Why Observability Belongs in Your DataOps Platform
8 min read |
Observability is a hot topic right now for people who write and maintain data pipelines. With 85% of Airflow users relying on Airflow more for external or revenue-generating solutions over time, it makes sense that a full understanding of what’s happening in those data pipelines is business-critical. But observability for data pipelines doesn’t just mean getting an alert when a pipeline fails. It’s a broad umbrella that includes everything from comprehensive pipeline health monitoring, to systemic help for troubleshooting failures (or even predicting them before they happen), to lineage, to SLAs, to cost management, and more.
Many teams try to solve the issue of getting better observability over their data pipelines by using third-party monitoring tools. Those tools can work in some cases, but they almost always come at the cost of extra configuration, lost context, and a slower feedback loop, especially if you need to use more than one of them. A better approach is to make observability a first-class part of your DataOps platform, i.e., within the same tool as your orchestration layer (which for the purposes of this post, we’ll assume is Airflow).
In this post, we’ll look at some of the challenges of using multiple tools for data pipeline observability, what Airflow offers for observability features (and notably, what it doesn’t), and how Astro Observe provides a comprehensive single plane of glass for your Airflow pipelines.
The Trade-Offs of External Observability Tools
It’s worth taking a closer look at some common reasons why relying on observability tools external to your orchestration layer can add friction.
First, external tools will almost always require extra configuration. To integrate an orchestrator like Airflow with a separate monitoring or data quality tool, you need to ship logs and metrics out of your Airflow instance. This is certainly doable, but it’s not always easy - for example, Airflow can be set up to send metrics to StatsD or OpenTelemetry (which can then be used by downstream tools built around those systems), but it requires a level of knowledge of Airflow’s metrics configuration that the average data team member might not have time to learn. If you have to configure logging in Airflow to get the specific info you want, that makes it even more complicated. Even setting up connections in Airflow can be tricky, especially for large enterprises that have specific auth requirements - you can’t get around connecting Airflow to other tools that you’re orchestrating, but it’s nice to avoid doing it for something purely for observability. And consider that you multiply all this work for every Airflow instance you have, unless your team is small enough to rely on one (according to the 2024 Airflow survey, only ~25% of users have just one production Airflow instance).
A second point of friction with external observability tools is the potential for lost context. Take the example of using a third party tool to manage SLAs. You might set up an SLA to tell you if data in one of your Snowflake tables wasn’t refreshed by 8am on Monday morning, but if that tool is only connected to your Snowflake instance, you might have no idea what pipeline caused the issue when that SLA breach comes through. Starting Monday morning with a time-consuming sleuthing exercise is not something any data team member wants to do.
Take another example of using a third party tool to monitor and manage your Snowflake costs. That tool might integrate with Airflow, but maybe it was built on Airflow’s SnowflakeOperator, which was recently deprecated. The provider of your cost management tool will (hopefully) update their system to work with newer methods of executing Snowflake queries from Airflow, but how long will you have to wait for that? And what if you make a change to your dag implementation for other reasons, and your new query method isn’t supported? Or what if you realize that Airflow isn’t emitting all of the logs you need to make sense of the results in your third party monitoring tool? (Then you’re back to the first point of friction). Working with third party observability tools will always mean the potential for holes in your observability. This may be acceptable for some teams, but for large scale Airflow instances supporting critical data products, it can be a huge blocker.
A final common issue we’ll call out with using external observability tools to monitor your data pipelines is slower feedback loops. Just simply needing to work within multiple platforms slows you down as you switch back and forth between them to figure out what’s going on. It also typically slows down the onboarding of new team members, as they need to be granted access to and learn multiple systems. This gets even worse if you’re dealing with missing context like we just mentioned. Latency issues can also come into play if you need to wait for the third party tools to reflect changes in your Airflow dags. This point of friction slows down troubleshooting in particular, which is a very important aspect of observability. Every data team spends time debugging their data pipelines, but the ones who have better tooling to help make troubleshooting easier spend much less time fixing problems and more time implementing solutions that help their business.
Observability in Airflow
You may have read the previous section and thought “well that all sounds really tough, maybe I should just stay within Airflow!”. The issue here is that Airflow’s out of the box observability features are pretty limited. You have some baseline metrics into the health of your infrastructure (see screenshot below), great alerting functionality including custom callbacks, and many ways to implement data quality checks.
 The Airflow UI showing the health status of Airflow’s core components
The Airflow UI showing the health status of Airflow’s core components
But you don’t have SLA functionality (although at the time of writing, deadline alerts are being developed, so this may change), lineage out of the box, cost management (unless you write custom dags to do this), or, perhaps most importantly, visibility across multiple Airflow instances.
