Orchestrating Data Quality with Airflow
7 min read |
Here we’ll dive into why and how the Data Team built scalable, maintainable data quality checks inside the developer experience and made maintaining high data quality an attainable outcome.
Why is Maintaining High Data Quality Hard?
I won’t spend too much time justifying why data quality matters. By now, we all know the saying “garbage in, garbage out”. If your data isn’t clean and curated, enjoy your murky business decisions and AI hallucinations.
Maintaining high data quality isn't about having no bad data (it’s impossible); it’s about building and maintaining trust with consumers. And we hit a point where data consumers were more often than not identifying issues before we did. If data consumers are constantly second-guessing the output, it doesn't matter how fast your pipeline runs or how beautiful your dashboards are. Doubt kills impact. This was our wake-up call to prioritize data quality; proactiveness would be our way to rebuild trust.
But why is it actually hard to maintain high data quality? Well, that’s kind of hard to answer because it's a deceptively complex problem.
- Unclear Ownership. Everyone touches the data, so no one fully owns it. Establishing clear accountability is tough.
- Bugs. Once you move beyond print("hello world"), bug-free code doesn’t exist.
- Messy Source Data. Schema changes, external tool outages, data entry errors, etc.
- Everything is in flux, always. Data, priorities, and business processes aren’t static.

So to fix it we just need to establish continuous testing, clear ownership, and a scalable framework for enforcement. Now the question was, could we build this data quality framework with just Airflow?
Why test with Airflow?
Data isn’t static so our tests can’t be either. We need ongoing testing to catch regressions from source changes, business logic evolution, and code updates. Simply testing the data when you first ingest or create a table won’t suffice, instead you need to continually test every time it’s updated. If our updates are orchestrated, then it’s very natural to orchestrate the tests too. ALL our data flows through Airflow, and so that’s where our tests need to be as well.
Embedded Data Quality
When we started orchestrating our data checks, we did it with a standalone DAG but the overhead of maintaining it made it hard to sustain and our testing coverage wasn’t very clear. Ideally, the tests should sit right alongside the respective data operations themselves. This keeps them within the data engineer’s regular workflow, making testing an integrated part of the development process rather than an additional, easily forgotten step.
So how does one integrate testing into the existing data processes?
Our team is set up to operate with high velocity because we’ve built frameworks around common data workflow. Under the hood our DAGs are generated using custom task groups, which are essentially pipeline templates for our repeatable processes (ETL, Creating/Incrementing Tables, rETL, etc.). So, why not create a reusable task group but for testing? Then we can nest this new testing task group inside those other existing task groups, giving us a means of adding tests to all our pipelines out of the box.
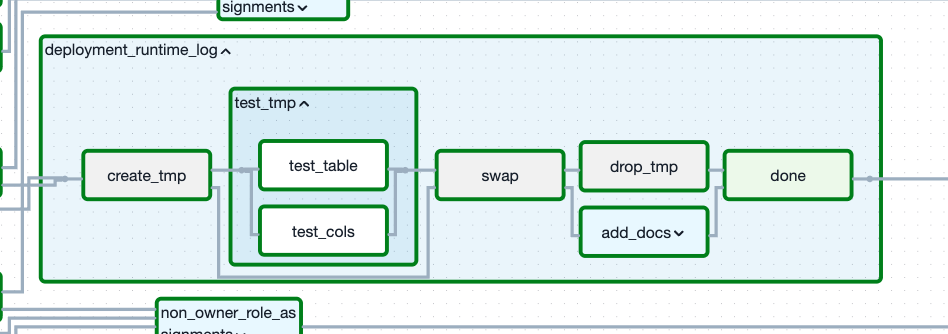
An expanded view of our CreateTable task group, generating the table `deployment_runtime_log`. With our testing task group, also expanded, between our create_tmp and swap tasks, meaning we test our pending updates before promoting them to production.
We’ll share more on the power of reusable task groups in a future blog, but they work as a contract mechanism for production suitability, ensuring everyone follows current best practices. Embedding testing in all our DAGs put what would easily be an afterthought at the forefront. If it’s free and at your fingertips, why not use it?
