The New KubernetesExecutor
8 min read |
With Airflow 2.0, we are excited to introduce a completely redesigned KubernetesExecutor. This new architecture is faster, more flexible, and easier to understand than the KubernetesExecutor of 1.10. As the first step in your migration, we would like to give you a tour of the new features in the KubernetesExecutor 2.0!
What Is the KubernetesExecutor?
In 2018, we introduced the KubernetesExecutor based on the ideas of autoscaling and flexibility. Airflow did not yet have a clear concept of autoscaling Celery Workers (though our recent work with KEDA has made long strides in this regard), so we wanted to build a system that could match the needs of the user. This research resulted in a system that used the Kubernetes API to launch a pod per-airflow task. A valuable side-effect of this Kubernetes API-based system is that it opened the possibility that users could add unique additions and constraints on a per-task basis.
Using the Kubernetes API and the KubernetesExecutor, Airflow users can determine that certain tasks have access to specific secrets or that a task can only run on a node that exists in the European Union (which can be valuable for data governance). Users can also specify how many resources a task takes, which can vary greatly depending on what a task is doing (e.g., running a TensorFlow script will need access to GPUs). Through this API, the KubernetesExecutor allows data engineers to have a much more fine-grained control over how Airflow executes their tasks than they would be using only existing Celery queues.
Of course, the KubernetesExecutor is not optimal for all use cases. Since it starts a pod per task, system overhead can make jobs slower than hot-started existing Celery workers (though this is on the order of seconds which is insignificant for long-running tasks). Also, the CeleryExecutor will be more efficient at super high volume since it can run multiple tasks on a single worker. Considering that both the CeleryExecutor and KubernetesExecutor have unique value-adds for Airflow users, one great feature in Airflow 2.0 is that we now have the CeleryKubernetesExecutor, which allows users to take advantage of both systems!
New KubernetesExecutor Features
The pod_template_file
In Airflow 1.10.12, we introduced the pod_template_file. This new way of storing all Kubernetes configs involved a rewrite of the KubernetesExecutor internals. However, this change has been worth it as Airflow admins now can use the entire Kubernetes API when generating templates for their data engineers.
This change also opens the door to the ability to maintain multiple pod_template_files in future Airflow releases. Users will be able to pick the pod_template_file that best matches their use case, much in the same way that users of the CeleryExecutor select separate queues.
This feature of launching pods based on pod_template_files merged with the 2.0 addition of fast follow task execution means that we can launch pods in Kubernetes that don't need to terminate after a single task executes. Instead, these pods can pick up new tasks much in the way that Celery workers do. The result is a significant speedup of task execution for the KubernetesExecutor.
The executor_config
Airflow 2.0 offers a new executor_config that is significantly more flexible to the user. Instead of being constrained by a Python dictionary with limited feature access, users can now use the entire Kubernetes API. We have decided to change the key value of the executor_config dictionary to "podOverride". We simultaneously thought that this key is more descriptive and that it leaves open the ability to add more options in the future.
It is worth noting that the legacy executor_config values will still work in Airflow 2.0 to minimize the breaking changes for migration. However, these will be deprecated and removed in a future version, so we recommend switching over as soon as possible.
The pod mutation hook
As introduced in 1.10.12, the new pod_mutation_hook takes a Kubernetes V1Pod object as a parameter and allows the Airflow admin to modify all pods using Kubernetes API before Airflow releases these pods. This hook applies to both pods created by the KubernetesExecutor and pods created by the KubernetesPodOperator.
A simplified design
We've now gone through the three major features of the KubernetesExecutor. We've seen how the pod_template_file gives full flexibility for creating initial pod templates, how the Kubernetes pod_override allows users to modify tasks on the fly, and how the pod_mutation_hook gives admin overrides before a pod is released. However, what I'm most excited about with these new features is how beautifully they work in a simplified design.
Below we can see a diagram of how the architecture for how the KubernetesExecutor used to work.
