Airflow in Action: Powering Investigative Journalism at the FT with Orchestration and AI
4 min read |
In their Airflow Summit session Breaking News with Data Pipelines, Zdravko Hvarlingov, Senior Data Engineer and Ivan Nikolov, Senior Software Engineer at the Financial Times (FT) showed how Apache Airflow® powers AI-assisted investigative journalism at scale. Attendees learned how the FT’s Storyfinding team uses Airflow to structure messy public data, apply machine learning and RAG (Retrieval Augmented Generation) techniques, and surface stories that would otherwise remain hidden.
Storyfinding at Scale
The Financial Times employs more than 700 journalists worldwide, producing reporting that increasingly depends on large, complex datasets. In 2025 alone, the US government published over 300,000 datasets spanning PDFs, tables, and free-form text. To make this information usable, the FT created the Storyfinding team, a group of engineers working directly with journalists to turn messy, unstructured data stored in a variety of modalities into actionable insights.
Their mission is demanding: bring structure to chaotic datasets, connect entities across sources, and apply modern ML techniques to increase discoverability. Airflow sits at the center of this work, orchestrating pipelines that combine traditional data processing with machine learning and AI.
Figure 1: The FT Storyfinding team builds Airflow-orchestrated AI pipelines that turn messy public data into structured, searchable insights journalists use to uncover and report stories faster. Image source.
In their talk, Zdravko and Ivan provided three use cases from the world of investigative journalism, demonstrating how they use Airflow to make data actionable.
Use Case 1: Uncovering UK Politicians Financial Interests
The first use case focused on the UK Register of Members’ Financial Interests. The dataset consists of hundreds of pages of semi-structured PDF reports published every few weeks. Manually processing this data took weeks and made aggregation nearly impossible.
The goal was to fully structure the data, deduplicate entries, enrich it, and make it easy for reporters to explore. Airflow orchestrates the entire pipeline, from scraping new PDFs to parsing their internal structure. The team extracts MPs (Member of Parliament), categories, and financial data using deterministic rules, then applies ML for entity extraction, fuzzy matching, and classification of financial amounts.
A major challenge was running ML workloads inside Airflow on Kubernetes. Large model packages and snapshots were too heavy for shared environments. The team solved this by using custom Docker images executed via the KubernetesPodOperator, with models preloaded. This preserved isolation, performance, and repeatability.
Once structured, the UK data was linked to other sources like Companies House. Airflow coordinates these joins to reveal relationships between people, companies, and financial flows. These connection analysis pipelines are critical for investigative reporting, exposing ownership structures and networks that would be invisible in isolation. Outputs are delivered as structured CSVs to Google Drive so non-technical journalists can work directly with the data.
The result enabled investigations such as uncovering thousands of pounds in gifts received by senior UK politicians.
Use Case 2: SEC Filings and RAG for Trend Discovery
The second use case tackled US SEC filings, including long and complex 10-K documents. The problem was scale and discoverability. Journalists needed to spot trends across companies and industries without reading hundreds of pages.
Airflow orchestrates parsing, sectioning, chunking, and embedding generation. The team applies RAG techniques by splitting documents into overlapping, linguistically correct chunks, generating embeddings via shared FT APIs, and storing them for retrieval.
Large spaCy NLP models run outside Airflow on dedicated hardware, while Airflow manages coordination and backfills. This enables fast querying through a lightweight Streamlit interface and supports stories spanning years of filings.