Airflow is a great starting point, and its basic alerting functionality is widely relied on by data teams. But it often isn’t enough to provide the full observability picture you need to have peace of mind when managing your company’s critical data.
Observability in Astro
The observability functionality built into Astro, Astronomer’s fully managed Apache Airflow platform, solves both the issues with external observability tools described above and the limitations of observability in Airflow by coupling orchestration and observability into one platform. Astro Observe provides key data pipeline observability metrics like lineage, data product SLA performance, pipeline health, data quality monitoring and cost management all in one place, whether you have one Airflow instance or hundreds.
You get visibility into the health of all of your data pipelines, across every Airflow Deployment, with no Airflow configuration (no metrics exporting, no connections, no custom logging) required. This allows you to see not only failures that need immediate attention, but metrics like average runtimes and long running dags and tasks that may require intervention before they cause issues.
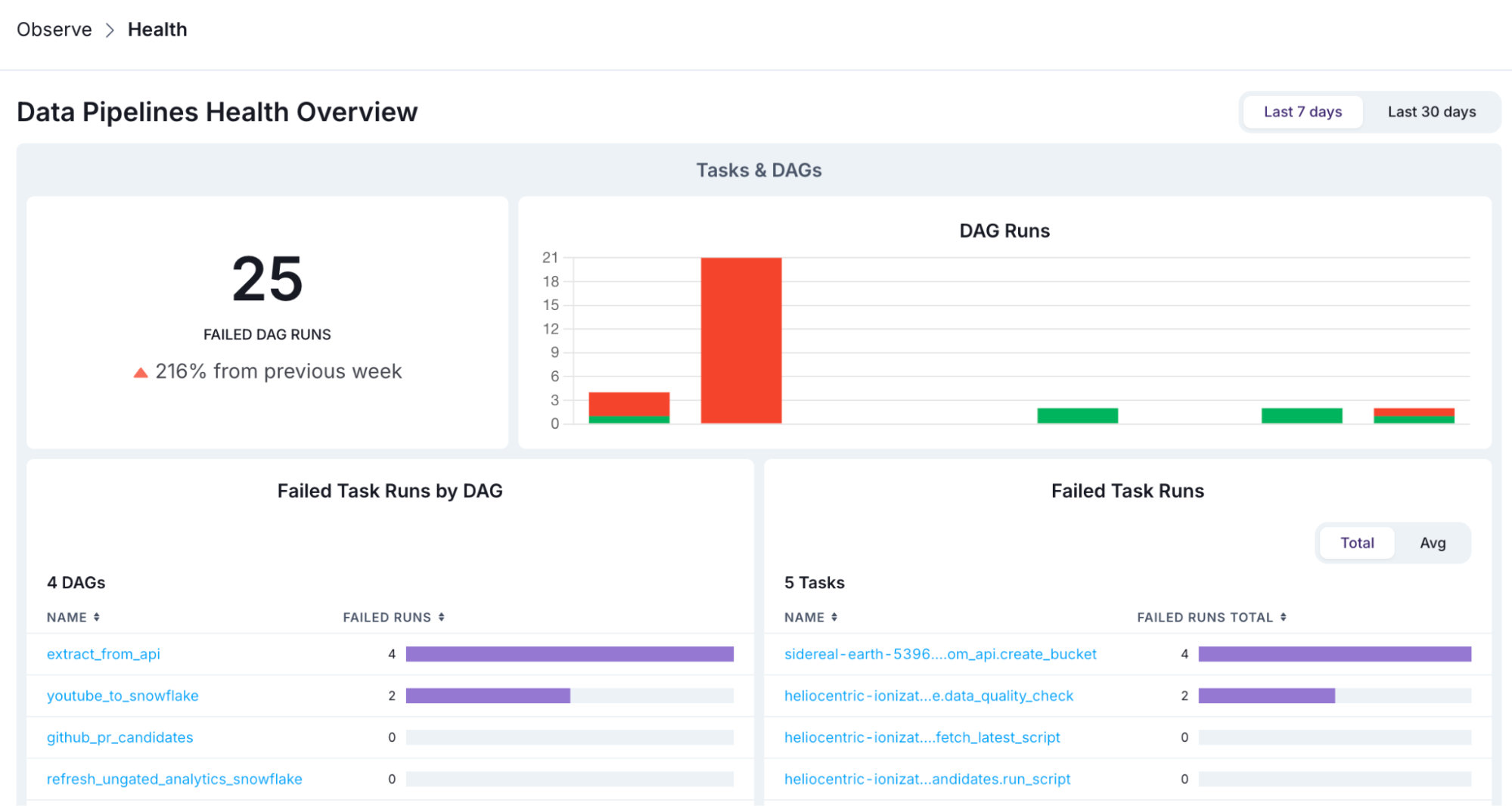 Data pipeline health overview in Astro Observe
Data pipeline health overview in Astro Observe
You can see the real-time lineage of your data products (including related dags, tasks, and assets) simply by running your dags in Astro, without configuring OpenLineage or another lineage tool that works with Airflow, or making changes to your dag code.