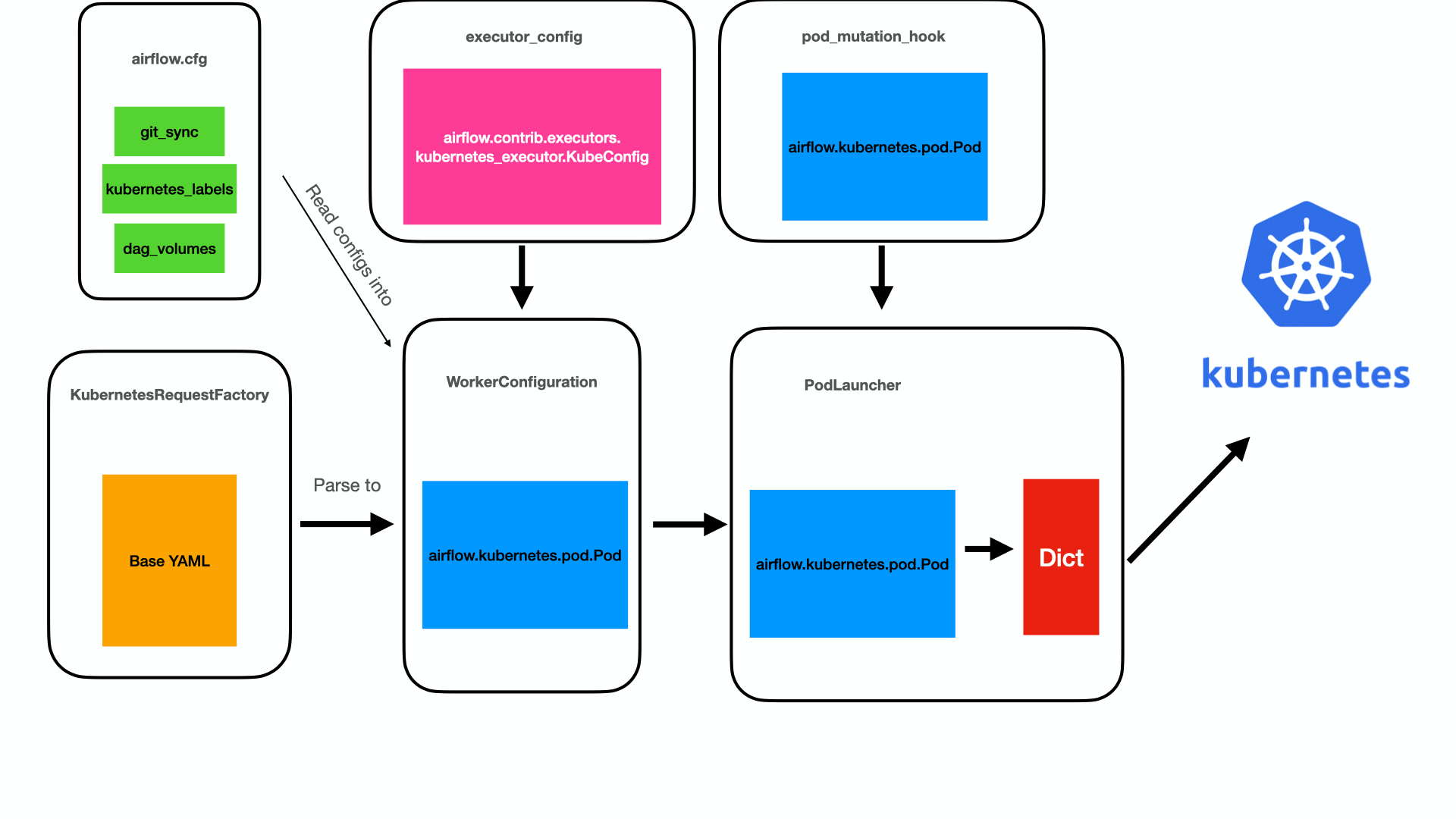
Looking back, it kind of feels like a factory that piece-by-piece creates a pod before launching it. The pod goes through at least four stages and three classes before it is serialized and launched. This design leaves lots of room for error and confusion.
Let's compare that with design.
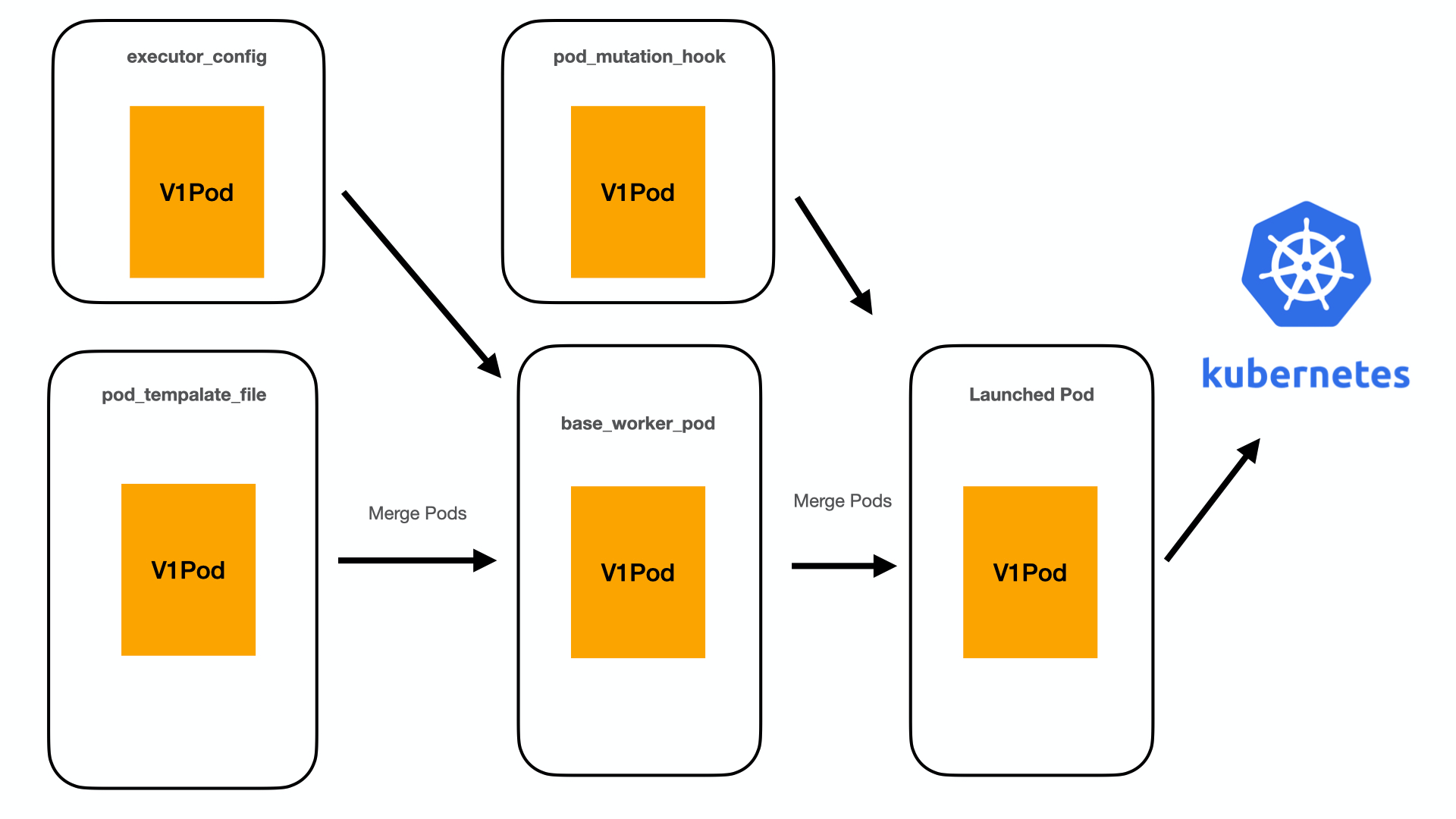
This new design is far more straightforward. Now we are merely taking an existing pod spec, allowing for one round of user overrides, and a round of admin overrides before launch. All three users are modifying the same V1pod object, which leads to better consistency across the organization.
What This Means for Data Engineers
All of the features described above are clearly impactful for Airflow admins or DevOps engineers, but some of these new features are designed to be directly leveraged by data engineers as well.
The biggest change for a data engineer who writes DAGs is likely the new executor_config with podOverride. Prior to this change, if an engineer wanted to override Kubernetes system defaults for specific tasks in their DAGs, they were limited in which features they could access without needing to use the KubernetesPodOperator to do so. Using the KubernetesPodOperator involved creating and building an entire Docker image to run each task, which could add complexity and effort. Now, with the new executor_config, engineers can access the entire Kubernetes API and use the podOverride to do things like mount volumes, add environment variables, add labels, set node affinities, etc. using any operator they wish.
Take for example a case where we want to add a label, and an environment variable that will be used in a Python function to the pod running our task. With the new executor_config, we can actually pass this podOverride in super cleanly using the PythonOperator with the new TaskFlow API. That DAG would look something like this:
from airflow.decorators import dag, task
from datetime import datetime
import os
import json
import requests
from kubernetes.client import models as k8s
new_config ={ "pod_override": k8s.V1Pod(
metadata=k8s.V1ObjectMeta(labels={"purpose": "pod-override-example"}),
spec=k8s.V1PodSpec(
