptions_combined) with data aggregated from the two source tables (adoption_center_1 and adoption_center_2) you created in Step 3. The second DAG creates and populates a reporting table (adoption_reporting_long) using data from the aggregated table (animal_adoptions_combined) created in your first DAG. Both of these DAGs use the SQLExecuteQueryOperator - supported by OpenLineage, so lineage is generated automatically.
You might want to make adjustments to these DAGs if you are working with different source tables, or if your Postgres connection id isn’t postgres_default.
Step 6: Run your DAGs and view lineage metadata
You can trace the data through the DAGs you created in Step 5 by viewing their lineage metadata in Marquez.
-
Run the
lineage-combine-postgresDAG. -
Run the
lineage-reporting-postgresDAG. -
Go to the Marquez UI at
localhost:3000and view the jobs created by each task instance. You should see something like this: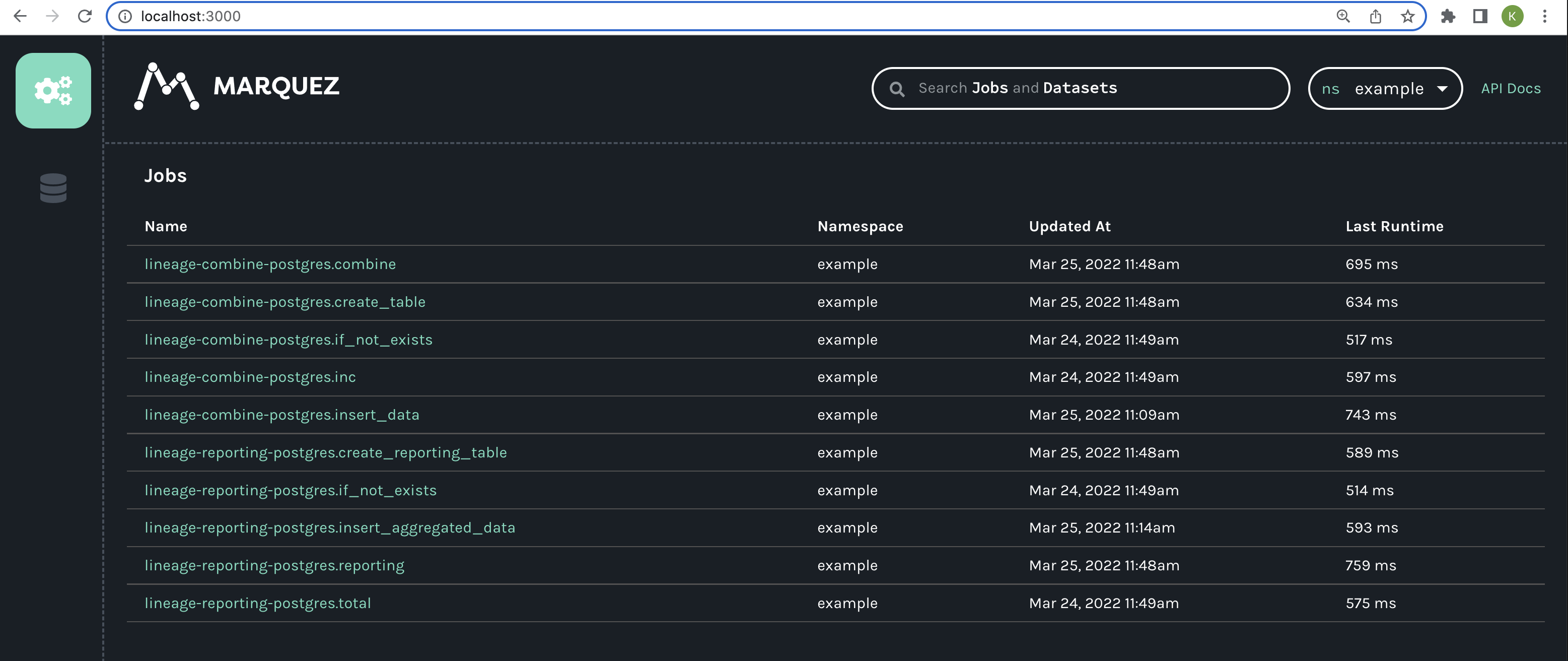
-
Click one of the jobs from your DAGs to see the full lineage graph.