And you can create alerts and SLAs beyond what is supported in open source Airflow, and see the results without toggling back and forth between Airflow and some external tool.
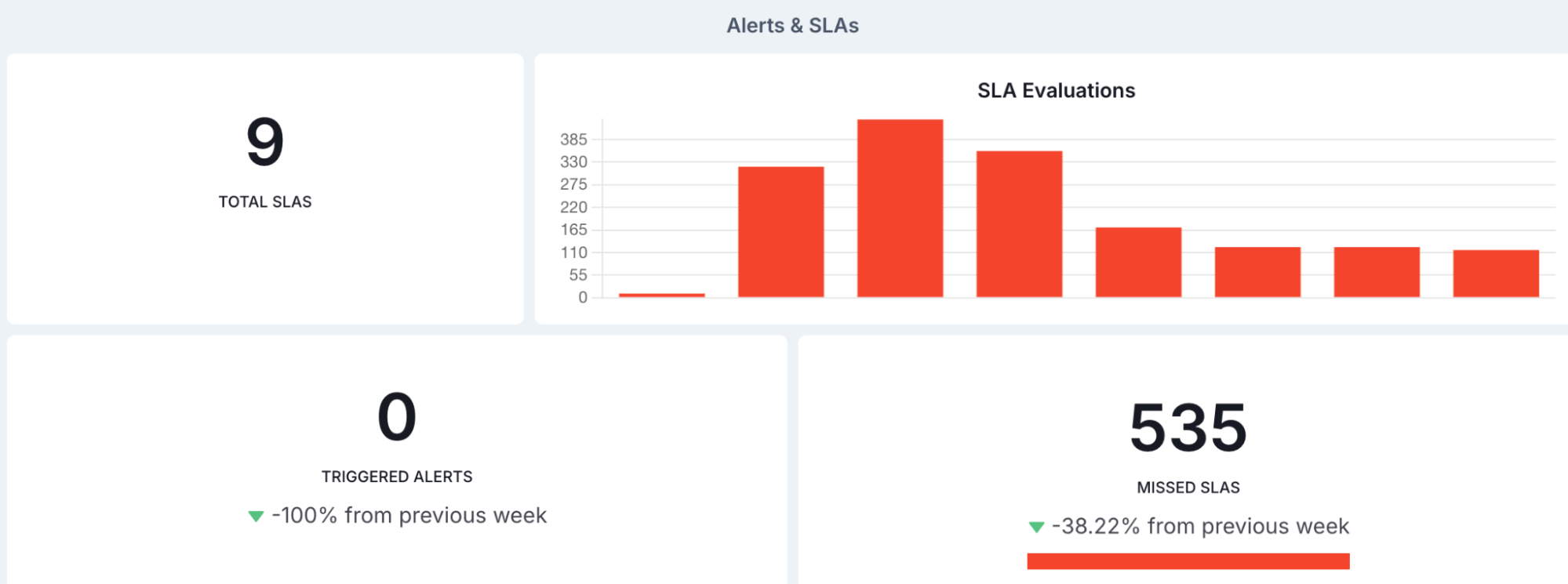 Something seems to be going wrong with our dags, but we can see that and address it without leaving our orchestration platform.
Something seems to be going wrong with our dags, but we can see that and address it without leaving our orchestration platform.
Astro Observe also has functionality for AI log summaries and proactive alerting to help with troubleshooting and avoiding downtime, and built-in data quality monitoring and data warehouse cost management (currently in private preview) to help optimize the costs of your data pipelines. Overall, it’s the most comprehensive single pane of glass for your Airflow pipelines.
Closing Thoughts
Data teams will always need observability, but how and where you get it matters. Relying on external tools means more configuration to maintain, more systems to stitch together, and more blind spots when context doesn’t carry over. Staying inside Airflow gives you a clean starting point, but it can’t always provide the breadth you need—especially at scale, across multiple deployments.
Astro bridges that gap by embedding data observability directly into the orchestration layer. You get pipeline health, lineage, SLAs, data quality monitoring and cost management in one place, without exporting metrics or wiring up extra systems. That reduces operational overhead and shortens the loop from “something broke” to “here’s the fix.”
If your Airflow pipelines are business-critical, observability shouldn’t be an add-on. It should live alongside your orchestration, where the full context already exists.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.