This implementation turned testing into a simple configuration within the parent task group. Engineers could now define tests in the same place they were already building pipelines. Because tests were now clearly tied to specific operations, it was immediately more visible where testing was happening in the codebase (or where it wasn’t). Embedding testing into the developer pipeline itself increased adoption and visibility.
Today, we test in all layers of our data warehouse; from ingests, to modeling, all the way through delivery. We use data contracts to define expectations of the data we ingest or consume from our broader data mesh. Then continuously check for accuracy and integrity throughout all downstream layers, because we can’t just naïvely assume “clean in, clean out”.
Now, when a new data issue arises, there is no Airflow to write, it’s just a matter of adding configuration to cover the new edge case or business rule. Testing has become declarative, scalable, and easy to maintain.
But this isn’t just the data engineers’ issue
As data engineers working across domains, we’re often subject to a lot of data quality issues. But the reality is that some quality issues aren't best solved by the data engineer (i.e. a missing contract date in Salesforce).
Assuming that they are or that data issues can always be coded around can be a source of frustration for data teams. We’re often stuck in a lose-lose situation:
- If we detect an issue and stop the pipeline to prevent downstream impact, our data products appear delayed.
- If we let it through to meet SLAs, we face questions of whether our data can be trusted at all.
Instead we need to understand data isn’t perfect (and that’s not the goal). The goal is to make data available, valuable, and trustworthy. However, not all data issues are created equally. Sometimes it's better to surface an issue transparently than to silently drop or delay data; airing data gaps or inconsistencies can be more valuable than hiding them. Other times it is better to present stale data than wrong data.
So when building our testing task group, we designed it with issue severity and shared responsibility in mind. Specifically, our configuration allows you to define:
Severity of an issue.
Should I block the pipeline (hard failure)? Or allow the data to propagate but log and alert (soft failure)?
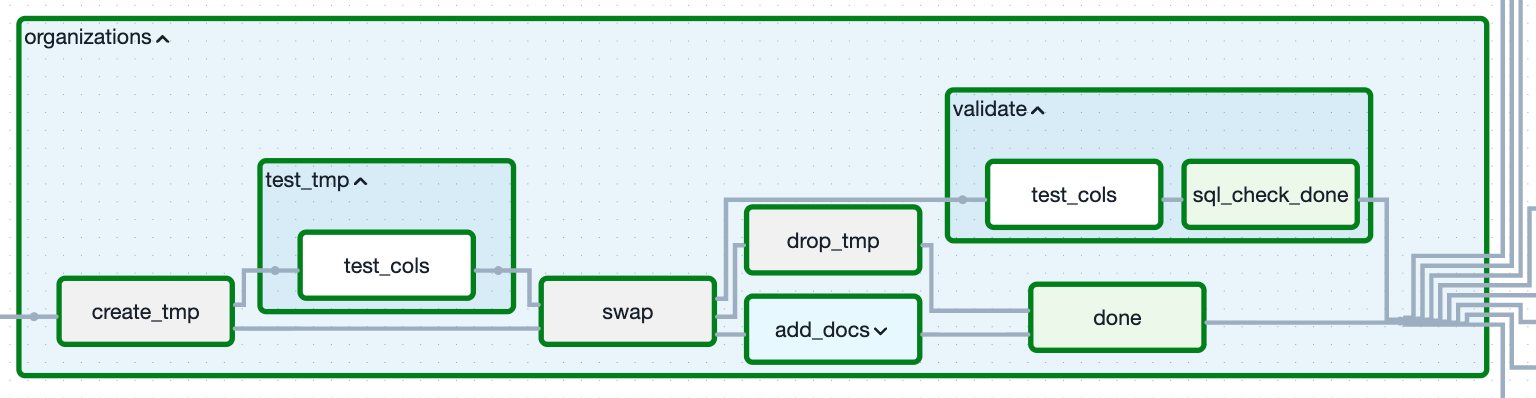
An expanded view of our CreateTable task group, generating the table `organizations`. This with lower severity (validate) tests being specified.
For clarity, we don’t have a “hard” fail task group and “soft” fail task group. Rather we have one test task group that we have called twice at different points in the CreateTable task group controlling the blocking and non-blocking failure with Airflow trigger rules.