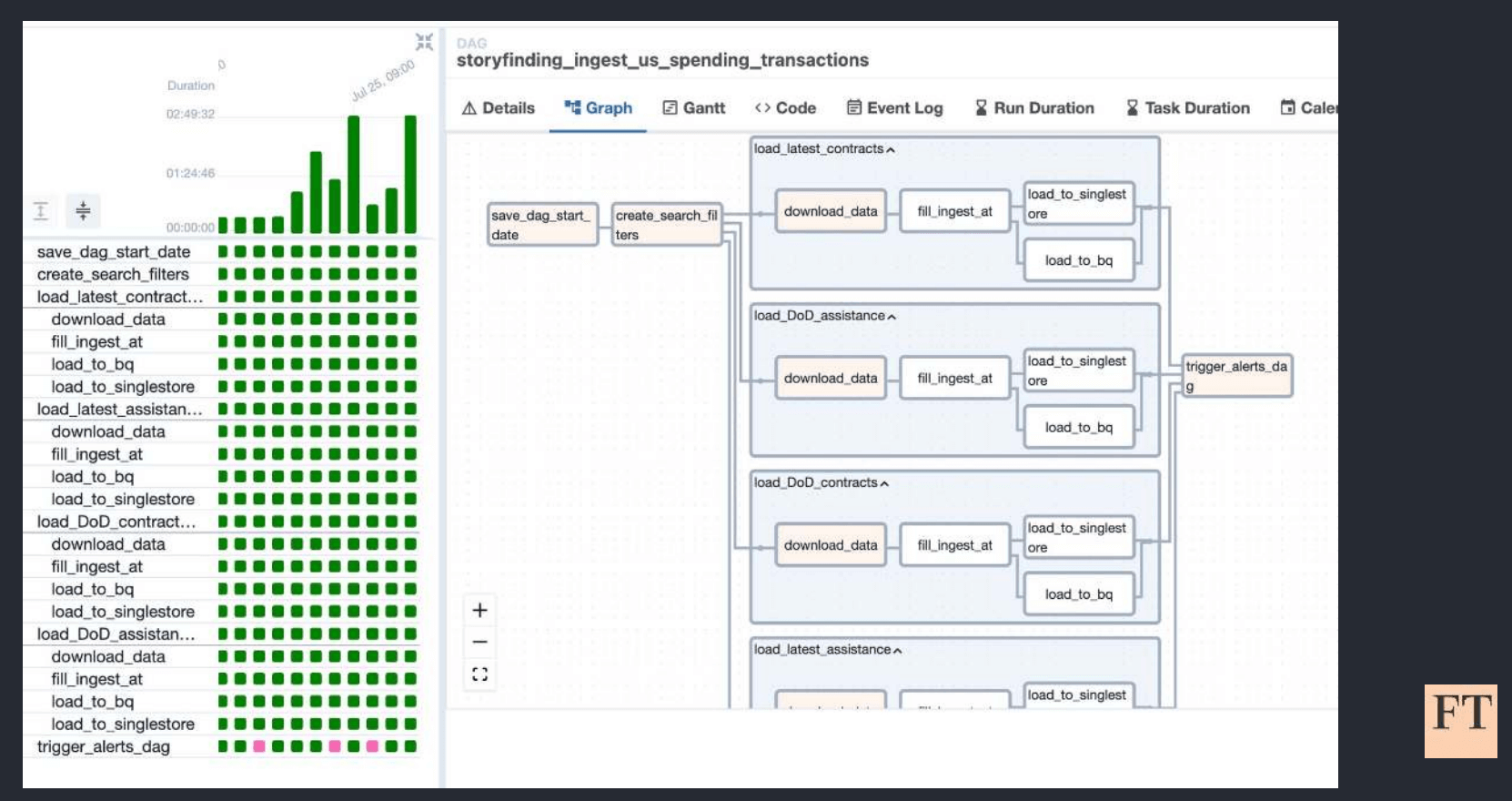
Figure 2: The data collection and ingestion pipeline used to track US government transactions. Image source.
Use Case 3: Monitoring US Government Spending
The final use case focused on US federal spending data. Here the goal was not deep structuring, but timely notification.
Airflow orchestrates incremental ingestion and a notification pipeline driven by reporter-defined configurations stored in Google Sheets. When new transactions appear for entities of interest, Airflow generates targeted exports and sends alerts only when something meaningful changes. This supports stories like uncovering sharp cuts in government consulting spend.
Why Airflow Matters: Making Messy Data Reportable at Scale
Across all use cases, Airflow provides a reliable control plane for complex, evolving workflows. It enables experimentation, repeatability, and resilience as data sources and structures change. Most importantly, it lets engineers and journalists collaborate at speed. To see these pipelines in action and hear the full technical detail, watch the replay of the Financial Times session from the Airflow Summit.
To get started with RAG and LLMs in your data workflows, take the no cost Orchestrating Workflows for GenAI Applications from DeepLearning.AI and Astronomer. The fastest way you can get started with Airflow is to try it out on Astro, the leading managed Airflow service.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.