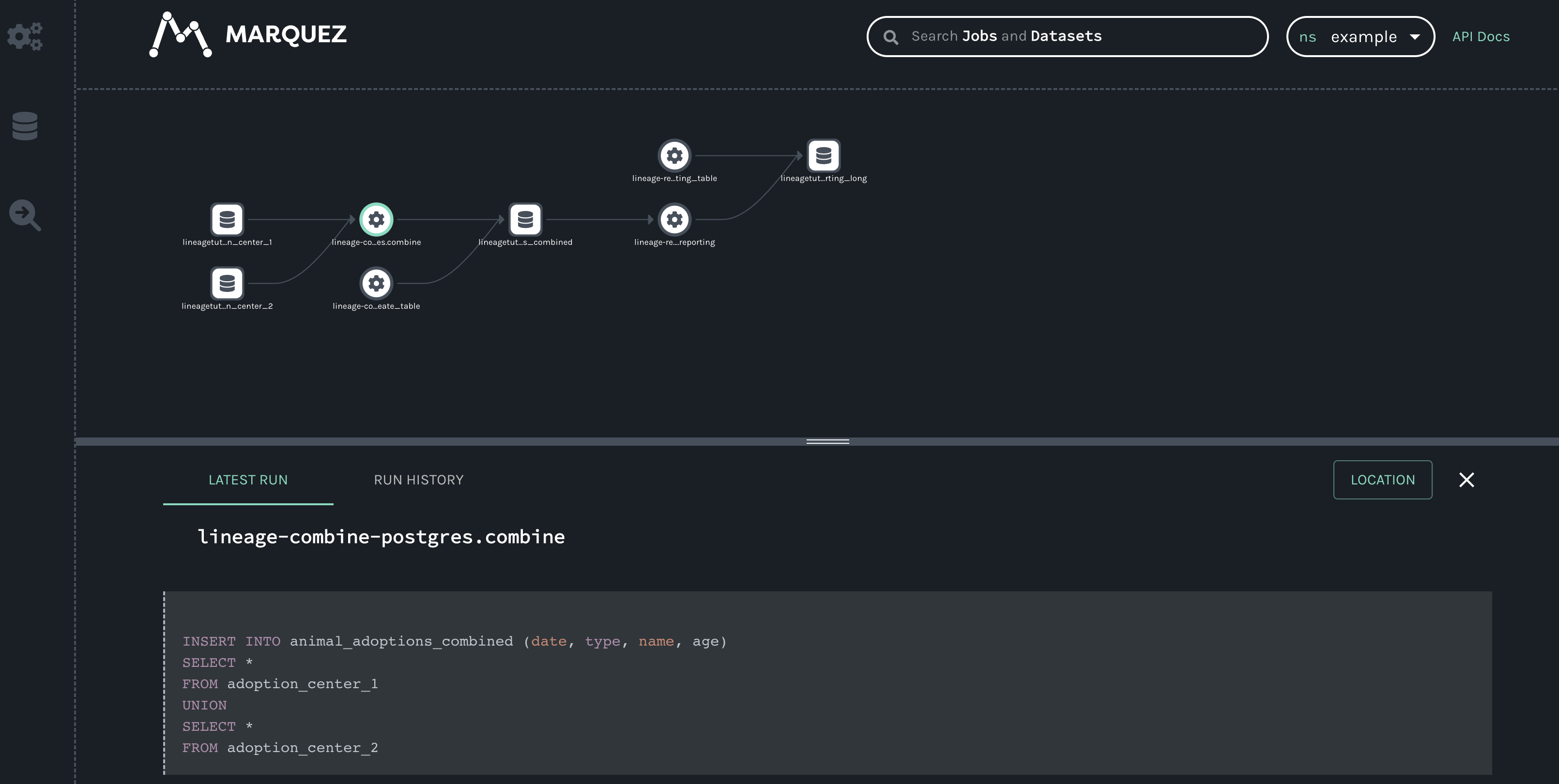
The lineage graph shows:
- Two origin datasets that are used to populate the combined data table.
- The four jobs (tasks) from your DAGs that create new tables and result in new combined datasets:
combineandreporting. - Two new datasets that are created by those jobs.
The lineage graph shows you how these two DAGs are connected and how data flows through the entire pipeline, giving you insight you wouldn’t have if you were to view these DAGs in the Airflow UI alone.
Conclusion
Congratulations! You can now run Marquez and Airflow locally and trace data through your DAGs by viewing their lineage. As a great next step, try other Airflow operators that generate lineage metadata. Or, if you are an Astronomer customer, check out lineage in Astro.