Airflow in Action: The Unified Orchestration Platform Behind OpenAI
6 min read |
OpenAI sits at the leading edge of AI innovation, but frontier models are only as strong as the data pipelines behind them. Reliable orchestration underpinning workflows as diverse as AI research and development, analytics, finance, and operations, is what keeps those models, and the business, moving forward.
At this year’s Airflow Summit, Howie Wang and Ping Zhang, Members of Technical Staff at OpenAI, explained why the company adopted an orchestration-first approach with Apache Airflow®. Their session, Scaling Airflow at OpenAI, outlined the shift from a fragmented orchestration landscape to a unified Airflow control plane. They also highlighted their reliability work shaped by real-world edge cases and the self-service tooling that keeps OpenAI engineers productive.
The Airflow Journey at OpenAI
In early 2023, OpenAI looked like many startups: every team shipped using whatever orchestration they could move fastest with. Some used Dagster, others Azure Data Factory, many just glued things together with notebooks and custom scripts. That flexibility helped ideas get off the ground, but it broke down as soon as teams tried to productionize pipelines.
There was no consistent way to version and review data pipelines, test changes, or deploy safely. That pushed the data platform team to a clear conclusion: they needed a unified orchestration layer.
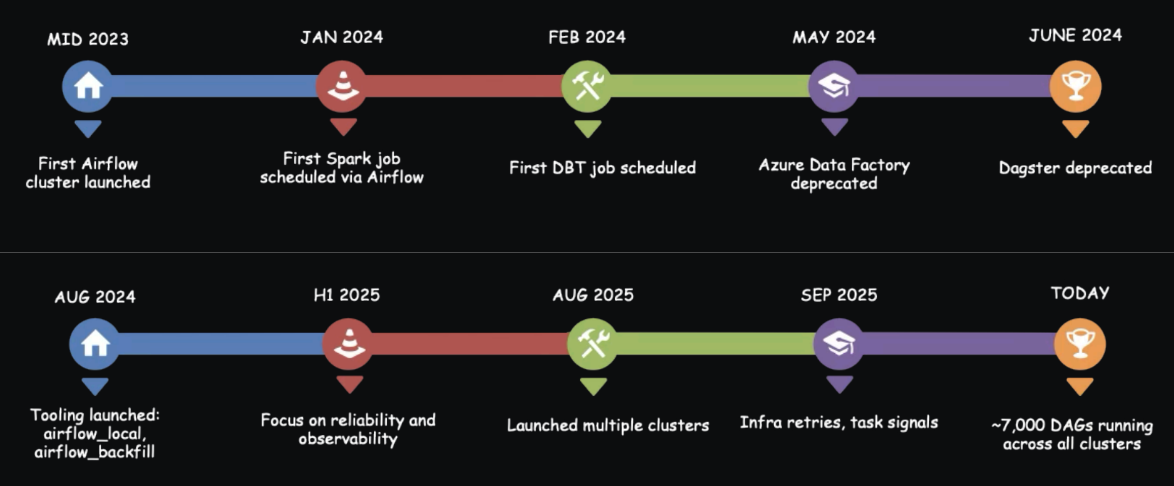
Figure 1: OpenAI’s journey to a unified orchestration platform powered by Airflow. Image source.
OpenAI standardized on Apache Airflow as that unified orchestration layer. Workflows moved into GitHub, applying software engineering best practices: pull requests, reviews, testing, and CI/CD. The first Airflow clusters landed in early–mid 2023; by early 2024 adoption had taken off. Spark jobs, dbt models, ingestion pipelines, and more all started flowing through Airflow.
Crucially, OpenAI didn’t keep this as “just another option.” In May 2024, they deprecated Azure Data Factory, and a month later they sunset Dagster as well.
“It was a pretty big milestone for us not just because we cleaned up those legacy systems but also because as a company we could align on a single orchestration layer that we knew we could invest our resources into.” Howie Wang, Member of Technical Staff, OpenAI
Standardizing on Airflow gave the team the consistent, flexible foundation they needed to scale. Today, OpenAI runs multiple Airflow clusters with ~7,000 pipelines and near-universal usage across the company. That standardization is both the value and the pressure: if Airflow stumbles, the company feels it.
Optimizing for Reliability and Scale
Once Airflow unified orchestration across OpenAI, the platform team invested to give every group a consistent, high-quality experience. The work centered on edge cases and scale::
- Reliability: the team dug into gnarly Kubernetes timing issues where pods got killed via SIGTERM at the wrong moment and tasks were marked as failed even when their work had been completed, or before any logs had been sent to the Airflow UI. They addressed this with targeted changes like PreStop hooks that directly communicate with the Airflow supervisor process to enable a graceful shutdown, automatic retries in case a task failed due to infra issues, and idempotent task keys that prevent Spark jobs unnecessarily rerunning and wasting compute.
- Scaling: IO latency and the native performance of the Azure storage account for many small files emerged as bottlenecks for the Dag processor. They reduced Dag parsing latency by syncing Dags to node-local storage. Then, as their scale grew with thousands of concurrent tasks, they hit the limits of a single cluster with the Airflow metadata database becoming the shared choke point. They called out Airflow 3’s move away from a tightly coupled database connection to an API as a major step forward in addressing future scalability challenges. In the meantime, they scaled by sharding across multiple clusters and also working to address the largest scaling constraint — access to compute capacity.