Owner of issue.
This gives us a mechanism to triage issues and expose them to the right owners for resolution. These testing tasks log metadata to our data warehouse about what test was run and store any failed records. We then display any discovered quality issues on data hygiene dashboards (Hygienies as we call them) for external data owners to address and/or fix. These dashboards are then able to trigger emails/slacks when there are records that need resolved.
So what does invoking this test task group look like?
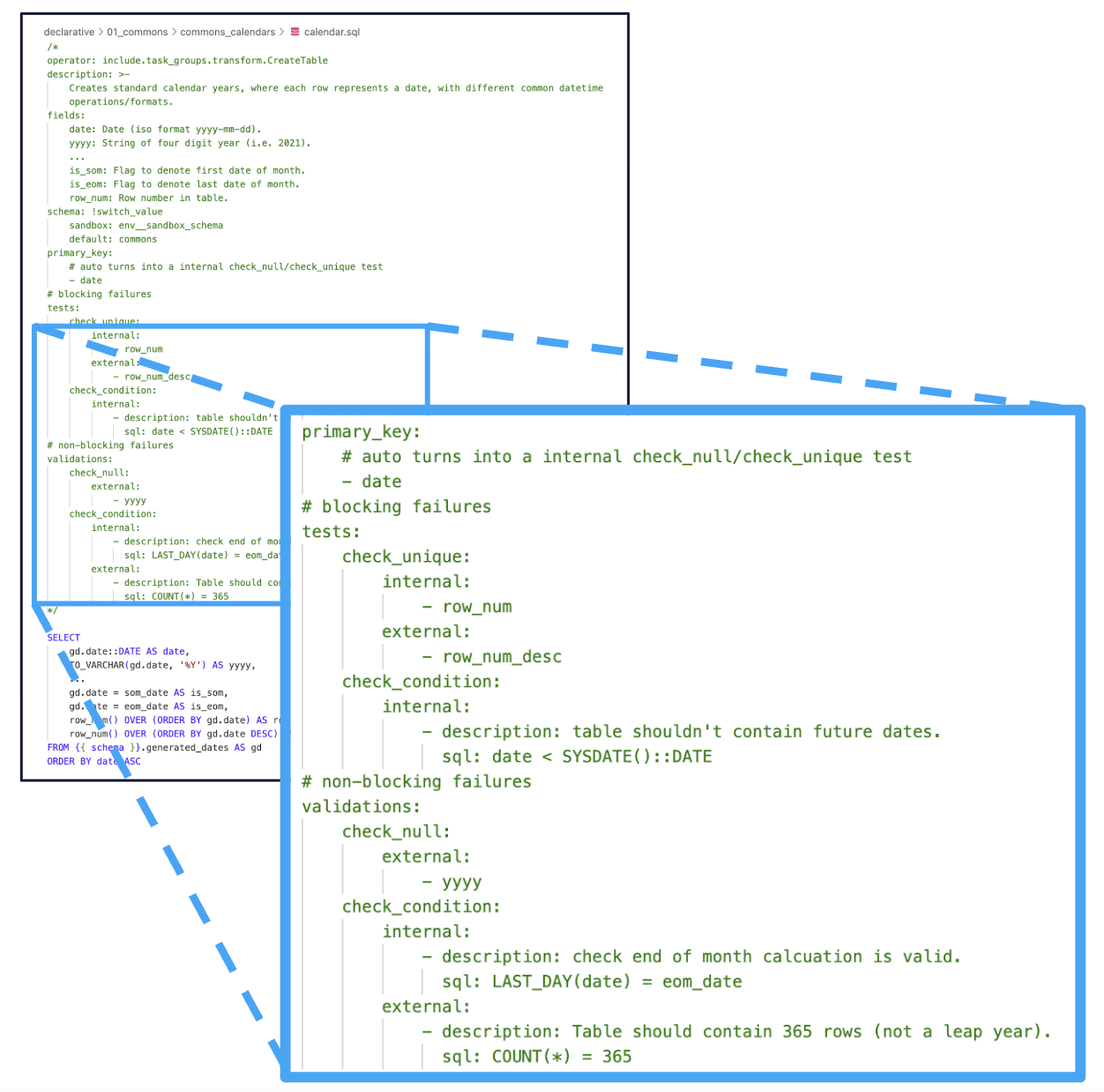
How we specify severity and ownership in our YAML frontmatter (code as configuration).