containers=[
k8s.V1Container(
name="base",
env=[
k8s.V1EnvVar(name="STATE", value="wa")
],
)
]
)
)
}
default_args = {
'start_date': datetime(2021, 1, 1)
}
@dag('k8s_executor_example', schedule_interval='@daily', default_args=default_args, catchup=False)
def taskflow():
@task(executor_config=new_config)
def get_testing_increase():
"""
Gets totalTestResultsIncrease field from Covid API for given state and returns value
"""
url = 'https://covidtracking.com/api/v1/states/'
res = requests.get(url+'{0}/current.json'.format(os.environ['STATE']))
return{'testing_increase': json.loads(res.text)['totalTestResultsIncrease']}
get_testing_increase()
dag = taskflow()With the new_config we pass in the label and environment variable we want to add to the pod using the Kubernetes API. The DAG then has a simple task that uses that environment variable to make an API call to get Covid data for a particular state. This is a very simple example, but it gives an idea of the flexibility of the new podOverride functionality. For other examples, you can check out the Airflow Kubernetes executor documentation.
Migrating to the New KubernetesExecutor
To ease the adoption of the new KubernetesExecutor, we offer two onboarding experiences. The first onboarding experience is for new users, and the second is for existing users.
For new users, we offer multiple starter YAML files. These files provide templates for running with DAGs baked in, with DAG retrieval via git, and with DAG retrieval via the Kubernetes Volume system.
For existing users, we offer a migration script that reads your airflow.cfg and generates a YAML file based on your current settings. This YAML file is then modifiable to meet the exact needs of every user.
The best part of these three new features is that they are all available in Airflow 1.10.13. You can start your migration process immediately and enjoy the benefits and speed improvements of this simpler design. We look forward to your feedback, and please do not hesitate to reach out with any questions, feature requests, or documentation requests!
If you'd like to learn even more about the new KubernetesExecutor, don't hesitate to contact us.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.