- Backfills: A new wrapper that standardizes how backfills are run, adds guardrails, and routes work to the right resource pools so users can reprocess data without coordinating with the infra team.
Editor's note: Backfills in Airflow 3 have been significantly improved. Engineers can trigger, monitor, pause, or cancel backfills from the UI or API. Large-scale reprocessing jobs run reliably without session timeouts, ensuring consistent performance even for backfills spanning months of historical data.
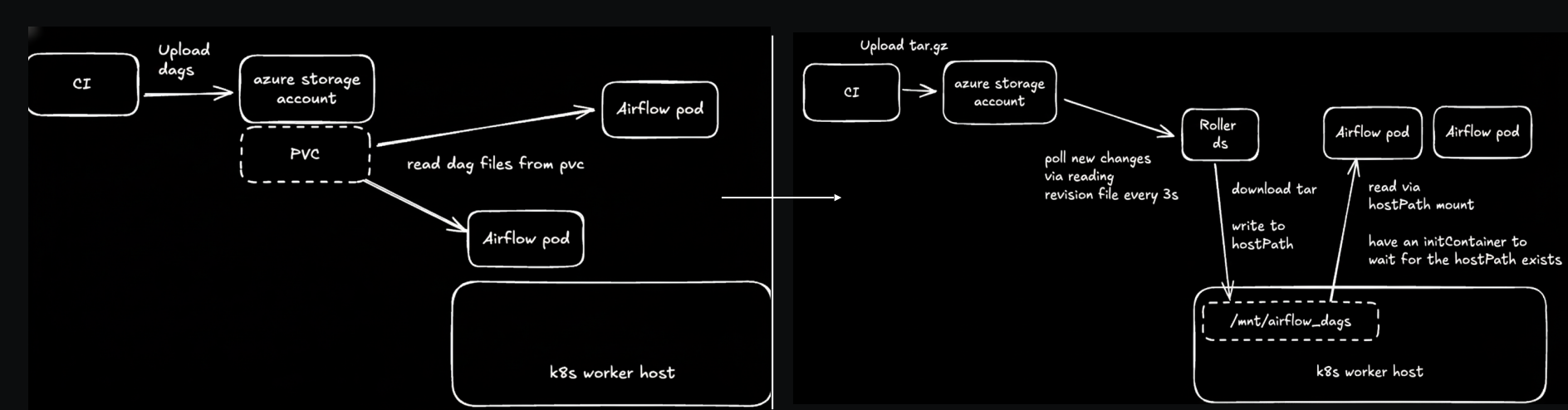
Figure 2: Solving remote-storage latency: Localizing Dag files for fast parsing and scale. Image source.
Self-Service Tooling
With no dedicated “Airflow team”, OpenAI leans heavily into self-service for their engineering teams. They built:
- A local dev CLI that lets engineers validate Dag changes end-to-end in minutes in a Kubernetes Pod, without touching production clusters.
Editor’s note: As an alternative to building your own CLI, engineers using the open source Astro CLI can run Airflow on their local machines in minutes, parse, debug, and test Dags in a dedicated testing environment and manage resources on Astro.
- A Slack bot that pulls status, logs, metadata, and runbooks to give users a first-line diagnosis and only escalates to humans when needed.
- YAML-driven DAG generation for common ingestion patterns, producing consistent Airflow code at deploy time and simplifying review.
Editor’s note: Astronomer maintains the open source Dag Factory, allowing users to dynamically generate Airflow Dags from YAML. Another alternative is the Astro IDE, enabling users to create pipelines with natural language. They can author, test, and release production-ready pipelines from the browser with context-aware AI, zero local setup, and one-click deploys to Astro.
The Next Airflow Milestone: 10x More Usage
The team is is preparing for 10x more Airflow usage, and that expectation drives their roadmap:
- Further elevate reliability. Make infra incidents invisible to end users on their self-hosted Airflow environment with better system-level retries, lower control-plane latency, and operational metrics that prove they’re moving in the right direction.
- Scaling both single clusters and multi-cluster. Enable a single cluster to host more Dags while also building better tooling to manage multiple clusters as one logical platform.
- Lowering the learning curve. Make it obvious when failures are due to capacity vs. code, keep local runs fast, make backfills simple, and keep documentation current. This is not just for humans, but for the chatbot that helps support them.
- Closing the feedback loop. Use Slack conversations as training data for the bot, turning real-world questions and answers into a flywheel that improves support quality over time.
Editor’s note: For teams that want these capabilities without building them from scratch, Astro, the fully managed Airflow service from Astronomer, delivers many of these reliability, scaling, and developer-experience improvements out-of-the-box.
Learn More
OpenAI’s lesson is clear. A unified Airflow platform has become critical infrastructure, giving teams a flexible, consistent base to ship innovation faster.
👉 To see the architecture, enhancements, and tooling patterns in depth, watch the full Scaling Airflow at OpenAI session replay.
If you’re building AI-driven applications, download our eBook “Orchestrate LLMs and Agents with Apache Airflow®” for actionable patterns and code examples on how to scale AI pipelines, event-driven inference, multi-agent workflows, and more.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.