Behind the scenes, these configurations just get turned into SQL[Column/Table]CheckOperators with only a little added customization magic to log the results to our data warehouse.
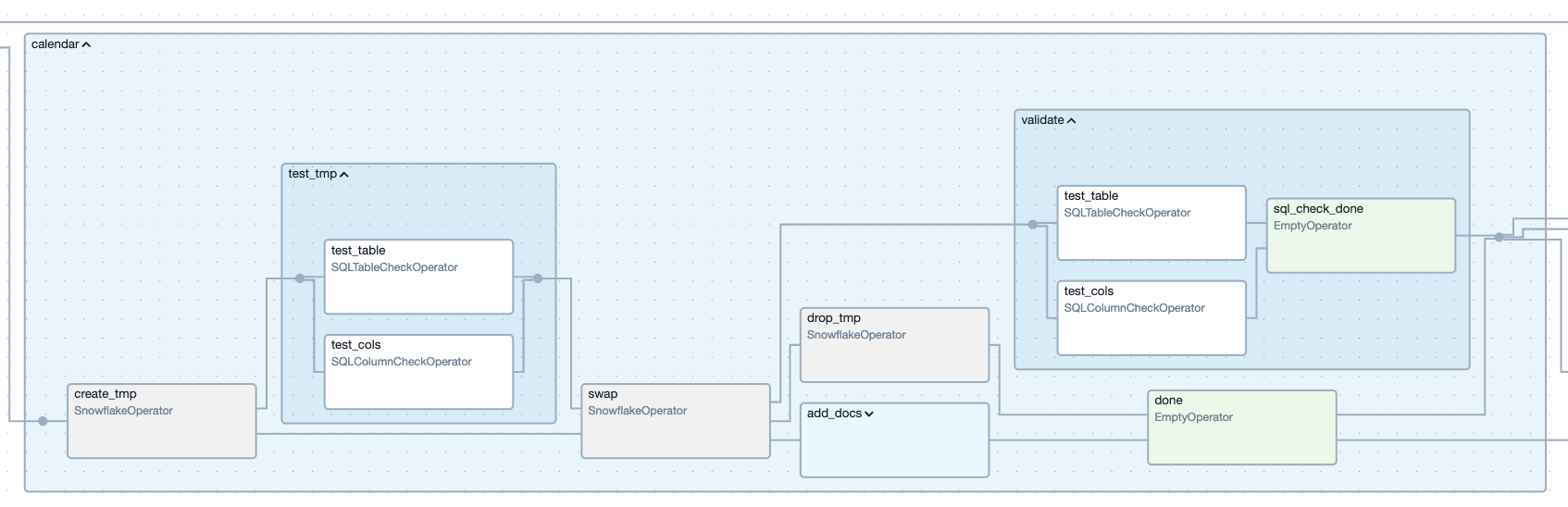 An expanded view of our CreateTable task group, generating the table `calendar`. Creating the blocking and non-blocking tasks as specified, with one or multiple checks running within one task.
An expanded view of our CreateTable task group, generating the table `calendar`. Creating the blocking and non-blocking tasks as specified, with one or multiple checks running within one task.
What’s Next?
The work is never done, now we’re thinking about:
- Can we sequester issues and self-heal data quality issues?
- Now that we’ve been collecting our testing metadata, can we quantify our data health. How can we measure and track the trustworthiness of our data over time? Are we improving? Airflow is good for point in time checking, but how does the metric I emit today compare against yesterday's?
Conclusion
Embedding testing into the developer experience intentionally prioritizes data quality. Helping teams catch issues early and build lasting trust with data consumers. Data quality isn’t a one-time project, it’s a product that needs a sense of shared responsibility and continual attention.
If you want to hear more about our approach:
- Stay tuned for future posts on our current work.OR
- Come see me speak at Airflow Summit on this very topic.
As for us, we’d love to hear how your team approaches data quality.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.